7.4. TensorFlow, PyTorch and Keras
This section presents the code implementation for simple RNNs using TensorFlow, Keras and PyTorch frameworks.
7.4.1. TensorFlow Version
Complete Python code is available at: RNN_tf.py
The RNN class is composed of tf.keras.layers.SimpleRNN and tf.keras.layers.Dense.
class RNN(tf.keras.Model):
def __init__(self, hidden_units, output_units):
super().__init__()
self.simple_rnn = tf.keras.layers.SimpleRNN(
hidden_units,
activation="tanh",
kernel_initializer="glorot_normal",
recurrent_initializer="orthogonal",
)
self.dense = tf.keras.layers.Dense(output_units, activation="linear")
def call(self, x):
x = self.simple_rnn(x)
x = self.dense(x)
return x[1] Create dataset.
n_sequence = 25
n_data = 100
n_sample = n_data - n_sequence # number of sample
sin_data = ds.create_wave(n_data, 0.05)
X, Y = ds.dataset(sin_data, n_sequence, False)
X = X.reshape(X.shape[0], X.shape[1], 1)
Y = Y.reshape(Y.shape[0], Y.shape[1])[2] Create model.
input_units = 1
hidden_units = 32
output_units = 1
model = RNN(hidden_units, output_units)
lr = 0.0001
beta1 = 0.99
beta2 = 0.9999
optimizer = Optimizer.Adam(lr=lr, beta1=beta1, beta2=beta2)[3] Training.
n_epochs = 300
for epoch in range(1, n_epochs + 1):
with tf.GradientTape() as tape:
preds = model(X)
loss = criterion(Y, preds)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
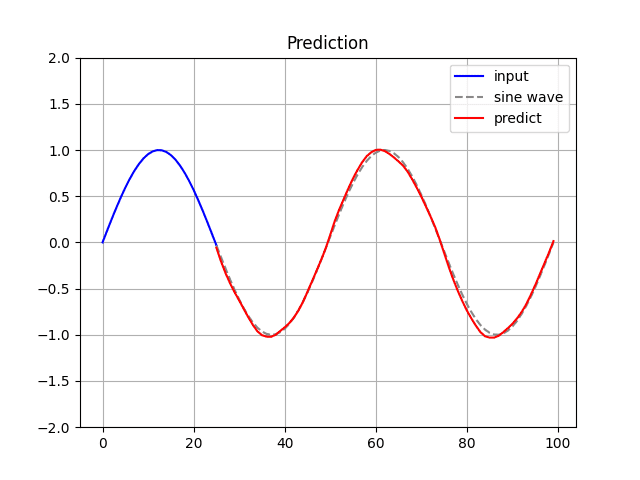
train_loss(loss)[4] Prediction.
$ python RNN_tf.py
Model: "rnn"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) multiple 1088
dense (Dense) multiple 33
=================================================================
Total params: 1,121
Trainable params: 1,121
Non-trainable params: 0
_________________________________________________________________
epoch: 1/300, loss: 0.0864
... snip ...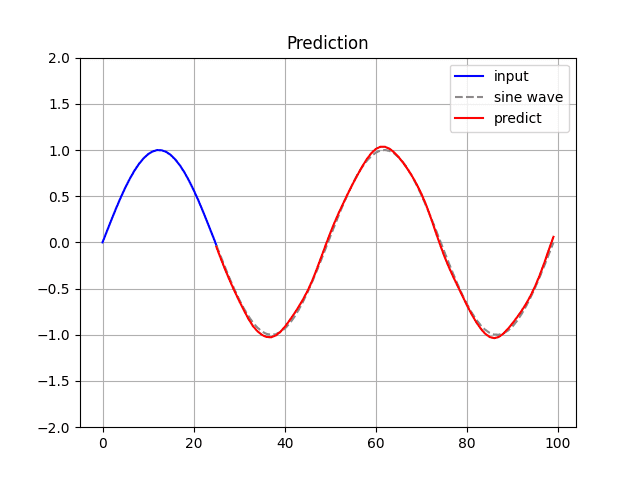
7.4.2. PyTorch Version
Complete Python code is available at: RNN_pt.py
[1] Create dataset.
n_sequence = 25
n_data = 100
n_sample = n_data - n_sequence # number of sample
sin_data = ds.create_wave(n_data, 0.05)
X, Y = ds.dataset(sin_data, n_sequence, False)
X = X.reshape(X.shape[0], X.shape[1], 1)
Y = Y.reshape(Y.shape[0], Y.shape[1])[2] Create model.
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(device)
class RNN(nn.Module):
def __init__(self, input_units, hidden_units, output_units):
super().__init__()
self.rnn = nn.RNN(input_units, hidden_units, nonlinearity="tanh", batch_first=True)
self.dense = nn.Linear(hidden_units, output_units)
nn.init.xavier_normal_(self.rnn.weight_ih_l0)
nn.init.orthogonal_(self.rnn.weight_hh_l0)
def forward(self, x):
h, _ = self.rnn(x)
y = self.dense(h[:, -1])
return y
input_units = 1
hidden_units = 32
output_units = 1
model = RNN(input_units, hidden_units, output_units).to(device)
summary(model=RNN(input_units, hidden_units, output_units), input_size=X.shape)
lr = 0.001
beta1 = 0.9
beta2 = 0.999
criterion = nn.MSELoss(reduction="mean")
optimizer = optimizers.Adam(
model.parameters(), lr=lr, betas=(beta1, beta2), amsgrad=True
)[3] Training.
n_epochs = 300
history_loss = []
for epoch in range(1, n_epochs + 1):
train_loss = 0.0
x = torch.Tensor(X).to(device)
y = torch.Tensor(Y).to(device)
model.train()
preds = model(x)
loss = criterion(y, preds)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
history_loss.append(train_loss)[4] Prediction.
$ python RNN_pt.py
mps
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
RNN [75, 1] --
├─RNN: 1-1 [75, 25, 32] 1,120
├─Linear: 1-2 [75, 1] 33
==========================================================================================
Total params: 1,153
Trainable params: 1,153
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 2.10
==========================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 0.48
Params size (MB): 0.00
Estimated Total Size (MB): 0.49
==========================================================================================
epoch: 10/300, loss: 0.193
... snip ...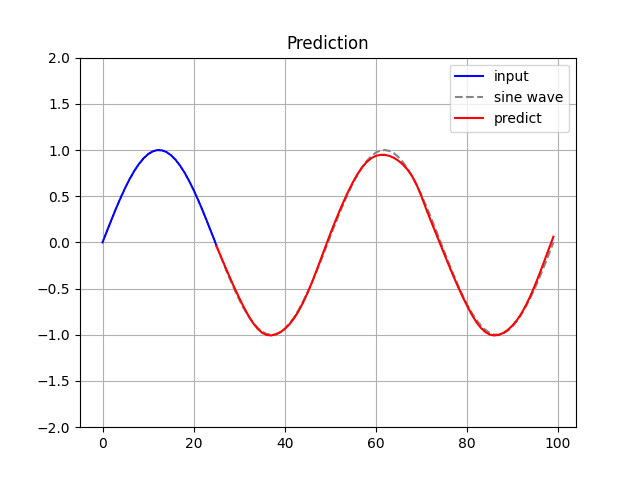
7.4.3. Keras Version
Complete Python code is available at: RNN_keras.py
[1] Create model.
lr = 0.001
input_units = 1
hidden_units = 32
output_units = 1
model = Sequential()
model.add(
SimpleRNN(
hidden_units,
activation="tanh",
use_bias=True,
input_shape=(n_sequence, input_units),
return_sequences=False,
)
)
model.add(Dense(output_units, activation="linear", use_bias=True))
model.compile(loss="mean_squared_error", optimizer=Adam(lr))[2] Training.
n_epochs = 100
batch_size = 5
history_rst = model.fit(
X,
Y,
batch_size=batch_size,
epochs=n_epochs,
validation_split=0.1,
shuffle=True,
verbose=1,
)[3] Prediction.
$ python RNN_keras.py
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 32) 1088
dense (Dense) (None, 1) 33
=================================================================
Total params: 1,121
Trainable params: 1,121
Non-trainable params: 0
_________________________________________________________________
None
Epoch 1/100
... snip ...