この文書は、書籍で割愛したものです。
pgpool レプリケーションモード
レプリケーションモードで運用するための設定方法、 およびオンラインリカバリの方法を説明する。
ここでPostgreSQLは3重化し、2台故障まで障害を(静的)マスクする。
また、(動的)マスクながらオンラインリカバリで故障ノードを復旧できる。
設定
pgpool-IIの設定ファイルpgpool.confの設定方法と、 PostgreSQLの準備の概要を示す。
pgpool.confの設定
pgpool-IIについて、レプリケーションモードの設定を行う。 以下に例を示す。
[<レプリケーションモード:pgpool.confの抜粋>]1: listen_addresses = '*' 2: port = 5432 3: pcp_port = 9898 4: 5: # - Backend Connection Settings - 6: backend_hostname0 = '192.168.0.10' 7: backend_port0 = 5432 8: backend_weight0 = 1 9: backend_data_directory0 = '/usr/local/pgsql/data' 10: backend_flag0 = 'ALLOW_TO_FAILOVER' 11: 12: backend_hostname1 = '192.168.0.11' 13: backend_port1 = 5432 14: backend_weight1 = 1 15: backend_data_directory1 = '/usr/local/pgsql/data' 16: backend_flag1 = 'ALLOW_TO_FAILOVER' 17: 18: backend_hostname2 = '192.168.0.12' 19: backend_port2 = 5432 20: backend_weight2 = 1 21: backend_data_directory2 = '/usr/local/pgsql/data' 22: backend_flag2 = 'ALLOW_TO_FAILOVER' 23: 24: # - Authentication - 25: enable_pool_hba = on 26: 27: # -- REPLICATION MODE 28: replication_mode = on 29: replication_stop_on_mismatch = on 30: failover_if_affected_tuples_mismatch = on 31: 32: # -- LOAD BALANCING MODE 33: load_balance_mode = on 34: 35: # -- ONLINE RECOVERY 36: recovery_user = 'postgres' 37: recovery_password = '' 38: recovery_1st_stage_command = 'recovery_1st_stage.sh' 39: recovery_2nd_stage_command = 'recovery_2nd_stage.sh' 40: recovery_timeout = 600
- 1行目〜3行目: 外部からのアクセスを制御する
- listen_addresses
- port
- pcp_port
- 5行目〜22行目: 接続するノードの情報
- backend_hostname0、backend_port0
- backend_weight0
- backend_data_directory0
- backend_flag0 = 'ALLOW_TO_FAILOVER'
- 25行目: pg_ha.confでアクセス制御するか否か
- 27行目〜30行目: レプリケーションモードの設定
- replication_mode = on
- replication_stop_on_mismatch
- failover_if_affected_tuples_mismatch
- 33行目: 負荷分散モードで稼働するか否か
- 35行目〜40行目: オンラインリカバリの設定
- recovery_user、recovery_password
- recovery_1st_stage_command、recovery_2nd_stage_command
- recovery_timeout
PostgreSQLのlisten_addressesと同じ。
外部からpgpool-IIにアクセスするポート番号。ここではPostgreSQLとおなじ5432を設定する。
pgpool-IIを制御するコマンドが接続するポート番号。
node0のIPアドレスとポート番号。
負荷分散アクセスにおける各ノード間の重み付け。
node0のPostgreSQLのベースディレクトリ。
このノードの故障を検出したら、pgpool-IIが自律的にこのノードを切り離す(フェールオーバする)。
node1、node2についても同様。
レプリケーションモードを有効にする。
SQLを全ノードに送り、あるノードからは成功、別のノードからは失敗と、異なるレスポンスが返った場合にフェールオーバするか否か。
例えばノード間でデータ不一致があり、あるノードにテーブルtblが存在しないとする。
このテーブルに対してUPDATEやDELETEを実行するとノードによって成功を返すものと失敗を返すものがある。
replication_stop_on_mismatchが有効(on)なら、多数決で少数派のノードを切り離す。
UPDATEやINSERTを全ノードに送り、レスポンスの更新数や挿入数が異なる場合にフェールオーバするか否か。
例えばあるテーブルtblのデータ数が異なっているとする。
このテーブルに対してUPDATEを実行すると、ノード毎に返す更新数が異なる。
failover_if_affected_tuples_mismatchが有効(on)なら、多数決で少数派のノードを切り離す。
オンラインリカバリを実行するユーザ名とパスワード。
オンラインリカバリを実行するシェルスクリプト名を記述する。詳細は後述。
オンラインリカバリのタイムアウトを設定する。オンラインリカバリが終了するに十分な時間を設定すること。
PostgreSQL
レプリケーションモードでpgpool-IIを運用する場合、 3台のPostgreSQLのデータが同期していなければならない。
オンラインリカバリを行う場合は、さらに次の設定が必要である。
- アーカイブログ機能
- オンラインリカバリ用スクリプト
ディレクトリ/home/postgres/archivelogsにアーカイブログを保存する。
次の3つのスクリプトをベースディレクトリに配置する。詳細は後述する。
・recovery_1st_stage.sh ・recovery_2nd_stage.sh ・pgpool_remote_start
pgpool-IIの起動/停止と管理コマンド
-nオプション付きでバックグランドで起動するのが、最も簡単である。
ログの書き込みなどはpgpoolのドキュメントを参照。
停止はstopオプションでpgpoolコマンドを実行する。
postgres@pgpool> pgpool -n & postgres@pgpool> pgpool stop
pgpool-IIの管理は[<表5-XX>]に示す一連の管理コマンドで行う。
| コマンド | 説明 |
|---|---|
| pcp_node_count | 接続しているノード数を返す |
| pcp_proc_count | プロセス一覧を返す |
| pcp_node_info | 指定したノードの情報を返す |
| pcp_proc_info | 指定したノードに関わるプロセス情報を返す |
| pcp_attach_node | (フェールオーバなどによって切り離されたノードを)復帰させる |
| pcp_detach_node | 明示的にノードを切り離す |
| pcp_recovery_node | オンラインリカバリを実行する |
これら管理コマンドは独特のオプション体系を持っている。
以下、いくつかのコマンドについて説明する。
pcp_node_count、pcp_proc_count
[< pcp_node_countの使い方>]Usage: pcp_node_count timeout hostname port# username password timeout - connection timeout value in seconds. command exits on timeout hostname - pgpool-II hostname port# - pgpool-II port number username - username for PCP authentication password - password for PCP authentication -h - print this help
タイムアウトtimeoutは適当な時間を設定してよい。
port番号は9898を指定する。
ユーザ名とパスワードは[<5-06>]のpcp.confファイルに設定した値を使う(本書ではユーザ名"pgpool2"、パスワード"pass-pgpool2")。
サーバpgpool上でpcp_node_countを実行した結果を示す。3台のPostgreSQLサーバが接続していることがわかる。
postgres@pgpool> pcp_node_count 10 localhost 9898 pgpool2 pass-pgpool2 3
pcp_node_info
[< pcp_node_infoの使い方>]Usage: pcp_node_info timeout hostname port# username password nodeID timeout - connection timeout value in seconds. command exits on timeout hostname - pgpool-II hostname port# - pgpool-II port number username - username for PCP authentication password - password for PCP authentication nodeID - ID of a node to get information for
pcp_node_infoのオプションはpcp_node_countとほぼ同じで、最後にnodeIDを設定する点のみ異なる。
pcp_node_infoの出力を[<表5-XX>]に示す。 重要なのは第3項目の"状態[<表5-XX>]"である。
| 項目 | 説明 |
|---|---|
| IPaddr | ノードのアドレス |
| port | ノードのport番号 |
| status | 状態[<表5-XX>]参照) |
| weight | 重み(pgpool.confのbackend_weight0など参照) |
| 状態 | 説明 | 状態 | 説明 |
|---|---|---|---|
| 1 | 正常接続 | 4 | エラー |
| 2 | アイドル状態 | 5 | フェイタルエラー |
| 3 | 切断 | 6 | デッドロック |
node0の情報を表示する。
状態は2、つまりアイドルだが正常な状態である。状態が1か2ならば問題ない。
postgres@pgpool> pcp_node_info 10 localhost 9898 pgpool2 pass-pgpool2 0 192.168.0.10 5432 2 0.333333
ここで、node2を緊急停止する(immediateモードで停止)。
この状態でpcp_node_infoを実行すると、node2の状態が3で、切断されていることが判る。
postgres@pgpool> pcp_node_info 100 localhost 9898 pgpool2 pass-pgpool2 2 192.168.0.12 5432 3 0.333333
pcp_detach_node, pcp_attach_node
停止したノードを切り離すにはpcp_detach_nodeコマンド、
ノードを接続するにはpcp_attach_nodeコマンドを使う。
コマンド実行時の引数はpcp_node_infoコマンドと同じである。
pcp_detach_nodeでnode2を切り離す。
postgres@pgpool> pcp_detach_node 10 localhost 9898 pgpool2 pass-pgpool2 2
オンラインリカバリの準備
オンラインリカバリは、recovery_1st_stage.sh、recovery_2nd_stage.sh、pgpool_remote_startという3つのスクリプトファイルが連携して行う。
はじめにこれらのスクリプトがどのような働きをするか、時系列で示す([<図5-XX>]参照)。
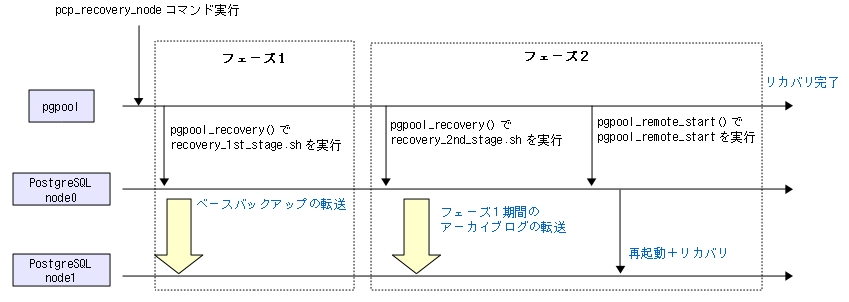 |
ここでは、サーバnode0からサーバnode1(リカバリ先)をリカバリすると仮定する。
pcp_recovery_nodeコマンド実行すると、オンラインリカバリが始まる。
- フェーズ1
- フェーズ2
pgpool-IIがサーバnode0に対して関数pgpool_recovery()を介してrecvery_1st_stage.shを実行する([<コラム1>]参照)。
recvery_1st_stage.shの主な仕事は、ベースバックアップをリカバリするサーバに転送することである。
本書ではrsyncのsshモードで転送している。
フェーズ1が終わると、全接続が切断されるのを待ってフェーズ2に入る。
recovery_2nd_stage.shとpgpool_remote_startを実行する。
recovery_2nd_stage.shは、サーバnode0でpg_switch_xlog()関数を実行して最新のアーカイブログを書き出し、 そのアーカイブログをrsyncのsshモードで転送する。
これでサーバnode1を再起動する準備が整ったので、
pgpool-IIはサーバnode0にpgpool_remote_start()関数を実行させる。
ここでpgpool_remote_start()関数も、先のインストールで登録された関数である。
pgpool_remote_start()関数はシェルスクリプトpgpool_remote_startを実行する関数で、 pgpool_remote_startの中身は、リカバリするサーバ上のPostgreSQLを起動するコマンドだけが書かれている。
コラム1:pgpool_recovery関数 ここでpgpool_recovery()関数は、pgpool-IIインストール時に設定したライブラリpgpool-recovery.soと バッチファイルpgpool-recovery.sqlによってPostgreSQLに登録された関数で、 ベースディレクトリにあるシェルスクリプトを実行する。
スクリプト
オンラインリカバリのためのシェルスクリプトrecovery_1st_stage.sh、recovery_2nd_stage.sh、pgpool_remote_startを示す。
[< recovery_1st_stage.sh>]
#! /bin/bash
PSQL=/usr/local/pgsql/bin/psql
MASTER_BASEDIR=$1
RECOVERY_HOST=$2
RECOVERY_BASEDIR=$3
# ベースバックアップの開始
$PSQL -c "SELECT pg_start_backup('pgpool-recovery')" postgres
# リカバリ先用のrecovry.confファイル生成
echo "restore_command = 'cp /home/postgres/archivelogs/%f %p'" > \
$MASTER_BASEDIR/recovery.conf
# リカバリ先のデータベースクラスタを念のためにバックアップ
ssh -l postgres -T $RECOVERY_HOST rm -rf $RECOVERY_BASEDIR.bk
ssh -l postgres -T $RECOVERY_HOST mv -f $RECOVERY_BASEDIR{,.bk}
# データベースクラスタ=ベースバックアップをリカバリ先に転送
rsync -az -e ssh -l postgres $MASTER_BASEDIR/ \
$RECOVERY_HOST:$RECOVERY_BASEDIR/
ssh -l postgres -T $RECOVERY_HOST cp -f \
$RECOVERY_BASEDIR.bk/postgresql.conf $RECOVERY_BASEDIR
ssh -l postgres -T $RECOVERY_HOST rm -f \
$RECOVERY_BASEDIR/postmaster.pid
# リカバリ先に転送したので、不要になったrecovery.confを削除
rm -f $MASTER_BASEDIR/recovery.conf
# ベースバックアップの終了
$PSQL -c "SELECT pg_stop_backup()" postgres
exit 0
[< recovery_2nd_stage.sh>]
#! /bin/bash PSQL=/usr/local/pgsql/bin/psql ARCHIVEDIR=/home/postgres/archivelogs/ MASTER_BASEDIR=$1 RECOVERY_HOST=$2 RECOVERY_BASEDIR=$3 # 最新のアーカイブログを保存 $PSQL -c 'SELECT pg_switch_xlog()' postgres # 最新のアーカイブログをリカバリ先に転送 rsync -az -e ssh -l postgres $ARCHIVEDIR $RECOVERY_HOST:$ARCHIVEDIR exit 0[< pgpool_remote_start>]
#! /bin/sh PGCTL=/usr/local/pgsql/bin/pg_ctl RECOVERY_HOST=$1 RECOVERY_BASEDIR=$2 # リカバリ先のPostgreSQLを起動 ssh -l postgres -T $RECOVERY_HOST $PGCTL -w -D $RECOVERY_BASEDIR start \ 2>/dev/null 1> /dev/null < /dev/null &
サーバnode0、node1、node2のベースディレクトリ(ここでは/usr/local/pgsql/data)に、 これらのシェルスクリプトを置き、パーミッションを実行可能にする。
postgres@> cd /usr/local/pgsql/data postgres@> chmod +x recovery_1st_stage.sh postgres@> chmod +x recovery_2nd_stage.sh postgres@> chmod +x pgpool_remote_start
オンラインリカバリの実行
手動でpcp_recovery_nodeコマンドを実行する。
引数はpcp_node_infoコマンドと同じである。
ここでは、node1をオンラインリカバリする。
postgres@pgpool> pcp_recovery_node 100 localhost 9898 pgpool2 pass-pgpool2 1
リカバリ中にエラーが発生すれば、エラーメッセージが出る。
オンラインリカバリが終了したら、pcp_attach_nodeコマンドでnode1を接続する。
postgres@pgpool> pcp_attach_node 100 localhost 9898 pgpool2 pass-pgpool2 1
正常に接続されたかどうかは、pcp_node_infoで確認できる。