10.2. How Point-in-Time Recovery Works
Figure 10.3 illustrates the basic concept of PITR.
In PITR mode, PostgreSQL replays WAL data from archive logs onto the base backup. This process starts at the REDO point created by pg_backup_start and continues up to a specified recovery point. This point is referred to as the recovery target.
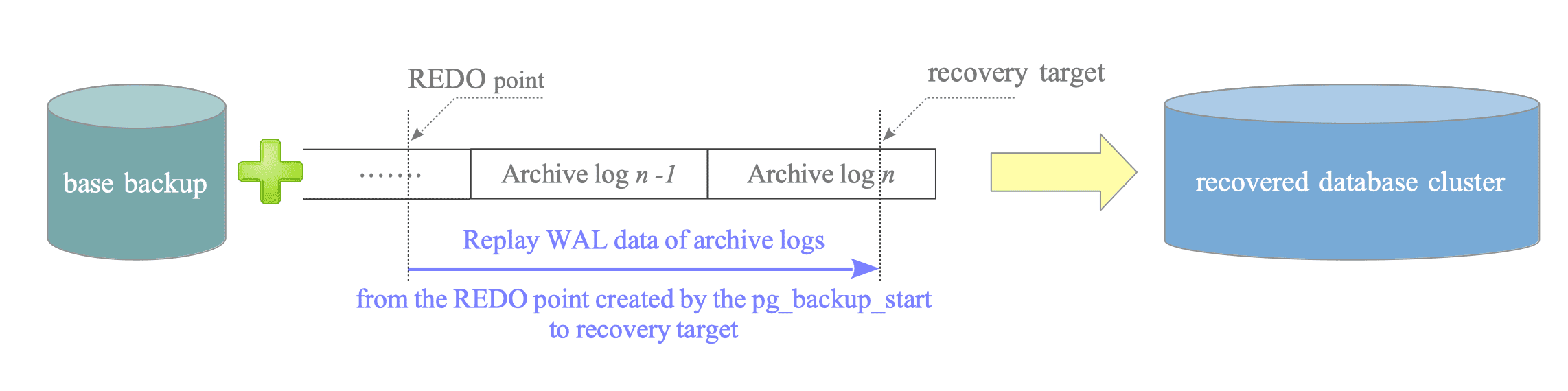
Figure 10.3. Basic concept of PITR.
The PITR process operates as follows:
Suppose a mistake occurs at 12:05 GMT on 1 January 2024. The database cluster should be removed, and a new one restored using a base backup created before that time.
To begin, configure the restore_command parameter and set the recovery_target_time parameter to the point of the error (12:05 GMT) in the postgresql.conf file (or recovery.conf for version 11 or earlier).
# Place archive logs under /mnt/server/archivedir directory.
restore_command = 'cp /mnt/server/archivedir/%f %p'
recovery_target_time = "2024-1-1 12:05 GMT"When PostgreSQL starts up, it enters PITR mode if the database cluster contains a backup_label file and a recovery.signal file (or recovery.conf in version 11 or earlier).
PostgreSQL 12 removed the recovery.conf file; all recovery parameters are now written in postgresql.conf.
For detailed information, refer to the official documentation.
In version 12 and later, restoring a server from a base backup requires an empty file named recovery.signal in the database cluster directory.
$ touch /usr/local/pgsql/data/recovery.signalThe Point-in-Time Recovery (PITR) process is almost identical to the normal recovery process described in Section 9.8. There are only two differences:
-
Source of WAL segments/Archive logs:
- Normal recovery mode: WAL segments are read from the pg_wal subdirectory (or pg_xlog in version 9.6 or earlier).
- PITR mode: WAL segments are read from the archival directory specified in the restore_command parameter.
-
Checkpoint location source:
- Normal recovery mode: The location is read from the pg_control file.
- PITR mode: The location is read from the backup_label file.
The outline of the PITR process is as follows:
-
PostgreSQL reads the ‘CHECKPOINT LOCATION’ from the backup_label file using the internal function read_backup_label() to find the REDO point.
-
PostgreSQL reads parameter values from postgresql.conf (or recovery.conf), such as restore_command and recovery_target_time.
-
PostgreSQL begins replaying WAL data from the REDO point obtained from the ‘CHECKPOINT LOCATION’. The system reads WAL data from archive logs by executing the restore_command. This command copies logs from the archival area to a temporary area. PostgreSQL removes the copied log files after use.
In this example, PostgreSQL replays WAL data from the REDO point up to the point immediately before ‘2024-1-1 12:05:00’. If no recovery target is set in postgresql.conf, PostgreSQL replays until the end of the archive logs.
-
When the recovery process completes, a timeline history file (e.g., 00000002.history) is created in the pg_wal subdirectory.
If the archiving feature is enabled, a copy is also created in the archival directory. Refer to Section 10.3.2 for details.
The records for commit and abort actions contain a timestamp indicating when each action occurred (defined in xl_xact_commit and xl_xact_abort).
Therefore, if a recovery_target_time is set, PostgreSQL decides whether to continue recovery whenever it replays a commit or abort record. PostgreSQL compares the target time with the timestamp in the record; if the timestamp exceeds the target time, the PITR process finishes.