Difference between PostgreSQL and MySQL: (1) Replication
Many people around the world admire the Uber’s article “Why Uber Engineering Switched from Postgres to MySQL”, but I think this article contains many mistakes. So, I’m going to provide correct information regarding to PostgreSQL and MySQL.
In this post, I explain the replication of both databases.
Features
PostgreSQL
- Single-master multi-slaves model
- Transaction Log shipping based
- Synchronous and asynchronous modes supported
- Replicating all databases
The detail of the PostgreSQL replication is described in my article. Simply put, PostgreSQL’s replication is based on transaction log shipping, in which a master server continues to send transaction log and then, each slave server replays the received log immediately.
The transaction log shipping may be caused when any one of the following occurs:
- One running transaction has committed or has aborted.
- The WAL buffer (transaction log buffer) has been filled up with many tuples have been written.
- A WAL writer process writes periodically. default is 200 milliseconds.
If you execute a query that modifies a few rows, transaction logs (WAL data) are send when the query has committed.
On the other hand, if you execute a query that modifies a huge number of rows, transaction logs are send periodically. For example, we suppose that a UPDATE command that updates one million rows and it takes a few minutes to finish. While the master are updating a table, WAL data are also sending to the slave; the slave is replaying the received WAL data. Therefore, the transactions of both master and the slave are committed at the almost same time (regardless of whether the synchronous mode or the asynchronous mode).
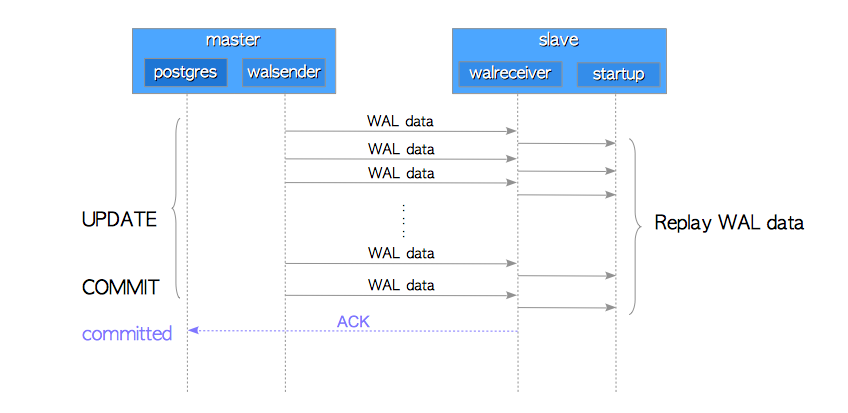
Basically, PostgreSQL’s streaming replication replicates all databases. PostgreSQL version 9.4 or later can replicate the databases and tables you select by using logical decoding and replication slot.
MySQL
- Single-master multi-slaves model
- Logical-log (SQL commands) shipping based
- Semi-Synchronous and asynchronous modes supported
- Replicating all databases or selected databases/tables
MySQL’s replication is also single-master multi-slaves model. In Addition, MySQL 5.7 supports multi-source replication (note that this is not a multi-master replication).
MySQL’s replication is based on Logical-log (SQL commands) shipping; the log used for replication is called the binary log. There are three logging formats: statement-based logging, row-based logging, and mixed logging. These logging formats have advantages and disadvantages. (Mixed-logging have not been recommended.)
The statement-based logging (SBL) records the executed SQL commands as shown below:
mysql$ mysqlbinlog mysql-bin.000001
... snip ...
BEGIN
#140327 3:30:55 server id 2 end_log_pos 631 Query ...
INSERT INTO tbl1 VALUES(2)
#140327 3:30:55 server id 2 end_log_pos 658 Xid = 18
COMMIT/*!*/;
... snip ...
The row-based logging (RBL) records the modified rows as shown below:
... snip ...
#795 server id 1 end_log_pos 155 Table_map: `sampledb`.`test` ..
#795 server id 1 end_log_pos 194 Write_rows: table id 15 flags: STMT_END_F
BINLOG '
jl7eRhMBAAAAMQAAAJsAAAAAAA8AAAAAAAAACHNhbXBsZWRiAAR0ZXN0AAID/AECAw==
jl7eRhcBAAAAJwAAAMIAAAAQAA8AAAAAAAEAAv/8AwAAAAMAY2Nj
'/*!*/;
#795 server id 1 end_log_pos 243 Table_map: `sampledb`.`test` ..
#795 server id 1 end_log_pos 282 Write_rows: table id 15 flags: STMT_END_F
BINLOG '
ll7eRhMBAAAAMQAAAPMAAAAAAA8AAAAAAAAACHNhbXBsZWRiAAR0ZXN0AAID/AECAw==
ll7eRhcBAAAAJwAAABoBAAAQAA8AAAAAAAEAAv/8BAAAAAMAZGRk
'/*!*/;
... snip ...
The binary log shipping is caused whenever a transaction commits when using InnoDB; when using MyISAM, the log is send whenever a SQL command is finished. (Because a sequence of SQL commands within the binary log must be serializable.)
The figure below is shown how MySQL’s replication works. The binlog_dump thread of the master sends binary log whenever a transaction commits; the I/O thread of the slave receives the log and the SQL thread executes the received SQL command when using SBL. (When using RBL, the SQL thread modifies rows.)
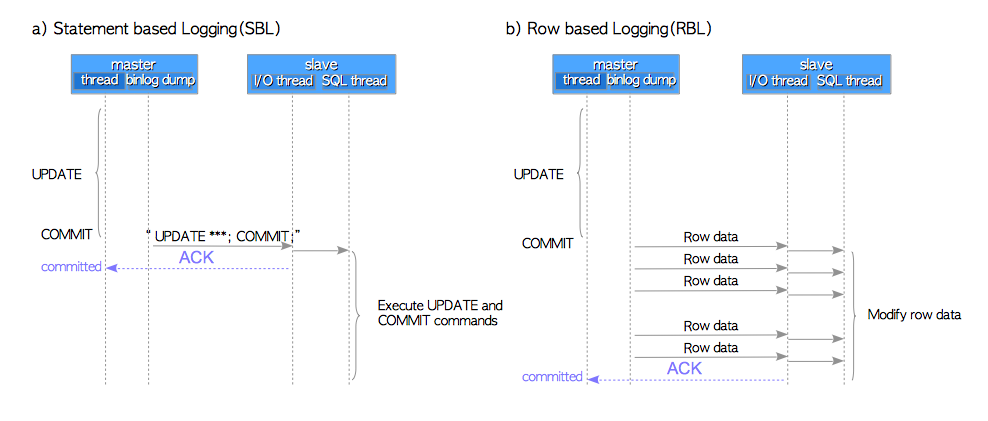
Please note that the slave does not work while the master is updating a table. How do you think about this behavior? You could easily count the disadvantages caused by this behavior. For example, just after updating a large number of rows, access to a slave should be avoided.
Comments for the Uber’s article
The Uber’s article is a pack of lies. Fortunately, this article “On Uber’s Choice of Databases” has already pointed out what I’d like to say.
I add just two things:
- When using RBL, mysql generates a huge replication traffic. On the other hand, when using SBL, there are also some disadvantages.
- If a MySQL user want to read data from the slave just after updating or inserting a huge number of rows on the master, the user have to confirm whether the slave has been committed, in order to read consistent data (even if using semi-synchronous mode & SBL).