1.4. The Methods of Writing and Reading Tuples
In the end of this chapter, the methods of writing and reading heap tuples are described.
1.4.1. Writing Heap Tuples
Suppose a table composed of one page that contains just one heap tuple. The pd_lower of this page points to the first line pointer, and both the line pointer and the pd_upper point to the first heap tuple. See Figure 1.6(a).
When the second tuple is inserted, it is placed after the first one. The second line pointer is appended to the first one, and it points to the second tuple. The pd_lower changes to point to the second line pointer, and the pd_upper to the second heap tuple. See Figure 1.6(b). Other header data within this page (e.g., pd_lsn, pg_checksum, pg_flag) are also updated to appropriate values; more details are described in Section 5.3 and Section 9.4.
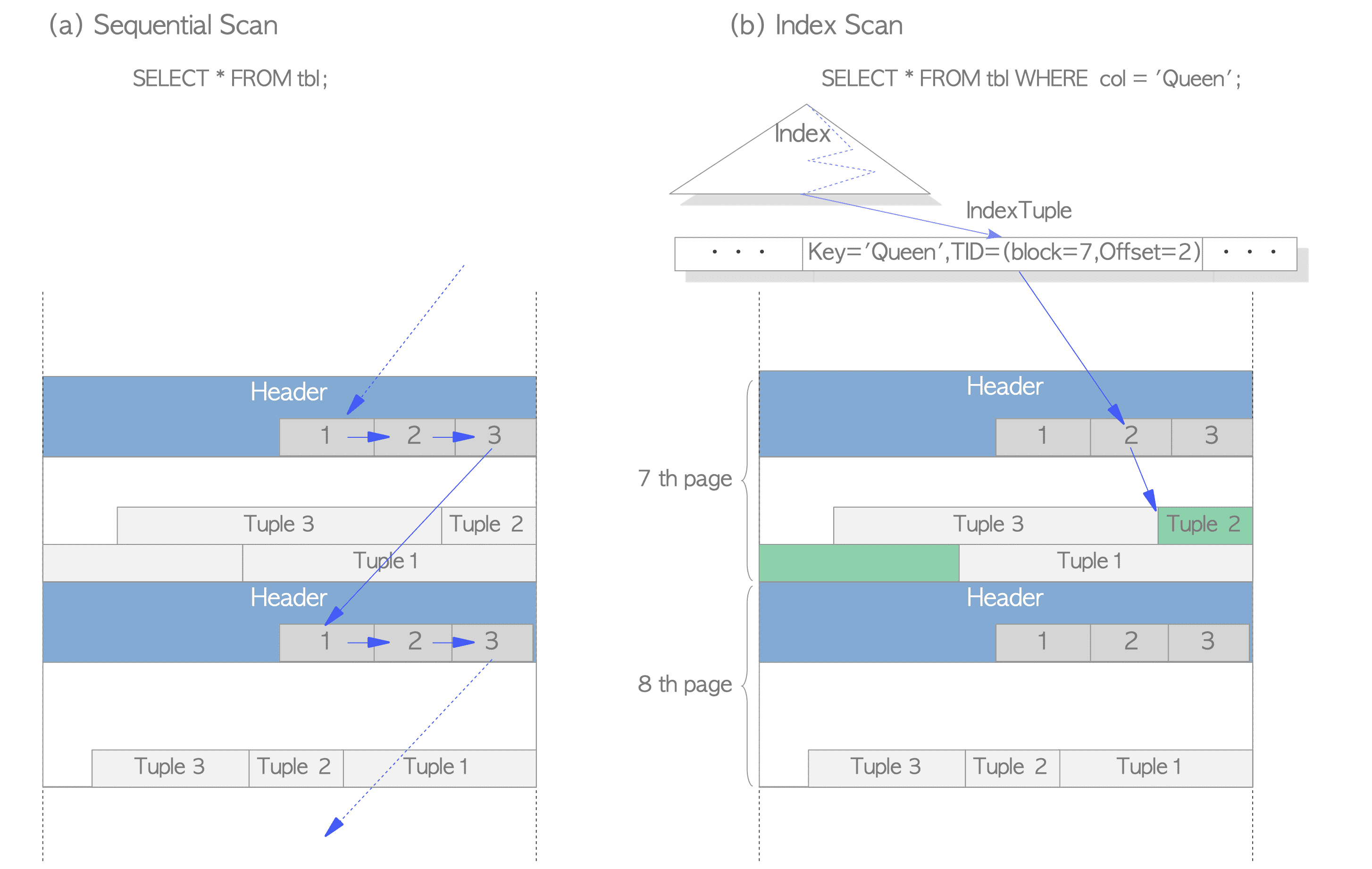
Figure 1.6. Writing of a heap tuple.
1.4.2. Reading Heap Tuples
Two typical access methods, sequential scan and B-tree index scan, are outlined here:
-
Sequential scan – It reads all tuples in all pages sequentially by scanning all line pointers in each page. See Figure 1.7(a).
-
B-tree index scan – It reads an index file that contains index tuples, each of which is composed of an index key and a TID that points to the target heap tuple.
If the index tuple with the key that you are looking for has been found1, PostgreSQL reads the desired heap tuple using the obtained TID value.
For example, in Figure 1.7(b), the TID value of the obtained index tuple is ‘(block = 7, Offset = 2)’. This means that the target heap tuple is the 2nd tuple in the 7th page within the table, so PostgreSQL can read the desired heap tuple without unnecessary scanning in the pages.

Figure 1.7. Sequential scan and index scan.
PostgreSQL also supports TID-Scan, Bitmap-Scan, and Index-Only-Scan.
TID-Scan is a method that accesses a tuple directly by using TID of the desired tuple. For example, to find the 1st tuple in the 0-th page within the table, issue the following query:
sampledb=# SELECT ctid, data FROM sampletbl WHERE ctid = '(0,1)';
ctid | data
-------+-----------
(0,1) | AAAAAAAAA
(1 row)Index-Only-Scan will be described in details in Section 7.2.
-
The description of how to find the index tuples in a B-tree index is not explained here, as it is very common and the space here is limited. See the relevant materials. ↩︎