1.3. Heap Table Structure
This section explains the internal layout of a heap table and the mechanism of TOAST (The Oversized-Attribute Storage Technique).
1.3.1. Internal Page Layout
Data files — including heap tables, indexes, free space maps, and visibility maps — are divided into pages (or blocks) of a fixed length, which defaults to 8192 bytes (8 KB). The pages within each file are numbered sequentially starting from 0; these identifiers are referred to as block numbers. When a file reaches its capacity, PostgreSQL appends a new, empty page to the end of the file to increase its size.
The internal layout of a page depends on the specific type of data file. This section focuses on the layout of heap tables, as this information is essential for understanding the concepts discussed in subsequent chapters.
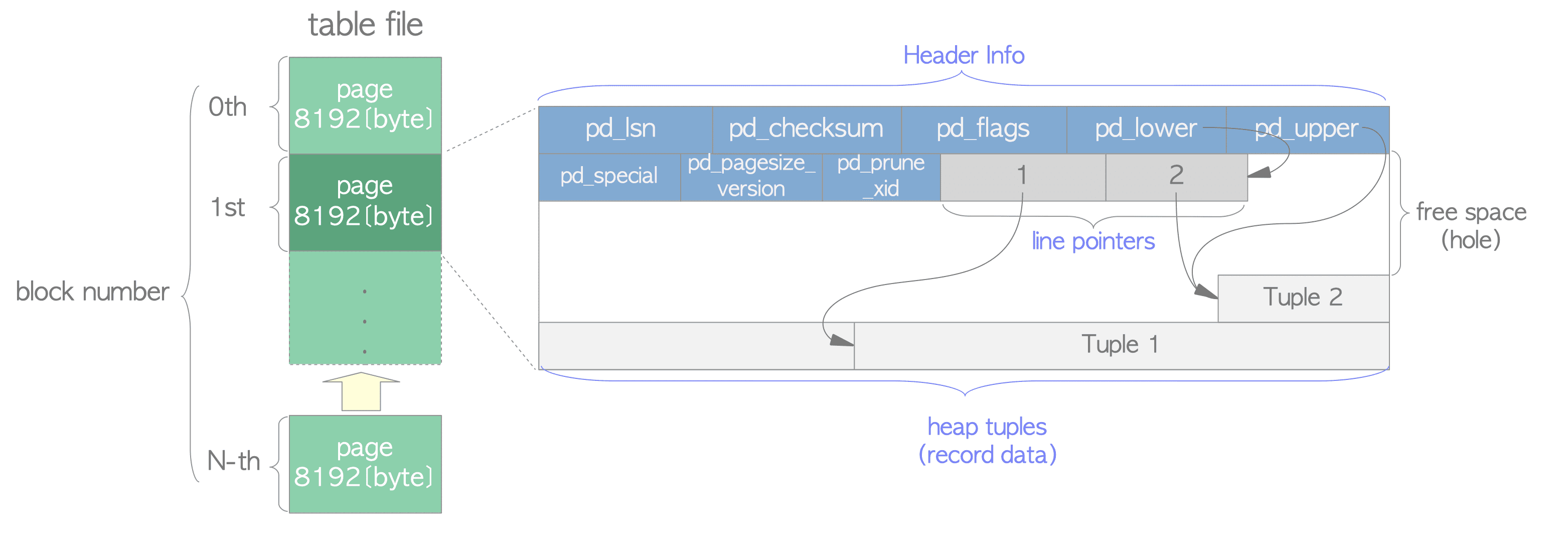
Figure 1.4. Page layout of a heap table file.
A page within a table contains three kinds of data:
-
heap tuple(s): A heap tuple represents the record data itself. Tuples are stacked sequentially from the bottom of the page.
The internal structure of tuple is described in Section 5.2 and Chapter 9, as understanding it requires prerequisite knowledge of both Concurrency Control (CC) and Write-Ahead Logging (WAL). -
line pointer(s): Each line pointer is 4 bytes long and holds a pointer to a specific heap tuple. It is also referred to as an item pointer.
Line pointers form a simple array that serves as an index to the tuples. Each element in the array is numbered sequentially starting from 1, referred to as the offset number. When a new tuple is added to the page, a corresponding line pointer is appended to the array to point to the new tuple. -
header data: Defined by the
PageHeaderDatastructure in bufpage.h, header data is allocated at the beginning of the page. It is 24 bytes long and contains general information about the page.
The major variables of the structure include:-
pd_lsn: This variable stores the Log Sequence Number (LSN) of XLOG record associated with the most recent change to this page. It is an 8-byte unsigned integer related to the WAL (Write-Ahead Logging) mechanism. Further details are available in Section 9.1.2.
-
pd_checksum: This variable stores the checksum value of the page. (Note: This variable is supported in versions 9.3 or later; in earlier versions, this field had stored pd_tli, which is the timelineId of the page.)
-
pd_lower, pd_upper: pd_lower points to the end of the line pointers, while pd_upper points to the beginning of the most recent heap tuple.
-
pd_special: This variable is utilized for indexes. In table pages, it points to the end of the page. (In index pages, it points to the beginning of the special space, a data area specific to index types such as B-tree, GiST, GIN, etc.)
-
The empty space between the end of the line pointers and the beginning of the most recent tuple is referred to as free space or the hole.
To identify a specific tuple within a table, a tuple identifier (TID) is used internally. A TID comprises a pair of values: the block number of the page containing the tuple and the offset number of the line pointer pointing to that tuple. TIDs are commonly used in indexes; see Section 1.4.2 for further details.
In the field of computer science, this type of page is called a slotted page, and the line pointers correspond to a slot array.
1.3.2. TOAST (The Oversized-Attribute Storage Technique)
Heap tuples that exceed approximately 2 KB — specifically, the default TOAST_TUPLE_THRESHOLD of 2,032 bytes — are managed using a mechanism called TOAST.
If a data item still exceeds this 2 KB threshold even after compression, PostgreSQL creates a dedicated TOAST table and a corresponding TOAST index for that specific table. The actual data is stored within the TOAST table, while the parent table stores only a pointer referencing the TOAST entry.
1.3.2.1. Practical Example
To demonstrate this mechanism, a table named tbl_toast is created.
testdb=# CREATE TABLE tbl_toast (id SERIAL PRIMARY KEY, data text);
testdb=# ALTER TABLE tbl_toast ALTER COLUMN data SET STORAGE EXTERNAL;A small string (‘abc’) is inserted into the first row, fitting within a standard page. For the second and third rows, approximately 10 KB of data is inserted into each.
testdb=# INSERT INTO tbl_toast (data) VALUES ('abc');
testdb=# INSERT INTO tbl_toast (data) SELECT repeat('abcdefghij', 1000) FROM generate_series(1, 2);In this case, the OID of tbl_toast is 16406.
testdb=# SELECT relname, oid, relfilenode FROM pg_class WHERE relname = 'tbl_toast';
relname | oid | relfilenode
-----------+-------+-------------
tbl_toast | 16406 | 16406
(1 row)Consequently, the corresponding TOAST table and its index are named pg_toast_16406 and pg_toast_16406_index, respectively.
testdb=# SELECT relname, relpages FROM pg_class
WHERE relname LIKE '%toast%16406%'
AND relnamespace = (SELECT oid FROM pg_namespace WHERE nspname = 'pg_toast');
relname | relpages
----------------------+----------
pg_toast_16406 | 0
pg_toast_16406_index | 1
(2 rows)The OIDs and physical file paths of these relations can be retrieved using the following query.
In this example, the paths are base/16384/16411 and base/16384/16412.
testdb=# \x
Expanded display is on.
testdb=# SELECT c.relname AS main_table, t.relname AS toast_table, t.oid AS toast_table_oid,
pg_relation_filepath(t.oid) AS physical_path,
i.relname AS toast_index, i.oid AS toast_index_oid,
pg_relation_filepath(i.oid) AS index_path
FROM pg_class c JOIN pg_class t ON c.reltoastrelid = t.oid
JOIN pg_index idx ON idx.indrelid = t.oid
JOIN pg_class i ON i.oid = idx.indexrelid WHERE c.relname = 'tbl_toast';
-[ RECORD 1 ]---+---------------------
main_table | tbl_toast
toast_table | pg_toast_16406
toast_table_oid | 16411
physical_path | base/16384/16411
toast_index | pg_toast_16406_index
toast_index_oid | 16412
index_path | base/16384/16412To demonstrate the TOAST mechanism, this example prevents data compression by adjusting storage parameters with the ALTER TABLE command.
PostgreSQL typically compresses data if its size exceeds 2 KB. The default compression method is pglz (PostgreSQL Lempel-Ziv).
1.3.2.2. Structural Analysis
Figure 1.5 illustrates the relationship between the main table tbl_toast and the TOAST table pg_toast_16406.
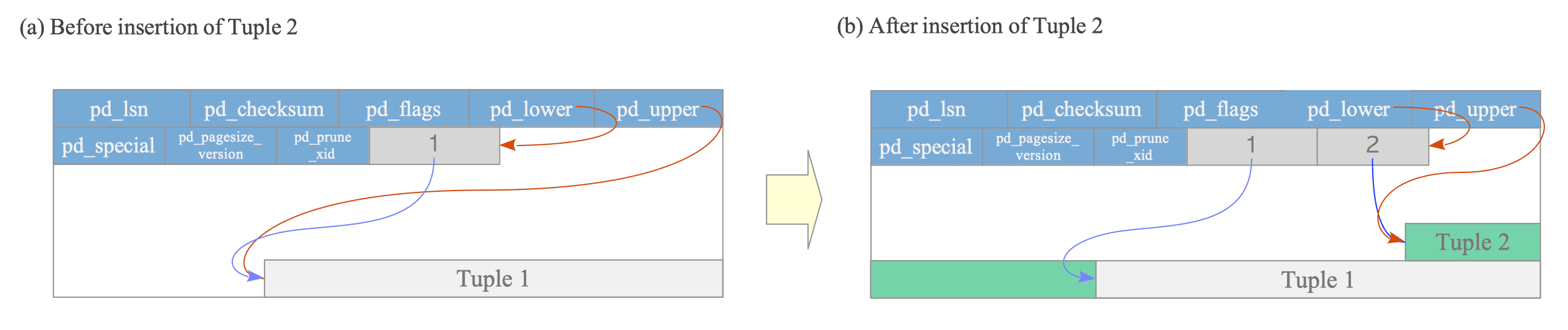
Figure 1.5: Structural mapping between the Main Table and its associated TOAST Table.
A single TOAST pointer logically references multiple chunk rows (chunk_seq 0 to 5) as a unified ‘data’ item.
Since the ‘data’ items in the second and third rows of tbl_toast are 10 KB, they are stored as TOAST pointers using the varatt_external structure instead of raw data.
The definition of the varatt_external structure is as follows:
typedef struct varatt_external
{
int32 va_rawsize; /* Original data size (includes header) */
uint32 va_extinfo; /* External saved size (without header) and compression method */
Oid va_valueid; /* Unique ID of value within TOAST table */
Oid va_toastrelid; /* RelID of TOAST table containing it */
} varatt_external;These four fields are described below:
- va_rawsize: The original data size, including the header.
- va_extinfo: The actual size stored externally (excluding the header) and the compression method used.
- va_valueid: A unique identifier for the value within the TOAST table, internally referred to as the chunk_id.
- va_toastrelid: The OID of the TOAST table containing the data.
The combination of va_valueid (chunk_id) and va_toastrelid functions as the actual pointer to the external data.
In this example, the va_valueid values for the second and third tuples are 16415 and 16416, respectively, while the va_toastrelid is 16411 (the OID of the TOAST table).
1.3.2.3. TOAST Table Content
A TOAST table consists of three columns: chunk_id, chunk_seq, and chunk_data.
- chunk_id: The identifier for the TOASTed data item from the original table.
- chunk_seq: A sequential number assigned when the TOASTed ‘data’ item is divided into multiple segments.
- chunk_data: The actual binary data segment.
The contents of pg_toast_16406 are displayed below:
testdb=# SELECT chunk_id, chunk_seq, chunk_data FROM pg_toast.pg_toast_16406;
chunk_id | chunk_seq | chunk_data
----------+-----------+-------------------------
16415 | 0 | \x616263646566.....6566
16415 | 1 | \x6768696a6162.....6162
16415 | 2 | \x636465666768.....6768
16415 | 3 | \x696a61626364.....6364
16415 | 4 | \x65666768696a.....696a
16415 | 5 | \x6162...696a
16416 | 0 | \x616263646566.....6566
16416 | 1 | \x6768696a6162.....6162
16416 | 2 | \x636465666768.....6768
16416 | 3 | \x696a61626364.....6364
16416 | 4 | \x65666768696a.....696a
16416 | 5 | \x6162...696a
(12 rows)The TOAST index utilizes chunk_id and chunk_seq as composite keys. When retrieving TOASTed data, the system performs an index scan on the TOAST index to fetch the corresponding chunk_data segments in the correct order.