6.1. Outline of VACUUM Processing
Vacuum processing performs the following tasks for specified tables or all tables in the database:
-
Removing dead tuples
- Remove dead tuples and defragment live tuples for each page.
- Remove index tuples that point to dead tuples.
-
Freezing old txids
- Freeze old txids of tuples if necessary.
- Update frozen txid related system catalogs (pg_database and pg_class).
- Remove unnecessary parts of the clog if possible.
-
Others
- Update the FSM and VM of processed tables.
- Update several statistics (pg_stat_all_tables, etc.).
This documentation assumes familiarity with the following terms: dead tuples, freezing txid, FSM, and the clog.
Refer to Chapter 5 for details on these concepts. VM is introduced in Section 6.2.
The following pseudocode describes vacuum processing.
// Phase 1: initializing
(1) FOR each table
(2) Acquire a ShareUpdateExclusiveLock lock for the target table
/* The first block */
// Phase 2: Scan Heap
(3) Scan all pages to get all dead tuples, and freeze old tuples if necessary
// Phase 3: Vacuuming Indexes
(4) Remove the index tuples that point to the respective dead tuples if exists
/* The second block */
// Phase 4: Vacuuming Heap
(5) FOR each page of the table
(6) Remove the dead tuples, and Reallocate the live tuples in the page
(7) Update FSM and VM
END FOR
/* The third block */
// Phase 5: Cleaning up indexes
(8) Clean up indexes
// Phase 6: Truncating heap
(9) Truncate the last page if possible
(10) Update both the statistics and system catalogs of the target table
Release the ShareUpdateExclusiveLock lock
END FOR
/* Post-processing */
// Phase 7: Final Cleaning
(11) Update statistics and system catalogs
(12) Remove both unnecessary files and pages of the clog if possible- Get each table from the specified tables.
- Acquire a ShareUpdateExclusiveLock for the table. This lock allows concurrent reads from other transactions.
- Scan all pages to collect all dead tuples and freeze old tuples if necessary.
- Remove the index tuples that point to the respective dead tuples if they exist.
- Perform tasks (6) and (7) for each page of the table.
- Remove the dead tuples and reallocate the live tuples in the page.
- Update both the respective FSM and VM of the target table.
- Clean up the indexes using the index_vacuum_cleanup() function.
- Truncate the last page if it contains no tuples.
- Update the statistics and system catalogs related to vacuum processing for the target table.
- Update the overall statistics and system catalogs related to vacuum processing.
- Remove unnecessary files and pages of the clog if possible.
PostgreSQL divides the vacuum process into seven distinct phases. For clarity, this documentation explains the process using 3+1 simplified blocks.
The pseudocode illustrates how these seven phases correspond to the 3+1 blocks.
These blocks are outlined below.
The VACUUM command has supported the PARALLEL option since version 13. If this option is set and multiple indexes exist, the index vacuuming and index cleanup phases are processed in parallel.
This feature applies only to the VACUUM command and is not supported by autovacuum.
The phase column in the pg_stat_progress_vacuum view identifies the current phase of an active vacuum process.
testdb=# SELECT datname, relid, phase FROM pg_stat_progress_vacuum;
datname | relid | phase
---------+-------+---------------
testdb | 16415 | scanning heap
(1 row)6.1.1. First Block
This block performs freeze processing and removes index tuples that point to dead tuples.
PostgreSQL first scans the target table to build a list of dead tuples and freeze old tuples. The list is stored in local memory called maintenance_work_mem. Section 6.3 describes freeze processing.
After scanning, PostgreSQL removes index tuples by referring to the dead tuple list. Figure 6.1 shows an example of removing an index tuple that points to a dead tuple.
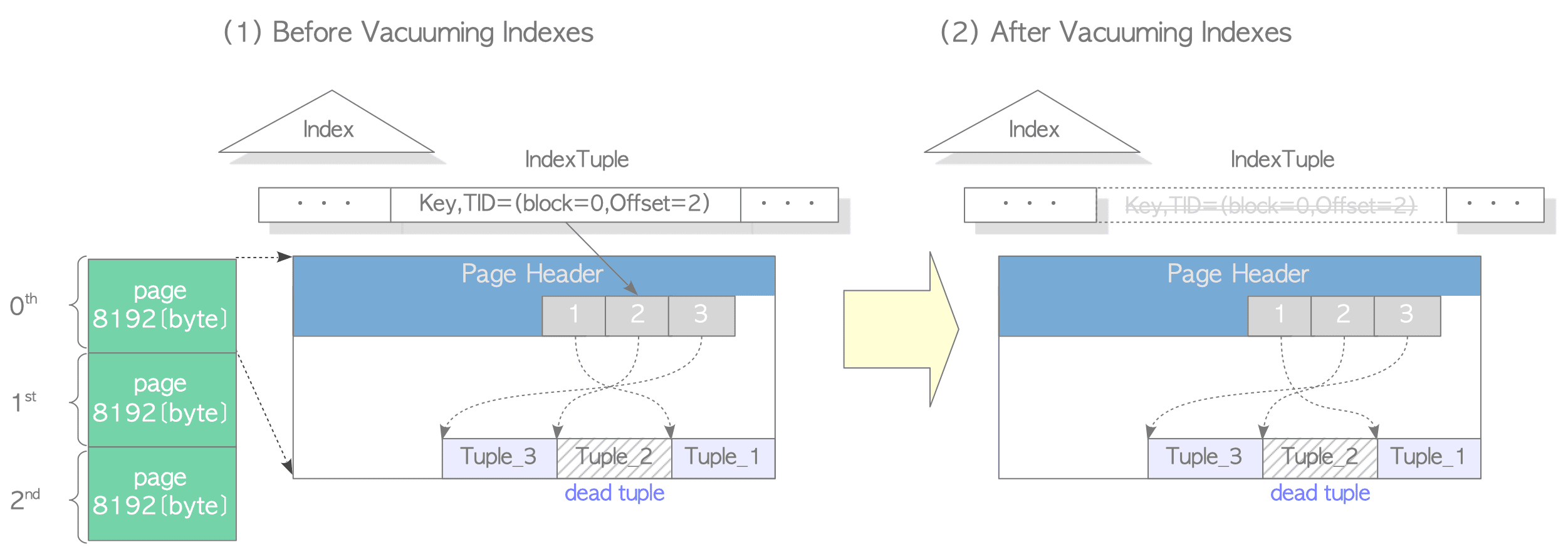
Figure 6.1. Vacuuming Indexes.
If maintenance_work_mem becomes full before scanning is complete, PostgreSQL proceeds to the next tasks (steps 4 to 7). It then returns to step (3) to continue the remainder of the scan.
6.1.2. Second Block
This block removes dead tuples and updates both the FSM and VM on a page-by-page basis. Figure 6.2 shows an example:
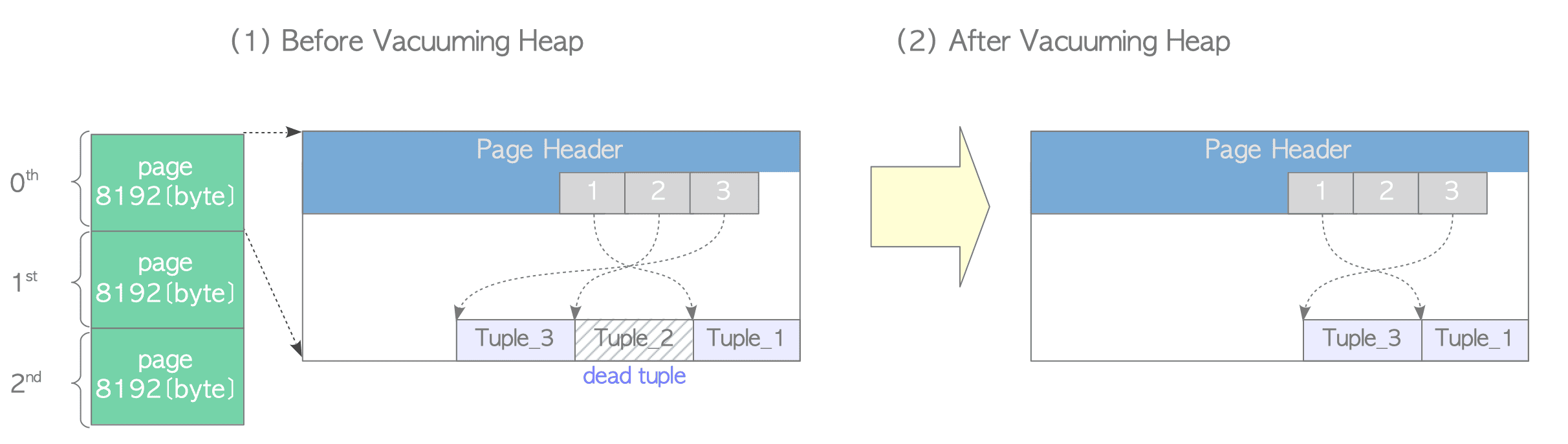
Figure 6.2. Vacuuming Heap.
Assume the table contains three pages. Focusing on the 0th page, there are three tuples, where Tuple_2 is dead (Figure 6.2(1)). PostgreSQL removes Tuple_2 and reorders the remaining tuples to repair fragmentation. It then updates both the FSM and VM for this page (Figure 6.2(2)). PostgreSQL continues this process until the last page.
Note that unnecessary line pointers are not removed; they are reused in the future. This is because if line pointers are removed, all index tuples of the associated indexes must be updated.
6.1.3. Third Block
The third block performs cleanup after index deletion and updates the statistics and system catalogs for each target table.
If the last pages contain no tuples, PostgreSQL truncates them from the table file. Figure 6.3 shows a slightly exaggerated example where the 1st, 3rd, and 4th pages contain no tuples after vacuuming the heap.
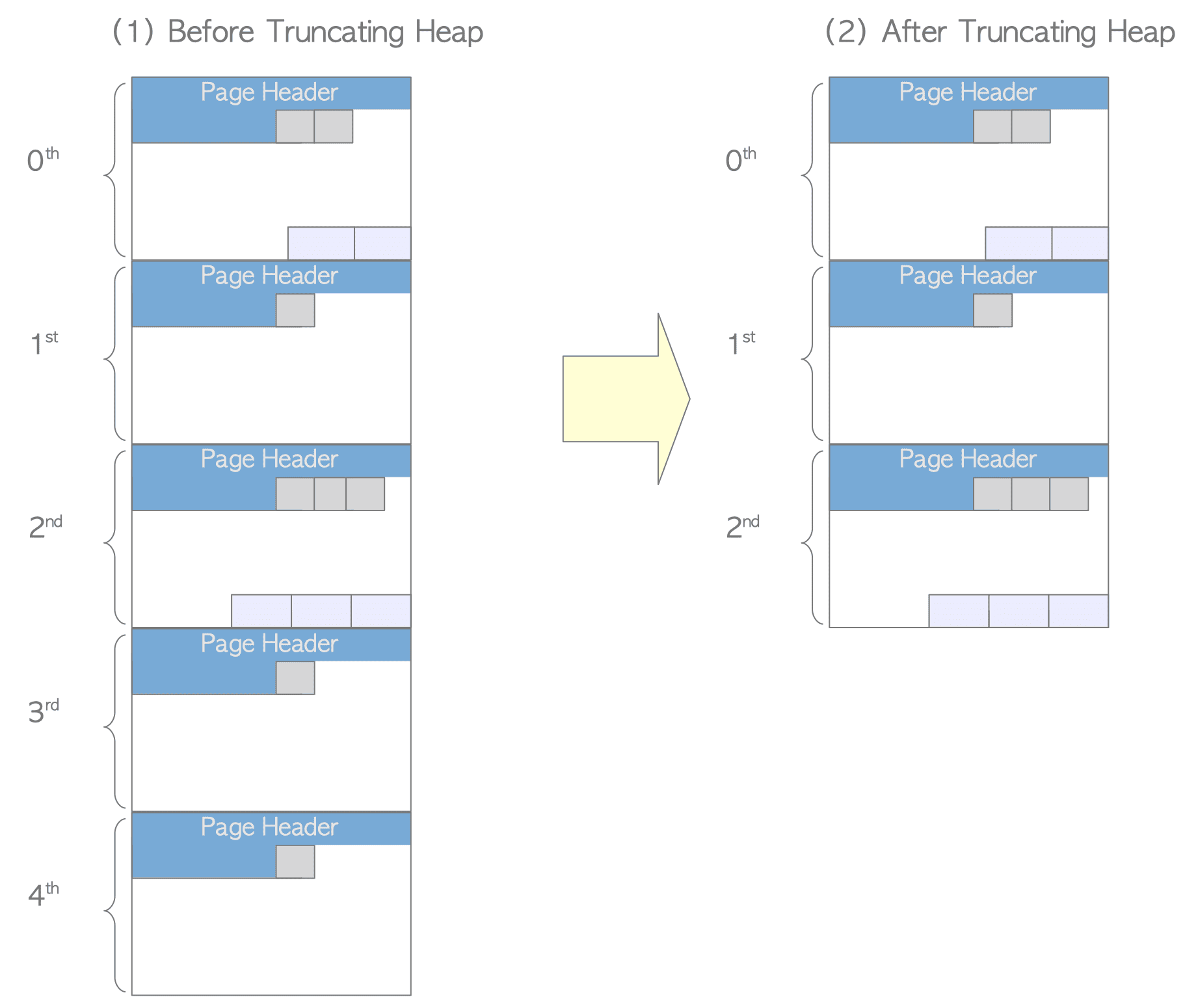
Figure 6.3. Truncating Pages.
During heap truncation, the 4th and 3rd pages are removed from the table file, reducing its size by 16 KB (8 KB $\times$ 2 pages).
Although the 1st page also contains no tuples, it is not removed1.
6.1.4. Post-processing
When vacuum processing is complete, PostgreSQL updates all statistics and system catalogs. It also removes unnecessary parts of the clog if possible (Section 6.4).
Vacuum processing uses a ring buffer, described in Section 8.4.3. Therefore, processed pages are not cached in the shared buffers.
-
To remove such internal pages, use REPACK (VACUUM FULL) command as explained in Section 6.6. ↩︎