9.7. Checkpoint Processing in PostgreSQL
In PostgreSQL, the checkpointer (background) process performs checkpoints. It starts when one of the following occurs:
-
The interval time set for checkpoint_timeout from the previous checkpoint has been elapsed (the default interval is 300 seconds).
-
In versions 9.4 or earlier, the number of WAL segment files set for checkpoint_segments has been consumed since the previous checkpoint (the default number is 3).
-
In versions 9.5 or later, the total size of the WAL segment files in the pg_wal (in versions 9.6 or earlier, pg_xlog) directory has exceeded the value of the parameter max_wal_size (the default value is 1GB (64 files)).
-
The PostgreSQL server stops in smart or fast mode.
-
A superuser issues the CHECKPOINT command manually.
In versions 9.1 or earlier, as mentioned in Section 8.6, the background writer process did both checkpinting and dirty-page writing.
In the following subsections, the outline of checkpointing and the pg_control file, which holds the metadata of the current checkpoint, are described.
9.7.1. Outline of the Checkpoint Processing
The checkpoint process has two aspects: preparing for database recovery, and cleaning dirty pages in the shared buffer pool. In this subsection, we will focus on the former aspect and describe its internal processing. See Figure 9.18 for an overview.
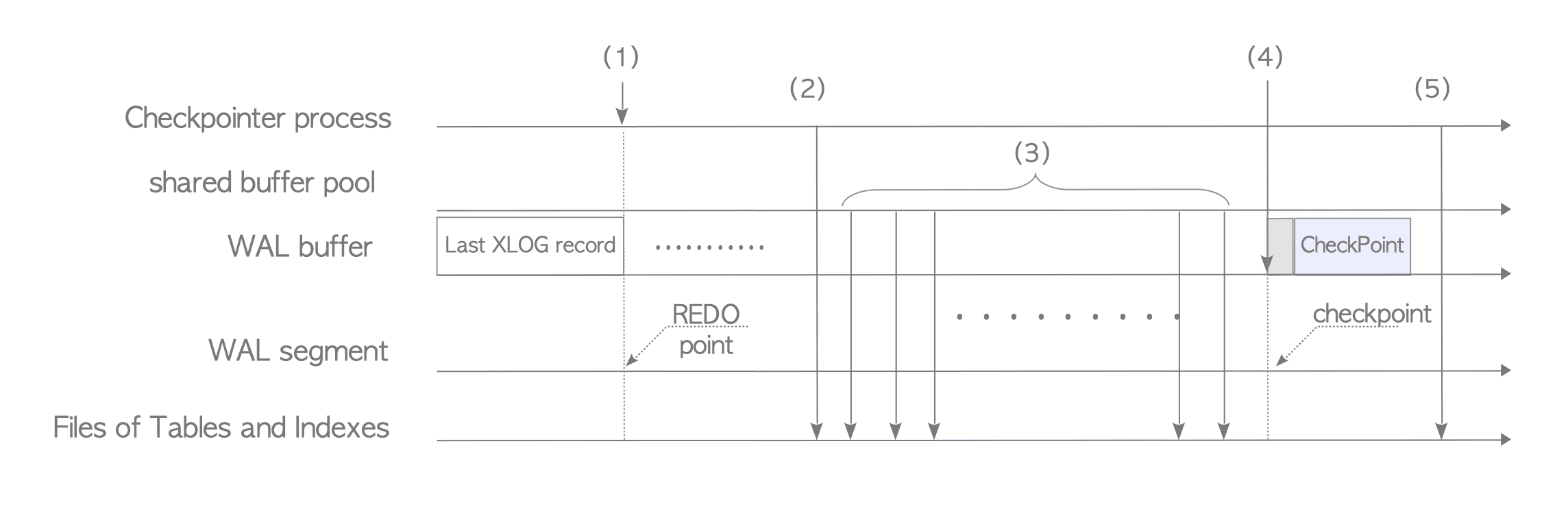
Figure 9.18. Internal processing of PostgreSQL Checkpoint.
-
When a checkpoint process starts, the REDO point is stored in memory. The REDO point is the location of the XLOG record written at the moment this checkpoint process began. It is the starting point for database recovery.
-
All data in shared memory (e.g., the contents of the clog, etc..) is flushed to the storage.
-
All dirty pages in the shared buffer pool are gradually written and flushed to the storage.
-
A XLOG record of this checkpoint (i.e., the checkpoint record) is written to the WAL buffer. The data-portion of the record is defined by the
CheckPointstructure, which contains several variables such as the REDO point stored in step (1).
The location where the checkpoint record is written is also called the checkpoint. -
The pg_control file is updated. This file contains fundamental information such as the location where the checkpoint record was written (a.k.a. the checkpoint location). We will discuss this file in more detail later.
To summarize the description above from the perspective of database recovery, checkpointing creates a checkpoint record that contains the REDO point, and stores the checkpoint location and other information in the pg_control file. This allows PostgreSQL to recover itself by replaying WAL data from the REDO point (obtained from the checkpoint record) provided by the pg_control file.
9.7.2. pg_control File
As the pg_control file contains the fundamental information of the checkpoint, it is essential for database recovery. If it is corrupted or unreadable, the recovery process cannot start because it cannot obtain a starting point.
Even though pg_control file stores over 40 items, three items that will be needed in the next section are shown below:
-
State – The state of the database server at the time the latest checkpoint was started. There are seven states in total:
- ‘start up’ is the state that system is starting up.
- ‘shut down’ is the state that the system is going down normally by the shutdown command.
- ‘in production’ is the state that the system is running. and so on.
-
Latest checkpoint location – The LSN Location of the latest checkpoint record.
-
Prior checkpoint location – The LSN Location of the prior checkpoint record. Note that this is deprecated in version 11; the details are described in below.
A pg_control file is stored in the global subdirectory under the base-directory. Its contents can be shown using the pg_controldata utility.
$ pg_controldata /usr/local/pgsql/data
pg_control version number: 1300
Catalog version number: 202306141
Database system identifier: 7250496631638317596
Database cluster state: in production
pg_control last modified: Mon Jan 1 15:16:38 2024
Latest checkpoint location: 0/16AF0090
Latest checkpoint's REDO location: 0/16AF0090
Latest checkpoint's REDO WAL file: 000000010000000000000016
... snip ...PostgreSQL 11 or later only stores the WAL segments that contain the latest checkpoint or newer. Older segment files, which contains the prior checkpoint, are not stored to reduce the disk space used for saving WAL segment files under the pg_wal subdirectory. See this thread in details.