Hash
ソースはGitHubに移行しました。
並行処理の観点からハッシュテーブルのアルゴリズムについて調べてみた。
結論からいうと:
- 要素が増えたことに依るresize(再構築)をLockFree、またはWaitFreeで行う(実用的な)アルゴリズムはない
- resize(再構築)しないならば、基本操作(挿入・削除・検索)をLockFree化するのはたやすい
分類
ハッシュテーブルを分類する観点として、以下の3つを考える。
データ格納法
Chain (Open Hash)型
教科書に最初に出てくるハッシュ法。同じハッシュ値を持つ要素はリストに連結される。
現時点で実装したのは以下:
Open Address (Closed Hash)型
配列ベースのハッシュ法。要素は必ず配列に保存される。同じハッシュ値を持つ要素があると、どちらかを別の場所に移動する。
現時点で実装したのは以下:
テーブルの再構築(resize)
要素数に応じてテーブルを拡大(再構築:resize)するか否か。
今回の実装はすべてresizeできるものだけ。
resizeなし
予め十分なテーブルサイズをとる。Chain(Open Hash)型ならば追加できる要素数に制限がないが、Open Address(Closed Hash)型の場合は事前に用意した要素数しか保存できない。
どちらも衝突(Colission)が多くなると検索性能が劣化し、ハッシュテーブルを使う意味が失われる。
ただし、CuchooハッシュとConcurrentCuchooハッシュは各種操作が最悪でも2ステップで終わる興味深い性質を持つ。
ロック粒度
Lockベース
粗粒度から細粒度までバリエーションあり。
今回の実装はすべてLockベース。
Lock-Free
resize(再構築)を考えなければ比較的簡単に実装できる。 たとえば "High Performance Dynamic Lock-Free Hash Tables and List-Based Sets"。 これはハッシュテーブルに付随するリストをLockFreeにするというほぼ自明な実装。
resize処理をLock-Freeで行うアルゴリズムも提案されているが、実用的ではないと思われる。参考文献を参照のこと。
resize(再構築)している間、すべての処理が止まるのは悔しいが、 ふと学生時代に使ったアルゴリズムの教科書をみたら 「新しいテーブルに全部の要素を移してから挿入するほうが平均時間が短いし、あとの操作のことを考えると、 テーブルを作りなおす時間のもとは十分にとれる」という記述をみつけ、含蓄のある言葉だなと感心した次第。
resizeあり
要素数が一定以上増加すると、テーブルサイズを大きくして衝突確率を下げる。resize(再構築)時には全ての処理が止まる。
resize処理をLock-Freeで行うアルゴリズムも提案されているが、実用的ではないと思われる。参考文献を参照のこと。
参考文献
Lock-Free/Wait-freeでめぼしいものをピックアップ:
Chain (Open Hash)型
"High Performance Dynamic Lock-Free Hash Tables and List-Based Sets"
リスト部分をLock-Freeリストにしたもの。resize(再構築)に関する記述ないが、Lock-freeでresizeはできないはず。"Split-Ordered Lists: Lock-Free Extensible Hash Tables"
resize(再構築)はOSのメモリアクセスと同じような"多段階アクセス"を使って*避けて*いる。基本的なアルゴリズム:
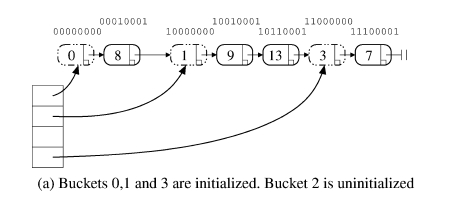
これに対してresizeを避ける方法:
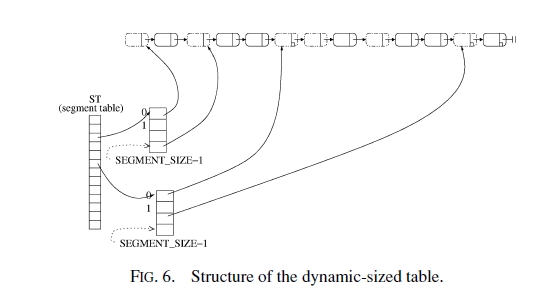
Open Address (Close Hash)型
Almost Wait-free Resizable Hashtables
- "AlmostWait-free Resizable Hashtables"
- "Efficient Almost Wait-free Parallel Accessible Dynamic Hashtables"
- "Lock-free dynamic hash tables with open addressing"
同一著者による3本。短縮版1本と詳細版2本。アルゴリズムの正当性確認にPVSを使っている。
予め、並行処理できる上限Nを決め、2N個のハッシュテーブルを準備しておく。そしてこの2N個のハッシュテーブルに対してほとんどWaitFreeで各種操作ができるらしい(難しくて読みきれていない)。
純粋にアルゴリズムとしてはほぼWaitFreeなのだろうが、実装・運用には向いてない気がする(Ex. 2N個のハッシュテーブル領域が必要、など)。
"Non-blocking hashtables with open addressing"
resizeはLock-freeでない。