1024倍以上グレードアップした内部構造は、 毎度おなじみ、流浪のPostgreSQL本にまとめました(今回の書名は「PostgreSQL全機能バイブル」)。
書籍以外のPostgreSQL情報はこちらを参照してください。
pgpool-IIによるレプリケーションとオンラインリカバリ
この記事は技術評論社『WEB+DB PRESS』の 『WEB+DB PRESS Vol.48』2008年12月刊 に掲載された原稿の草稿を、許可を得て公開しているものです。また、日本PostgreSQLユーザ会の仕組み分科会で発表したWALとPITRの資料とpgpool-IIのオンラインリカバリに関する資料がありますので、こちらも参照してください。
1.1 はじめに
本章では、pgpool-IIによるレプリケーションシステムの構成方法と、 オンラインリカバリの手順について解説します。1.2 pgpool-IIとは
pgpool-IIは同期レプリケーション機能をはじめ、コネクションプール機能や負荷分散機能を提供するPostgreSQL専用のミドルウエアです。pgpool-IIは、先代に当たるpgpoolの後継プロダクトとしてリリースされました。pgpool-IIの概略を把握するために、pgpoolからの開発の歴史を簡単に振り返ってみましょう(表1)。
表1 pgpoolの歴史
プロダクト バージョン リリース時期 主な追加機能 pgpool ver1 2004.4 コネクションプール機能、(2台による)同期レプリケーション機能 pgpool ver2 2004.6 負荷分散機能 pgpool-II ver1 2006.9 パラレルクエリー、2台以上の同期レプリケーション機能 pgpool-II ver2 2007.11 オンラインリカバリ
そもそもpgpoolは、PostgreSQLのコネクションプールサーバとして誕生しました。
PostgreSQLやOracleなどのRDBMSは、アプリケーションから接続を要求される毎にプロセスを起動してSQL文を実行します(図1)。
接続の過程を説明すると、
(1)アプリケーションがpostmaster(PostgreSQLのメインプロセス)に接続要求し、
(2)その度にpostgresというプロセスが生成され、(3)アプリケーションと接続完了、となります。
しかし、接続の度にプロセスを生成するのは負荷が高く処理性能が低下します。
これを避けるため予め複数のプロセスを起動しておく仕組みをコネクションプールといいます。
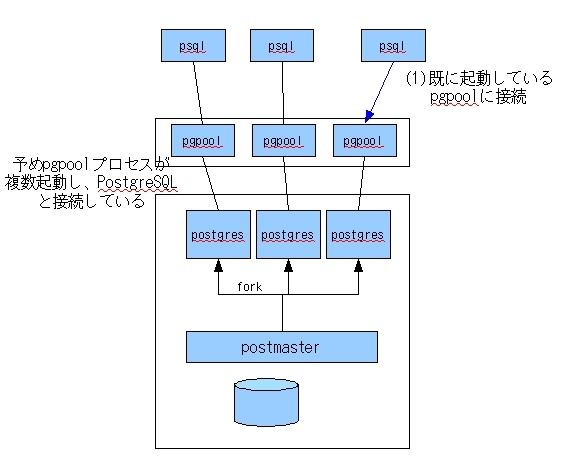
pgpoolはPostgreSQLの前段で事前に複数の子プロセスを起動し、それぞれがPostgreSQLのプロセスpostgresと接続されています(図2)。
アプリケーションからpgpoolに接続要求が届きSQL文が送られると、それをそのままPostgreSQLに転送するので、接続による性能低下が発生しないというわけです。
図1 PostgreSQLとの接続
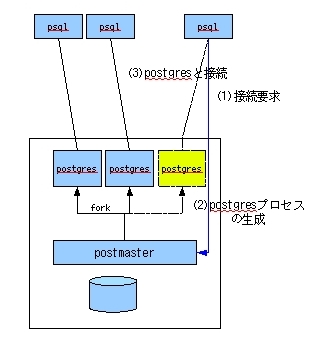
図2 pgpoolによるコネクションプールを利用した接続
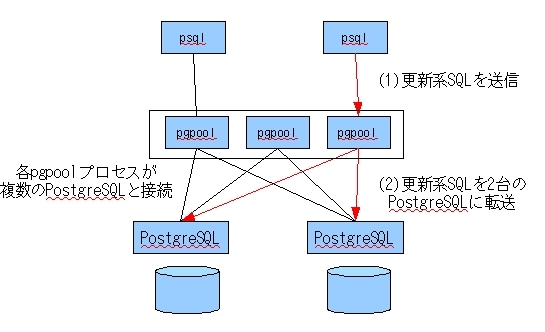
また、 PostgreSQLの前段で機能するというpgpoolの特徴から、 非常に早い段階に同期レプリケーションも実装されました(図3)。 これは、各pgpoolプロセスが2台のPostgreSQLサーバに接続し、 (1)アプリケーションから受け取った更新系のSQLを、(2)2台のPostgreSQLに転送するというものでした。
図3 pgpoolによる同期レプリケーションのイメージ
バージョン1のリリース以降、pgpoolは性能向上やバグフィックスが続けられましたが、 レプリケーションは2台までという制約がありました。
2006年9月、pgoolの後継としてpgpool-IIのバージョン1.0がリリースされました。
ここでレプリケーションの台数制限が撤廃され、3台以上の構成が可能となりました。
さらに2007年11月にpgpool-IIのバージョン2がリリースされ、オンラインリカバリ機能が実装されました。
1.3 システム構成とインストール環境
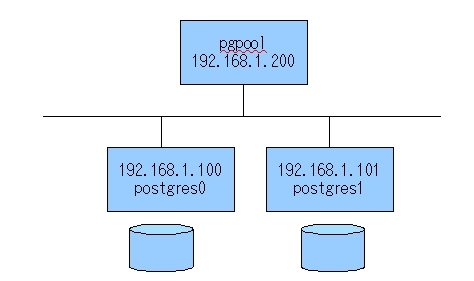
以降、3台のサーバを使ってpgpool-IIのレプリケーション機能、およびオンラインリカバリ機能について説明します。 今回のシステム構成に(図4)に示します。適宜、自身の環境に合わせて読みかえてください。
図4 システム構成
全サーバに"postgres"というユーザを登録してください。インストール作業はユーザpostgresで行います。
予め、ユーザpostgresの環境変数PATHにPostgreSQLとpgpool-IIのバイナリパス"/usr/local/pgsql/bin"、
"/usr/local/pgpool2/bin"を設定しておいてください。
export PATH=$PATH:/usr/local/pgsql/bin:/usr/local/pgpool2/bin
全サーバにrsyncとsshがインストール済みと仮定します。
また、サーバpgpoolはポート番号9999と9898に接続可能、 サーバpostgres0とpostgres1はポート番号5432に接続可能となるように、OSの設定を行ってください。
なお、以降の説明における、ターミナルで作業する場合のプロンプト表示は次の形式とします。
ユーザ名 @ サーバ名>
例えば、ユーザpostgresがサーバpostgres0で作業する場合は
postgres@postgres0>とします。
特に、2台のPostgreSQLサーバpostgres0とpostgres1で共通の作業を行う場合は
postgres@>と表記します。
1.4 PostgreSQLのインストール
はじめにPostgreSQLをインストールします。 pgpool-IIもPostgreSQLのライブラリlibpqを利用するので、 すべてのサーバにPostgreSQLをインストールすることにします。1.4.1 ソフトウエアの入手
PostgreSQLを入手します。最新版は8.3.4です。http://www.postgresql.org/ftp/source/v8.3.4/
1.4.2 インストール
PostgreSQLの最新版をダウンロードしたら、適当なディレクトリで展開し、 configureコマンドとmakeコマンドを実行します。root@> mkdir /usr/local/pgsql root@> chown postgres:postgres /usr/local/pgsql root@> su postgres postgres@> tar xvfz postgresql-8.3.4.tar.gz postgres@> cd postgresql-8.3.4 postgres@> ./configure postgres@> make && make install
デフォルトのインストールディレクトリは/usr/local/pgsql/です。
1.4.3 設定
インストールが終了したら、PostgreSQLを稼働させる2台のサーバ:postgres0とpostgres1で以下の設定を行います。1.4.3.1 データベースの初期化
データベースの初期化を行います。以下のコマンドを実行してください。postgres@> initdb -D /usr/local/pgsql/data
これでディレクトリ/usr/local/pgsql/data以下にデータベースが作成されます。 このディレクトリを「ベースディレクトリ」、ベースディレクトリ以下のデータを「データベースクラスタ」とよびます。
1.4.3.2 アーカイブログディレクトリの作成
アーカイブログを保存するディレクトリを作成します。 ここでは、ベースディレクトリにarchive_logというディレクトリを作成します。postgres@> mkdir /usr/local/pgsql/data/archive_log
1.4.3.3 設定ファイル
以上の準備が終わったら、2つの設定ファイルpostgresql.confとpg_hba.confの編集を行います。 これらはベースディレクトリ(今回はディレクトリ"/usr/local/pgsql/data")にあります。1つ目のファイルはposgtresql.confです(リスト1)。 数多くのパラメータがありますが、今回は次の3つのパラメータを設定してください。
リスト1 postgresql.confの抜粋
listen_addresses = '*' archive_mode = on archive_command = 'cp %p /usr/local/pgsql/data/archive_log/%f'
パラメータlisten_addressesはpgpool-IIからのアクセスを許可するために必要です。 行頭の"#"を消去して、設定値を"'*'"としてください。
パラメータarchive_modeとarchive_commandはオンラインリカバリのために必要です。 同じく行頭の"#"を消去して、それぞれ値を設定してください。 パラメータarchive_commandの設定値にあるディレクトリ"/usr/local/pgsql/data/archive_log/"は 上で作成したアーカイブログの保存ディレクトリを記述してください。
2つ目のファイルはアクセス制御ファイルpg_hba.confです。
ここでは、ネットワーク192.168.1.0からのアクセスはすべて許可する設定をします。
(リスト2)に示した行をpg_hba.confファイルの末尾に追加してください。
リスト2 pg_hba.confの末尾に追加
host all all 192.168.1.0/24 trust
1.4.4 PostgreSQLサーバの起動
以上でPostgreSQLの準備が整ったので、PostgreSQLを起動しましょう。 以下のコマンドを実行してください。postgres@> pg_ctl -D /usr/local/pgsql/data start
次に、これから実験で使うデータベースsampledbを作成しましょう。 createdbコマンドでデータベースを作成します。
postgres@> createdb sampledb
1.5 pgpool-IIのインストール
PostgreSQLの準備が終わったら、今度はサーバpgpool上でpgpool-IIのインストールを行います。- 2行目
pgpool-IIが接続を待つポート番号。 デフォルトは9999番。ユーザやアプリケーションはサーバpgpoolのポート番号9999に接続要求する。
- 3行目
pgpool-IIを制御するコマンド(pcp_node_countなど)が接続するポート番号。
- 7行目
レプリケーションモードを有効にする。
- 9-19行目
サーバpostgres0とpostgres1に関する設定項目。
1.5.1 ソフトウエアの入手
pgpool-IIの最新版を入手します。最新版は2.1です。http://pgfoundry.org/projects/pgpool/
http://pgfoundry.org/frs/download.php/1843/pgpool-II-2.1.tar.gz
1.5.2 インストール
pgpool-IIの最新版をダウンロードしたら、 適当なディレクトリで展開し、configureコマンドとmakeコマンドを実行します。 configureコマンドの"--with-pgsql-libdir"オプションにはライブラリlibpq.soのあるディレクトリを指定します。root@pgpool> mkdir /usr/local/pgpool2 root@pgpool> chown postgres:postgres /usr/local/pgpool2 root@pgpool> su postgres postgres@pgpool> tar xvfz pgpool-II-2.1.tar.gz postgres@pgpool> cd pgpool-II-2.1 postgres@pgpool> ./configure --prefix=/usr/local/pgpool2 \ > --with-pgsql-libdir=/usr/local/pgsql/lib postgres@pgpool> make && make install postgres@pgpool> cd sql/pgpool-recovery postgres@pgpool> make && make install
インストールディレクトリは/usr/local/pgpool2/です。このディレクトリ以下に各種ファイルがインストールされます。
1.5.3 設定
pgpool-IIのインストールが終了したら、3つの設定ファイルを準備します。 それぞれサンプルファイルが用意されているので、予めこれらをコピーしておきましょう。postgres@pgpool> cd /usr/local/pgpool2/etc postgres@pgpool> cp pcp.conf.sample pcp.conf postgres@pgpool> cp pgpool.conf.sample pgpool.conf postgres@pgpool> cp pool_hba.conf.sample pool_hba.conf
1.5.3.1 pcp.conf
pcp.confファイルは、pgpool-IIを制御するpcp関連コマンドの認証のために必要になります。 ここではユーザ名"pgpool2"、パスワードも"pgpool2"として登録します。 (リスト3)に示した行をpcp.confファイルの末尾に追加してください。
リスト3 pcp.confの末尾に追加
pgpool2:027adbeda60c4110f38c4d484c6f9731
pcp.confファイルの書式は「ユーザ名:パスワードのmd5ハッシュ値」で、md5ハッシュ値はコマンドpg_md5で得ることができます。
postgres@pgpool> pg_md5 pgpool2 027adbeda60c4110f38c4d484c6f9731
1.5.3.2 pgpool.conf
次に、pgpoolの基本動作を制御するための設定ファイルpgpool.confを編集します。レプリケーションモードで動作させるために(リスト4)で示す項目を設定してください。
リスト4 pgpool.confの抜粋
1: # pgpool-IIへのアクセスを許可するネットワークやアドレスを指定する 2: listen_addresses = '*' # '*'を設定すると、無条件で接続可能 3: port = 9999 # pgpool-IIのアクセスポート 4: pcp_port = 9898 # pgpool-IIの制御用アクセスポート 5: 6: # pgpool-IIをレプリケーションモードで起動 7: replication_mode = true 8: 9: # ノード0 => サーバpostgres0の情報を設定 10: backend_hostname0 = '192.168.1.100' # サーバpostgres0のIPアドレス 11: backend_port0 = 5432 # PostgreSQLのポート番号 12: backend_weight0 = 1 13: backend_data_directory0 = '/usr/local/pgsql/data' # ベースディレクトリ 14: 15: # ノード1 => サーバpostgres1の情報を設定 16: backend_hostname1 = '192.168.1.101 # サーバpostgres1のIPアドレス 17: backend_port1 = 5432 # PostgreSQLのポート番号 18: backend_weight1 = 1 19: backend_data_directory1 = '/usr/local/pgsql/data' # ベースディレクトリ
pgpool-IIは各PostgreSQLサーバを"ノード"として管理して、 例えば"backend_hostname0"や"backend_port0"など末尾が0の場合は"ノード0"となります。 今回の場合はサーバpostgres0がノード0、サーバpostgres1がノード1となります。
1.5.3.3 pool_hba.conf
最後に、pgpool-IIのアクセス制御を行う設定ファイルpool_hba.confを編集します。 書式はPostgreSQLのアクセス制御ファイルpg_hba.confと同じです。ここでは説明の簡略化のため、セキュリティを無視して(リスト5)の行を追加してください。
リスト5 pool_hba.confの末尾に追加
host all all 127.0.0.1/32 trust host all all 192.168.1.0/24 trust
これにより、ネットワーク192.168.1.0からのアクセスはすべて許可されます。
1.5.4 PostgreSQLでの設定
pgpool-IIの設定が終わったら、最後の仕上げです。 オンラインリカバリのためのライブラリをPostgreSQLサーバにコピーし、 バッチファイルを実行します。まず、ライブラリpgpool-recovery.soをPostgreSQLのあるサーバの/usr/local/pgsql/libに、 バッチファイルpgpool-recovery.sqlを/usr/local/pgsql/shareにコピーします(図5)。
図5 ライブラリpgpool-recovery.soとバッチファイルpgpool-recovery.sqlのコピー
postgres@pgpool> cd sql/pgpool-recovery postgres@pgpool> scp pgpool-recovery.so 192.168.1.100:/usr/local/pgsql/lib postgres@pgpool> scp pgpool-recovery.so 192.168.1.101:/usr/local/pgsql/lib postgres@pgpool> scp pgpool-recovery.sql 192.168.1.100:/usr/local/pgsql/share postgres@pgpool> scp pgpool-recovery.sql 192.168.1.101:/usr/local/pgsql/share
つぎに、各PostgreSQLサーバ上でバッチファイルpgpool-recovery.sqlを実行します(図6)。
図6 バッチファイルpgpool-recovery.sqの実行
postgres@> psql -c "\i /usr/local/pgsql/contrib/pgpool-recovery.sql" -U postgres template1
1.6 動作確認
すべての準備が終わったので、システムの動作確認を行いましょう。まず、pgpool-IIを起動します。pgpoolコマンドを引数なしで実行してください。
postgres@pgpool> pgpool
無事起動したら、pgpool-IIに接続してみましょう(図7)。 PostgreSQLのターミナルソフトpsqlで接続しますが、 "-h"オプションにpgpool-IIが起動しているサーバのIPアドレス192.168.1.200、 "-p"オプションに9999を設定してください。
接続できたら、テスト用のテーブルtblを作成し、いくつかデータを挿入してみます。
図7 pgpool-IIに接続し、テーブルtblを作成
postgres@pgpool> psql -h 192.168.1.200 -p 9999 sampledb -q sampledb=# CREATE TABLE tbl(id int); CREATE TABLE sampledb=# INSERT INTO tbl VALUES (1); INSERT 0 1 sampledb=# INSERT INTO tbl VALUES (2); INSERT 0 1 sampledb=# INSERT INTO tbl VALUES (3); INSERT 0 1 sampledb=# SELECT * FROM tbl; id ---- 1 2 3 (3 rows)
うまくpgpool-IIが動作したのか、直接PostgreSQLサーバに接続して確認してみましょう(図8)。 サーバpostgres0のIPアドレス192.168.1.100を"-h"オプションに設定して接続します。 実際にサーバpostgres0にテーブルtblが作成されていたことが確認できたでしょうか。
図8 サーバpostgres0に接続し、テーブルtblの内容を確認
postgres@pgpool> psql -h 192.168.1.100 sampledb -q sampledb=# SELECT * FROM tbl; id ---- 1 2 3 (3 rows)
pgpool-IIを停止する場合は、stopオプションをつけてpgpoolコマンドを実行します。
postgres@pgpool> pgpool stop
1.7 オンラインリカバリ
ここまでpgpool-IIによるレプリケーションについて説明してきました。 これからいよいよ高可用性の要、オンラインリカバリについて説明します。- フェーズ1
リカバリ元のベースバックアップをリカバリするサーバに転送。
- フェーズ2
フェース1の作業中に更新されたアーカイブログを転送し、サーバを再起動。 先に転送されたベースバックアップと合わせてデータベースのリカバリ後にサービス開始。
1.7.1 オンラインリカバリの仕組み
pgpool-IIのオンラインリカバリの仕組みを解説します(図9)。pgpool-IIのオンラインリカバリは、2つのフェーズにわかれています。
図9 pgpool-IIのオンラインリカバリ
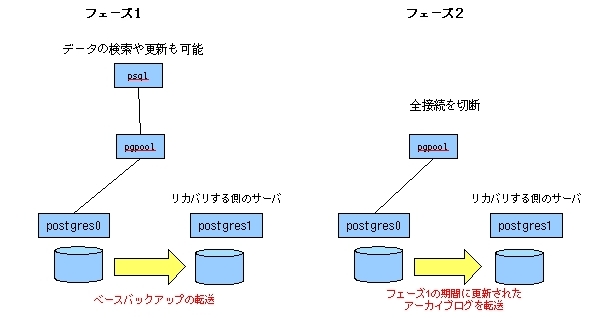
フェーズ1ではデータ操作が可能です。 フェーズ1の期間に更新されたデータはフェーズ2で転送されて、リカバリするサーバに反映されます。 よって、フェーズ2の期間はデータ操作を禁止しなければなりません。 pgpool-IIはすべての接続が切断されるまでフェーズ2に入らずに待機します。
厳密に言えばフェーズ2の間はデータベースアクセスができないので、
「システム停止なしでリカバリできる」とはいえないかもしれませんが、
フェーズ2にかかる時間はフェーズ1で更新されたデータが反映されているアーカイブログの転送と、
PostgreSQLサーバの起動にかかる時間だけですので、
早ければ数秒で終了します。
1.8 オンラインリカバリの準備
1.8.1 SSH
PostgreSQLをインストールした2台のサーバ間でパスワード入力なしでsshコマンドを実行するため(脚注1)、 サーバpostgres0で(図10)、 サーバpostgres1で(図11)の作業を行います。
脚注1 sshとrsyncを使ってベースバックアップやアーカイブログの転送を行ったり、 sshで相手側のPostgreSQLサーバを起動するためです。
図10 サーバpostgres0で行う作業
postgres@postgres0> ssh-keygen -t dsa # パスフレーズは空白 postgres@postgres0> scp ~/.ssh/id_dsa.pub 192.168.1.101:~/ postgres@postgres0> ssh 192.168.1.101 postgres@postgres1> cat id_dsa.pub >> ~/.ssh/authorized_keys2 postgres@postgres1> rm id_dsa.pub
図11 サーバpostgres1で行う作業
postgres@postgres1> ssh-keygen -t dsa # パスフレーズは空白 postgres@postgres1> scp ~/.ssh/id_dsa.pub 192.168.1.100:~/ postgres@postgres1> ssh 192.168.1.100 postgres@postgres0> cat id_dsa.pub >> ~/.ssh/authorized_keys2 postgres@postgres0> rm id_dsa.pub
念のため,ファイルとディレクトリのパーミッションを再設定してください。
postgres@postgres0> chmod 700 ~/.ssh postgres@postgres0> chmod 600 ~/.ssh/authorized_keys2
postgres@postgres1> chmod 700 ~/.ssh postgres@postgres1> chmod 600 ~/.ssh/authorized_keys2
1.8.2 スクリプト
サーバpostgres0とpostgres1のベースディレクトリ(ここでは/usr/local/pgsql/data)に、 シェルスクリプトrecovery_1st_stage.sh(図12)とrecovery_2nd_stage.sh(図13)とpgpool_remote_start(図14)を置き、パーミッションを実行可能としてください。postgres@> cd /usr/local/pgsql/data postgres@> chmod +x recovery_1st_stage.sh postgres@> chmod +x recovery_2nd_stage.sh postgres@> chmod +x pgpool_remote_start
図12 recovery_1st_stage.sh
#! /bin/bash
PSQL=/usr/local/pgsql/bin/psql
MASTER_BASEDIR=$1
RECOVERY_HOST=$2
RECOVERY_BASEDIR=$3
# ベースバックアップの開始
$PSQL -c "SELECT pg_start_backup('pgpool-recovery')" postgres
# リカバリ先用のrecovry.confファイル生成
echo "restore_command = 'cp $RECOVERY_BASEDIR/archive_log/%f %p'" > $MASTER_BASEDIR/recovery.conf
# リカバリ先のデータベースクラスタを念のためにバックアップ
ssh -T $RECOVERY_HOST rm -rf $RECOVERY_BASEDIR.bk
ssh -T $RECOVERY_HOST mv -f $RECOVERY_BASEDIR{,.bk}
# データベースクラスタ=ベースバックアップをリカバリ先に転送
rsync -az -e ssh $MASTER_BASEDIR/ $RECOVERY_HOST:$RECOVERY_BASEDIR/
ssh -T $RECOVERY_HOST cp -f $RECOVERY_BASEDIR.bk/postgresql.conf $RECOVERY_BASEDIR
ssh -T $RECOVERY_HOST rm -f $RECOVERY_BASEDIR/postmaster.pid
# リカバリ先に転送したので、不要になったrecovery.confを削除
rm -f $MASTER_BASEDIR/recovery.conf
# ベースバックアップの終了
$PSQL -c "SELECT pg_stop_backup()" postgres
図13 recovery_2nd_stage.sh
#! /bin/bash PSQL=/usr/local/pgsql/bin/psql MASTER_BASEDIR=$1 RECOVERY_HOST=$2 RECOVERY_BASEDIR=$3 # 最新のアーカイブログを保存 $PSQL -c 'SELECT pg_switch_xlog()' postgres # 最新のアーカイブログをリカバリ先に転送 rsync -az -e ssh $MASTER_BASEDIR/archive_log/ $RECOVERY_HOST:$RECOVERY_BASEDIR/archive_log/
図14 pgpool_remote_start
#! /bin/sh PGCTL=/usr/local/pgsql/bin/pg_ctl RECOVERY_HOST=$1 RECOVERY_BASEDIR=$2 # リカバリ先のPostgreSQLを起動 ssh -T $RECOVERY_HOST $PGCTL -w -D $RECOVERY_BASEDIR start 2>/dev/null 1> /dev/null < /dev/null &
これらのスクリプトがどのような働きをするか、(図15)に時系列で示します。
図15 スクリプト実行の時系列
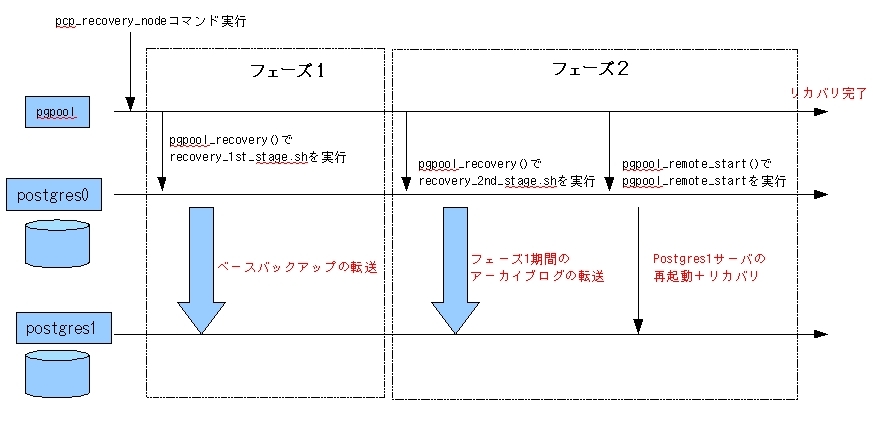
ここでは、サーバpostgres0からサーバpostgres1(リカバリ先)をリカバリするとします。
次セクションで説明するpcp_recovery_nodeコマンドをpgpool-IIが受け取ると、
オンラインリカバリが始まります。
フェーズ1では、pgpool-IIはサーバpostgres0にpgpool_recovery()関数を実行させます。
ここでpgpool_recovery()関数は、pgpool-IIインストール時に設定したライブラリpgpool-recovery.soと
バッチファイルpgpool-recovery.sqlによってPostgreSQLに登録された関数で、
ベースディレクトリにあるシェルスクリプトを実行します。
ここではrecvery_1st_stage.shを実行します。
recvery_1st_stage.sh(図12)の主な仕事は、ベースバックアップを別のサーバに転送することです。
今回はrsyncのsshモードで転送しています。
フェーズ1が終わると、全接続が切断されるのを待ってフェーズ2に入ります。
フェーズ2では、recovery_2nd_stage.shが実行されます。
recovery_2nd_stage.sh(図13)では、サーバpostgres0でpg_switch_xlog()関数を実行して
最新のアーカイブログを書き出し、そのアーカイブログをrsyncのsshモードで転送しています。
これでサーバpostgres1を再起動する準備が整ったので、
pgpool-IIはサーバpostgres0にpgpool_remote_start()関数を実行させます。
ここでpgpool_remote_start()関数も、先のインストールで登録された関数です。
pgpool_remote_start()関数はシェルスクリプトpgpool_remote_startを実行する関数で、
pgpool_remote_start(図14)の中身は、リカバリするサーバ上のPostgreSQLを起動するコマンドだけが
書かれています。
1.9 オンラインリカバリの実行
以上でオンラインリカバリを試す準備が整いました。これから、pgpool-IIの制御を行う6つのコマンドを説明しながら、 オンラインリカバリを行います。
ここで説明するコマンドの主役は、先に(図15)で登場したpcp_recevory_nodeですが、 他のコマンドもpgpool-IIを運用するために必須です。
1.9.1 pcp_node_count
はじめに、pcp_node_countコマンドでpgpool-IIが管理しているPostgreSQLサーバの数を確認しましょう(図16)。
図16 pcp_node_countの使い方
Usage: pcp_node_count timeout hostname port# username password timeout - connection timeout value in seconds. command exits on timeout hostname - pgpool-II hostname port# - pgpool-II port number username - username for PCP authentication password - password for PCP authentication -h - print this help
タイムアウトtimeoutは適当な時間を設定してかまいません。 port番号は9898を指定します。 ユーザ名とパスワードは"pgpool2"を指定します。 今回はpostgres0とpostgres1の2つのnodeが接続されているので、"2"と表示されるはずです。
postgres@pgpool> pcp_node_count 10 192.168.1.200 9898 pgpool2 pgpool2 2
1.9.2 pcp_node_info
次にpcp_node_infoコマンドで各ノードの情報を表示させます。 コマンドに与える引数は最後のnodeIDを除いてpcp_node_countコマンドと同じです(図17)。 pgpool-IIは各PostgreSQLサーバを"ノード"として管理していて、 サーバpostgres0はノード0、サーバpostgres1はノード1となっています。
図17 pcp_nodeinfoの使い方
Usage: pcp_node_info timeout hostname port# username password nodeID timeout - connection timeout value in seconds. command exits on timeout hostname - pgpool-II hostname port# - pgpool-II port number username - username for PCP authentication password - password for PCP authentication nodeID - ID of a node to get information for
pcp_node_infoの出力は(表2)に示す4項目ですが、 重要なのは第3項目の"状態"(表3)です。
表2 pcp_node_infoの出力
| 項目 | 説明 |
| IPaddr | ノードのアドレス |
| port | ノードのport番号 |
| status | 状態(表3を参照) |
| weight | 重み(リスト4のbackend_weight0など参照)。ただし出力される値にあまり意味はない |
表3 pcp_node_infoの状態
| 状態 | 説明 |
| 1 | 正常接続 |
| 2 | アイドル状態 |
| 3 | 切断 |
| 4 | エラー |
| 5 | フェイタルエラー |
| 6 | デッドロック |
サーバpostgres0とpostgres1、つまりノード0とノード1の情報を表示してみます(図18)。 状態は共に2、つまりアイドルですが正常な状態です。状態が1か2ならば問題ありません。
図18 pcp_nodeinfの実行例
postgres@pgpool> pcp_node_info 100 192.168.1.200 9898 pgpool2 pgpool2 0 192.168.1.100 5432 2 1073741823.500000 postgres@pgpool> pcp_node_info 100 192.168.1.200 9898 pgpool2 pgpool2 1 192.168.1.101 5432 2 1073741823.500000
ここで、ノード1のPostgreSQLを緊急停止しましょう。
停止モードオプション"-m"に"immediate"を設定すると、
接続しているセッションの有無にかかわらず、サーバが緊急停止します。
postgres@postgres1> pg_ctl -D /usr/local/pgsql/data -m immediate stop
もう一度、ノード1のノード情報を調べましょう。状態が3で、切断されていることがわかります。
postgres@pgpool> pcp_node_info 100 192.168.1.200 9898 pgpool2 pgpool2 1 192.168.1.101 5432 3 1073741823.500000
1.9.3 pcp_detach_node, pcp_attach_node
停止したノードを切り離すにはpcp_detach_nodeコマンド、 ノードを接続するにはpcp_attach_nodeコマンドを使います。 コマンド実行時の引数はpcp_node_infoコマンドと同じなので省略します。ノード1を切り離します。
postgres@pgpool> pcp_detach_node 100 192.168.1.200 9898 pgpool2 pgpool2 1
1.9.4 pcp_recovery_node
最後に、オンラインリカバリを行うコマンドpcp_recovery_nodeです。 引数はpcp_node_infoコマンドと同じなので省略します。 ここでは、ノード1をリカバリします。postgres@pgpool> pcp_recovery_node 100 192.168.1.200 9898 pgpool2 pgpool2 1
リカバリ中にエラーが発生すれば、エラーメッセージが出力されます。 リカバリが正常に進行している間は一切メッセージを出力しないので、ちょっと不安になりますが、 実際の運用では設定ファイルpgpool.confでpgpool-IIのログを出力させて監視すれば問題ないでしょう。
オンラインリカバリが終了したら、pcp_attach_nodeコマンドでノード1を接続します。
そしてノード1の状態を調べ、オンラインリカバリが成功したことを確認しましょう。
postgres@pgpool> pcp_attach_node 100 192.168.1.200 9898 pgpool2 pgpool2 1 postgres@pgpool> pcp_node_info 100 192.168.1.200 9898 pgpool2 pgpool2 1 192.168.1.101 5432 1 1073741823.500000
1.10 まとめ
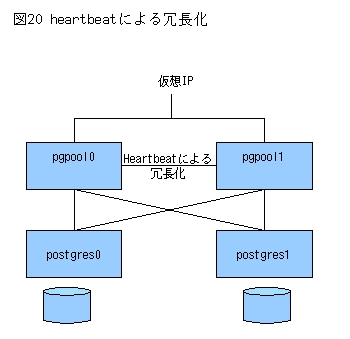
以上、pgpool-IIを使ったレプリケーションと、 高可用性システムのためのオンラインリカバリについて説明しました。なお、これまで説明した構成では、 pgpool-IIが単一障害点となります。 これを避けるには、pgpool-IIを二重化してアプリケーションかロードバランサで負荷分散させるか(図19)、 pgpool-haとheartbeatで冗長化させるなどの方法があります(図20)。
図19 pgpool-IIの多重化
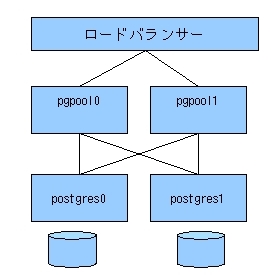
図20 heartbeatによる冗長化
pgpool-haに関する情報は
http://pgpool.sraoss.jp/index.php?pgpool-HAを参照してください。