16.1. Create Model
A Transformer model is built upon two main components: an encoder and a decoder, alongside a linear layer and a softmax layer. See Fig.16-1.
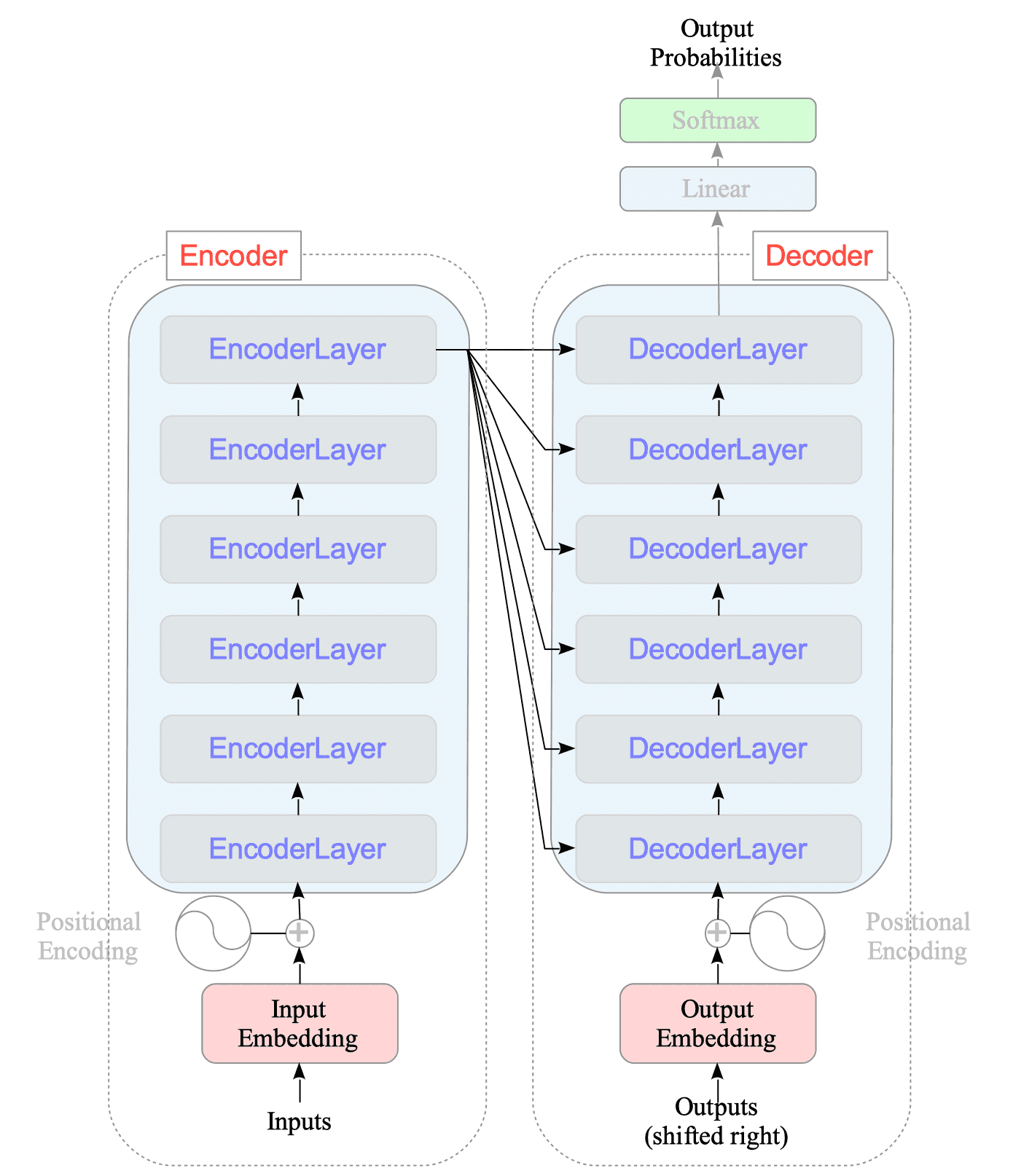
Fig.16-1: Transformer Model Architecture
The encoder consists of:
- Input modules: This includes embedding coding and positional encoding.
- Encoder layers: A stacked series of identical “EncoderLayer” modules.
Similarly, the decoder consists of:
- Output modules: These modules handle specific output tasks.
- Decoder layers: A stacked series of identical “DecoderLayer” modules.
This section delves into the intricacies of the encoder, decoder, and how they work together to form the complete Transformer model.
This implementation does not include a hyper-parameter for explicit sequence length limitation, because this is a toy program and sets the longest sentence in the received dataset to the maximum sequence length.
16.1.1. Encoder
16.1.1.1. EncoderLayer
Figure 16-2 illustrates the EncoderLayer:
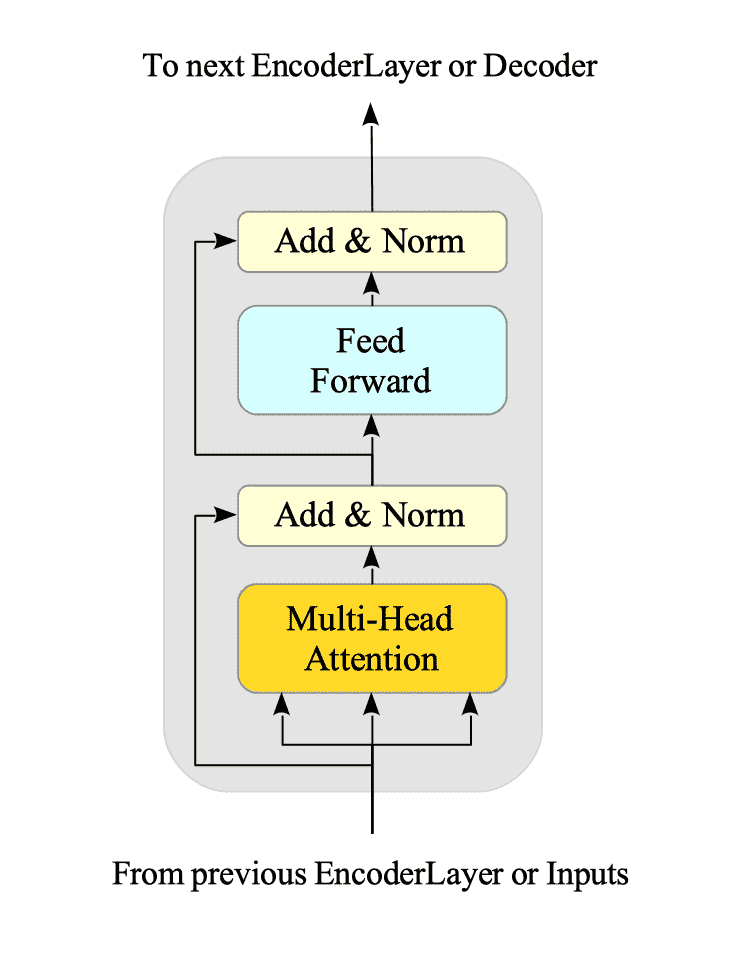
Fig.16-2: Encoder Layer Architecture
This layer combines three key mechanisms:
- Multi-Head Attention explained in Section 15.2.
- Pointwise Feed-Forward Network explained in Section 15.3.
- Normalization layers.
Here’s the Python code implementing this layer:
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, d_ffn, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, d_ffn)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output)
return out2Two dropout layers are used to prevent overfitting.
16.1.1.2. Encoder
The Encoder class builds upon the EncoderLayer by stacking multiple layers, along with word embedding and positional encoding modules. It outputs the final layer’s representation of the input sentence.
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, d_ffn, source_vocab_size, maximum_position_encoding, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(source_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, self.d_model)
self.enc_layers = [
EncoderLayer(d_model, num_heads, d_ffn, rate) for _ in range(num_layers)
]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attention_weights = {}
seq_len = tf.shape(x)[1]
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, attention_weight = self.enc_layers[i](x, training, mask)
attention_weights["encoder_layer{}".format(i + 1)] = attention_weight
return x, attention_weights16.1.2. Decoder
16.1.2.1. DecoderLayer
Figure 16-3 illustrates the DecoderLayer:
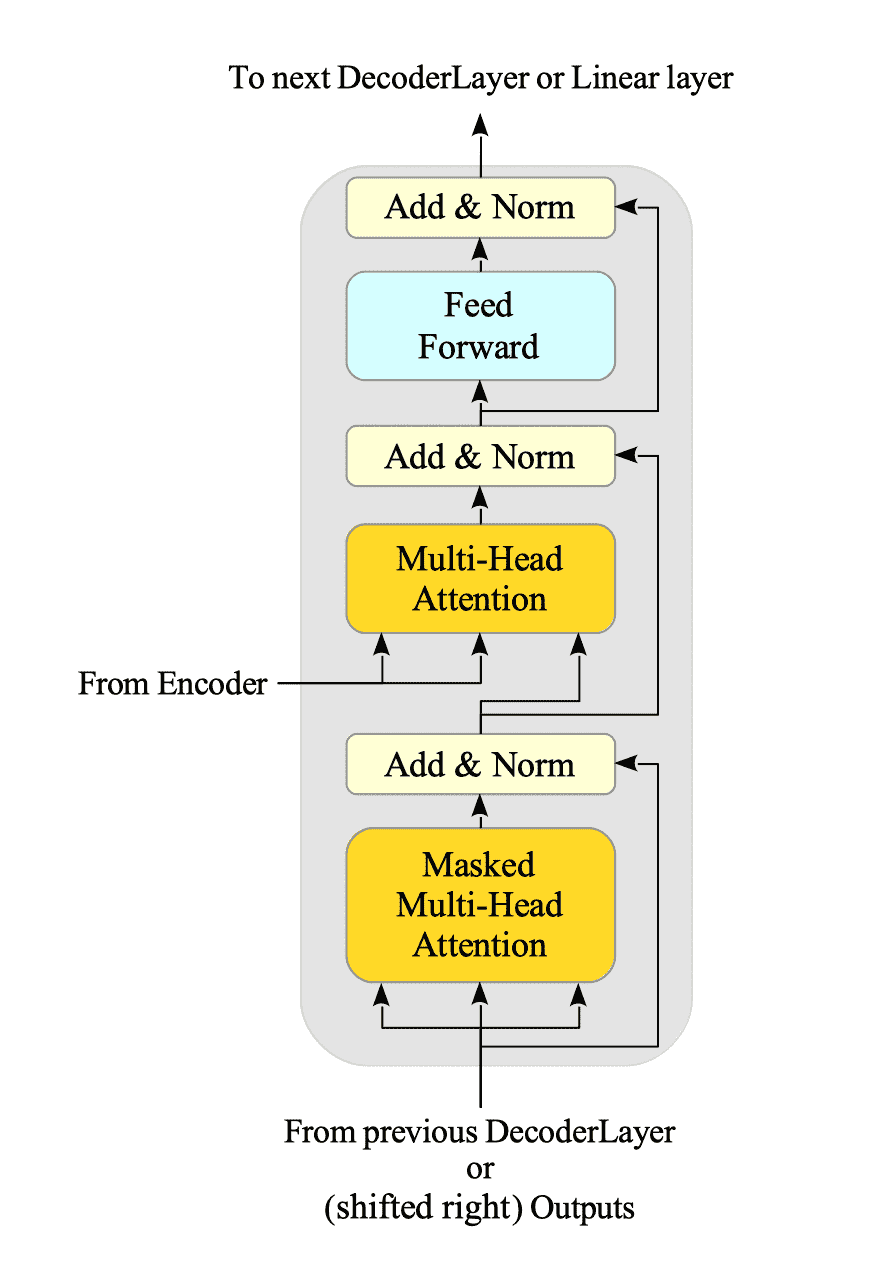
Fig.16-3: Decoder Layer Architecture
This layer combines four key mechanisms.
- Multi-Head Attention and Masked Multi-Head Attention.
- Pointwise Feed-Forward Network.
- Normalization layers.
Here’s the Python code implementing this layer:
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, d_ffn, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, d_ffn)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training, look_ahead_mask, padding_mask):
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(enc_output, enc_output, out1, padding_mask)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1)
ffn_output = self.ffn(out2)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2)
return out3, attn_weights_block1, attn_weights_block216.1.2.2. Decoder
The Decoder class builds upon the DecoderLayer by stacking multiple layers, along with word embedding and positional encoding modules. It returns the output of the final DecoderLayer, which is passed to the Softmax Layer.
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, d_ffn, target_vocab_size, maximum_position_encoding, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, d_ffn, rate) for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training, look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, training, look_ahead_mask, padding_mask)
attention_weights["decoder_layer{}_block1".format(i + 1)] = block1
attention_weights["decoder_layer{}_block2".format(i + 1)] = block2
return x, attention_weights16.1.3. Transformer model
The Transformer class consists of an encoder, a decoder, and a softmax layer.
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, d_ffn, source_vocab_size, target_vocab_size, pe_input, pe_target, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, d_ffn, source_vocab_size, pe_input, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, d_ffn, target_vocab_size, pe_target, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, source_sentences, target_sentences, training, enc_padding_mask, look_ahead_mask, dec_padding_mask):
enc_output, encoder_attention_weights = self.encoder(source_sentences, training, enc_padding_mask)
dec_output, decoder_attention_weights = self.decoder(target_sentences, enc_output, training, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output)
return final_output, attention_weights