この文書は、書籍で割愛したものです。
pgpool マスタスレーブモード
マスタスレーブモードで運用するための設定方法を説明する。
ここでは3台構成で1台故障まで故障をマスクするシステムを構築する。
マスタスレーブモードは、PostgreSQLのレプリケーションのフロントエンドとして機能する。 よって耐障害性を確保するには、次の2つの機能が必要である。
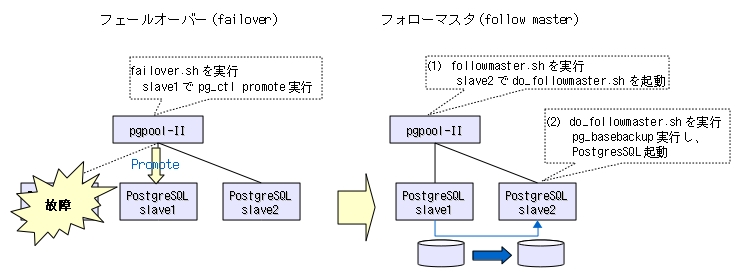
- フェールオーバー
- フォローマスタ
マスタ故障を検出したら、スレーブを昇格(promote)させる。
スレーブを、新しいマスタに再接続する。 2台以上のスレーブを準備した場合に必須となる。
 |
なお、オンラインリカバリは手順が非常に複雑になるので、筆者は推奨しない。 システムを停止して再構築することを推める。
以下、設定方法を示す。
pgpool.confの設定
pgpool-IIについて、マスタスレーブモードの設定を行う。
以下に例を示す。
なお、26行目までは[<5-07>]のレプリケーションモードのpgpool.confと同じなので省略する。
1 〜 26行目までは[<5-07>]のレプリケーションモードのpgpool.confと同じ 27: # MASTER/SLAVE MODE 28: master_slave_mode = on 29: master_slave_sub_mode = 'stream' 30: sr_check_user = 'postgres' 31: sr_check_password = '' 32: delay_threshold = 0 33: 34: # - Special commands - 35: follow_master_command = '/usr/local/pgpool2/followmaster.sh %h %d %H %M %P' 36: 37:# FAILOVER AND FAILBACK 38:failover_command = '/usr/local/pgpool2/failover.sh %d %H' 39: 40:# -- LOAD BALANCING MODE 41:load_balance_mode = on
- 1行目〜26行目
- 27行目〜32行目: マスタスレーブモードの設定
- master_slave_mode、master_slave_sub_mode
- sr_check_user、sr_check_password、delay_threadhold
- 35行目: フォローマスタ
- follow_master_command
- 38行目: フェールオーバ
- failover_command
[<5-07>]のレプリケーションモードのpgpool.confと同じ。
マスタスレーブモードの設定。sub_modeはレプリケーションの種別を設定。現時点ではStreamingReplicationかSlony-Iのどちらかを設定する(本書は"stream")。
遅延チェックを行うユーザ名、そのパスワードと遅延許容時間を設定する。
フォローマスタを実行するスクリプト名を設定する。引数も設定できる。
%hはそのスクリプトを実行するホスト名、
%dはそのホストのノード番号(node0,node1など)、
%Hは新しいマスタのホスト名。
フェールオーバを実行するスクリプト名を設定する。引数も設定できる(上記follow_master_commandの説明参照)。
フェールオーバの準備
pgpool-II
pgpoolサーバに、フェールオーバを実行するスクリプトfailover.shを配置する。
postgres@pgpool> chmod +x /usr/local/pgpool2/failover.sh
postgres@pgpool> cat /usr/local/pgpool2/failover.sh
#!/bin/sh
PGCTL=/usr/local/pgsql/bin/pg_ctl
BASEDIR=/usr/local/pgsql/data
failed_node=$1
new_master=$2
if [ $failed_node != 0 ]; then
exit 0
fi
# サーバpgpoolから新しいマスタ(slave1)にsshでpromoteを実行する
ssh -l postgres -T $new_master $PGCTL -D $BASEDIR promote
exit 0
また、サーバpgpoolから新しいマスタになるノード(slave1)へ、 パスフレーズなしでssh実行できるように準備しておく。
PostgreSQL : slave1
slave1はマスタのフェールオーバ後、新たにマスタになる。 なので予めpostgresql.confのsynchronous_standby_namesに、スレーブslave2を設定しておく。
# slave1のpostgresql.conf # フェールオーバ後、同期レプリケーションするために、 # 予めスレーブslave2を設定しておく。 synchronous_standby_names = 'slave2'
フォローマスタの準備
フォローマスタの準備は少々複雑である。
pgpool-II
サーバpgpoolにフォローマスタを起動するスクリプトfollow_master.shを配置する。
このスクリプトは、マスタに再接続するslave2で別のスクリプト(do_followmaster.sh)を起動する。
いわばフォローマスタ処理のマスタスイッチのようなものである。
postgres@pgpool> cat /usr/local/pgpool2/follow_master.sh
#!/bin/sh
hostname=$1
hostnode=$2
newmaster=$3
# node2 = slave2でのみ、実行する。
if [ $hostnode != 2 ]; then
exit 0
fi
# node2でdo_followmaster.shを実行する。
ssh -l postgres \
-T $hostname /usr/local/pgsql/bin/do_followmaster.sh $newmaster
exit 0
PostgreSQL : slave2
マスタのフェールオーバー後、新マスタ(slave1)にslave2を再接続するための準備を示す。
- 再接続用の設定ファイルを準備
適当なディレクトリに、再接続で使う設定ファイル(postgresql.conf、pg_ha.conf、recovery.conf)を用意する。
- do_followmaster.shファイルを配置
slave2に、新マスタ(slave1)にslave2を再接続手続きを記述したスクリプトファイルdo_followmaser.shを配置する。 詳細は後述。
再接続用の設定ファイルについて説明する。
pg_basebackupコマンドを使うと、slave1のpostgresql.confとpg_ha.confもコピーしてしまうので、
slave2用の設定ファイルを保存しておき、
予め
フォローマスタ後に利用するrecovery.confを準備し、
接続先をslave1に設定しておく。
postgres@slave2> mkdir -p /usr/local/pgsql/tmp postgres@slave2> cd /usr/local/pgsql/tmp postgres@slave2> ls -1 recovery.conf pg_ha.conf postgresql.conf postgres@slave2> diff ../data/recovery.conf recovery.conf 115c115 < primary_conninfo = 'host=master port=5432 application_name=slave2' --- > primary_conninfo = 'host=slave1 port=5432 application_name=slave2'
最後に実際のフォローマスタ処理を行うdo_followmaster.shを配置する。
フォローマスタ処理の手順は、[<5-XX>]で3パターン説明した。
ここではpg_basebackupコマンドでデータベースクラスタを再構築する方法を示す。
他の方法を利用する場合は適宜スクリプトを変更すること。
postgres@slave2> chmod +x /usr/local/pgsql/bin/do_followmaster.sh postgres@slave2> cat /usr/local/pgsql/bin/do_followmaster.sh #!/bin/sh PGCTL=/usr/local/pgsql/bin/pg_ctl PGBASEBACKUP=/usr/local/pgsql/bin/pg_basebackup BASEDIR=/usr/local/pgsql/data TMPDIR=/usr/local/pgsql/tmp newmaster=$1 # データベースクラスタは再構築するので、immediateで停止しても問題ない $PGCTL -D $BASEDIR -m immediate stop rm -rf $BASEDIR # ver9.1では、--xlogに値を設定しない $PGBASEBACKUP -h $newmaster -D $BASEDIR --xlog=stream # 再接続用の設定ファイルをベースディレクトリに配置する cp $TMPDIR/postgresql.conf $BASEDIR cp $TMPDIR/pg_ha.conf $BASEDIR cp $TMPDIR/recovery.conf $BASEDIR/recovery.conf # 再起動 $PGCTL -D $BASEDIR start exit 0
動作確認
PostgreSQLとpgpool-IIを起動する。
pcp_node_infoコマンド([<5-XX>]参照)で各ノードの状態が確認できる。
postgres@pgpool> pcp_node_count 10 localhost 9898 pgpool2 pass-pgpool2 3 postgres@pgpool> pcp_node_info 10 localhost 9898 pgpool2 pass-pgpool2 0 192.168.0.10 5432 2 0.333333 postgres@pgpool> pcp_node_info 10 localhost 9898 pgpool2 pass-pgpool2 1 192.168.0.11 5432 2 0.333333 postgres@pgpool> pcp_node_info 10 localhost 9898 pgpool2 pass-pgpool2 2 192.168.0.12 5432 2 0.333333
マスタをimmediateモードでshutdown(故障をシミュレート)すると、 フェールオーバとフォローマスタが相次いで実行されることが確認できる。
故障したノードの復旧は、pgpool-IIを停止して行えばよい。