11.4. Replication Slots
As discussed in Section 11.1.1, Replication slots, introduced in version 9.4, were designed primarily to ensure that WAL segments and old tuple versions are retained long enough to support replication completion.
We will explore replication slots in this section.
Note that although replication slots are fundamental to logical replication, this section does not cover them in that context.
11.4.1. Advantages of Replication Slots in Streaming Replication
In streaming replication, although replication slots are not mandatory, they offer the following advantages compared to using wal_keep_size:
-
Ensure Streaming Replication Works Without Losing Required WAL Segments:
Replication slots track which WAL segments are needed and prevent their removal. In contrast, when using only wal_keep_size, necessary segments may be removed if standbys do not read them for an extended period. -
Maintain Only the Minimum Necessary WAL Segments:
With replication slots, only the required WAL segments are kept in the pg_wal directory, while unnecessary segments are removed. Conversely, using wal_keep_size keeps a fixed number of WAL segments, regardless of whether they are needed or not.
Since Replication Slots can store WAL segments indefinitely, there is a risk of the storage area filling up with stored WAL segments in the worst-case scenario, potentially leading to an operating system panic.
To address this issue, the configuration parameter max_slot_wal_keep_size was introduced in version 13. It limits the maximum size of WAL segments in the pg_wal directory at checkpoint time.
The key difference between using max_slot_wal_keep_size with replication slots and wal_keep_size is in how they manage WAL segments:
- max_slot_wal_keep_size sets a maximum size limit for WAL segments while allowing replication slots to retain only the minimum required amount.
- wal_keep_size specifies a fixed number of WAL segments to be retained, regardless of whether they are needed or not.
11.4.2. Replication Slots and Related Processes and Files
Replication Slots are stored in the memory area allocated in the shared memory.
Figure 11.8 illustrates replication slots and the related processes and files:
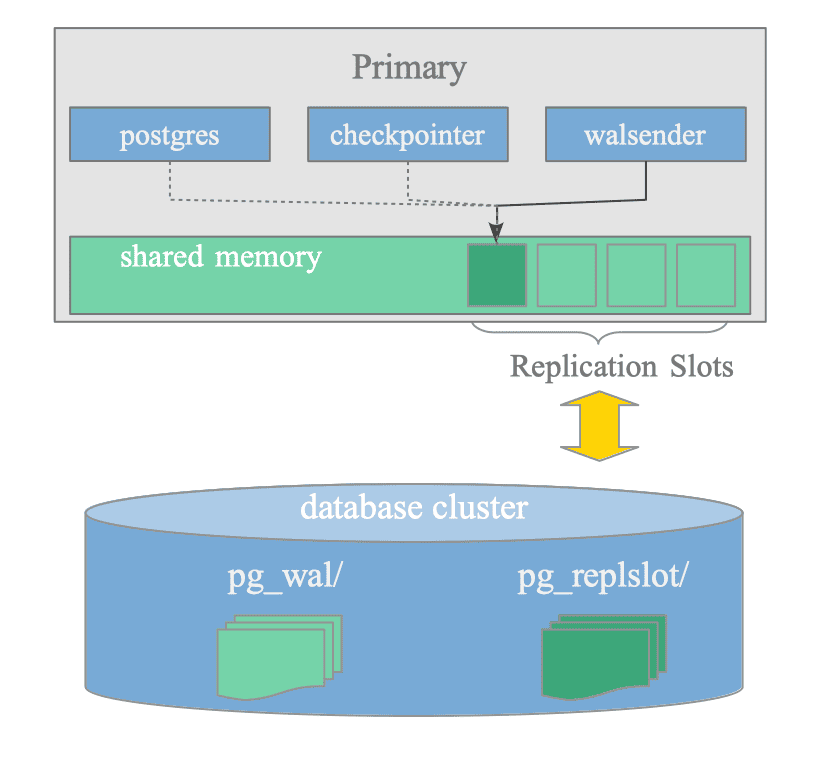
Figure 11.8. Replication Slots and Related Processes and Files.
Related Processes:
The processes related to Replication Slots are shown below:
-
Walsender: Continuously updates the corresponding replication slot to reflect the current state of WAL data of the standby server.
-
Checkpointer background worker: Reads the replication slots to determine whether WAL segments can be removed or not during checkpointing.
-
Postgres backend: Displays the slot information using the system view pg_replication_slots.
Related Files:
The files related to Replication Slots are shown below:
-
State files under the pg_replslot directory: Walsenders regularly save detailed information about their replication slots to state files located in this directory. When the server is restarted, it loads this saved information back into memory to restore the status of its replication slots.
The state is defined by theReplicationSlotPersistentDatastructure, described in the next section. -
WAL segment files under the pg_wal directory: The number of WAL segment files are managed by the checkpointer background worker. The checkpointer prioritizes Replication Slots and wal_keep_size over max_wal_size to ensure essential data is not removed.
11.4.3. Data Structure
Replication Slots are defined by the ReplicationSlot structure in slot.h.
Although the structure contains many items, as it is shared between both streaming and logical replication, the main items relevant to streaming replication are as follows:
- pid_t active_pid: The PID of the walsender process that manages this slot.
- ReplicationSlotPersistentData data: Items defined by
ReplicationSlotPersistentDatastructure. The main items include:- NameData name: The name of the slot.
- XLogRecPtr restart_lsn: The oldest LSN that might be required by this replication slot. The checkpointer reads the minimum restart_lsn value across all slots to determine whether WAL segments can be removed.
The data stored in ReplicationSlotPersistentData structure is regularly saved in the pg_replslot directory.
11.4.4. Starting Replication Slot
Figure 11.9 illustrates the starting sequence of a replication slot:
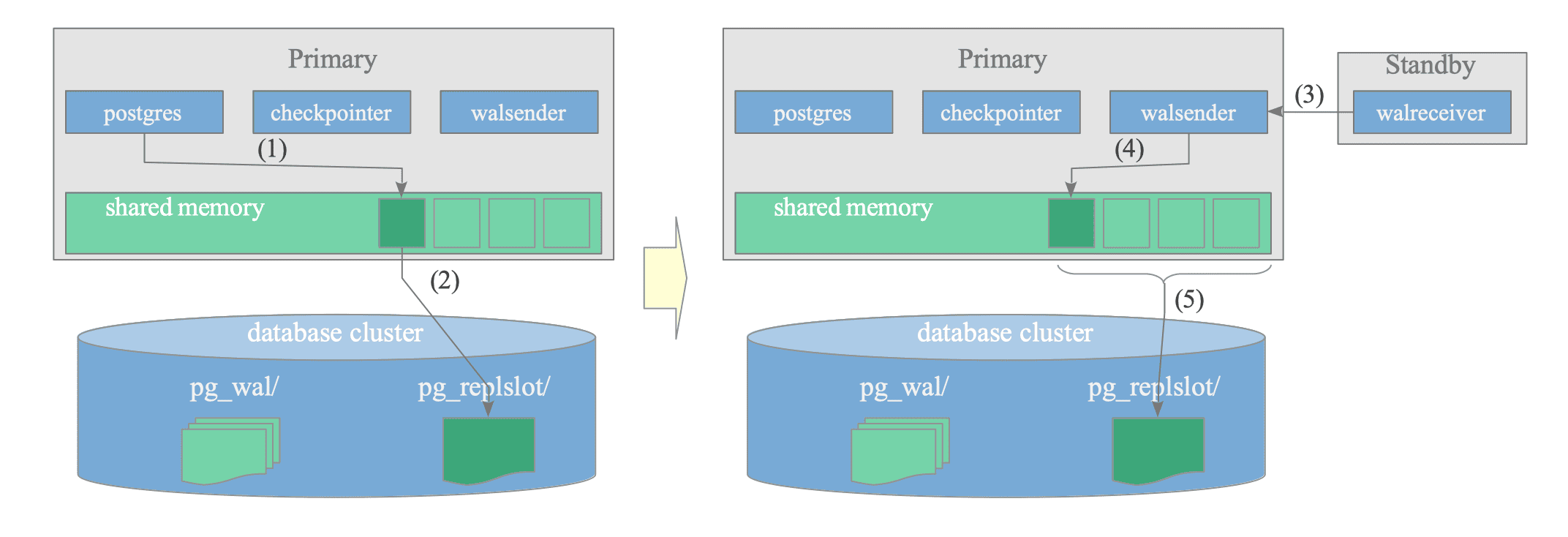
Figure 11.9. Starting Sequence of a Replication Slot.
-
Creating a (physical) replication slot using the pg_create_physical_replication_slot() function.
Except for the slot name, the data written to the replication slot is set to its default value.testdb=# SELECT * FROM pg_create_physical_replication_slot('standby_slot'); slot_name | lsn ---------------+----- standby_slot | (1 row) -
Writing a portion of the slot data, defined by the ReplicationSlotPersistentData structure, in the pg_replslot directory.
A file named state is created under the subdirectory corresponding to the slot name, as shown below:$ ls -1 pg_replslot/ standby_slot $ find pg_replslot/ pg_replslot/ pg_replslot/standby_slot pg_replslot/standby_slot/state -
(Re)Connecting standby server to the primary server.
To (re)connect the standby server to the primary server, set the primary_slot_name configuration parameter to the name of the replication slot.Then, issue the pg_ctl command with the reload option:# standby's postgresql.conf primary_slot_name = 'standby_slot'$ pg_ctl -D $PGDATA_STANDBY reload -
Updating the replication slot, e.g., active_pid, restart_lsn, etc.
-
Writing a portion of the updated slot data in the pg_replslot directory.
11.4.5. Managing Replication Slots
After replication slots are set in shared memory, walsender processes continuously update the slots to reflect the current states of the corresponding standby servers.
Below is an example of the states of the replication slots:
testdb=# \x
Expanded display is on.
testdb=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+--------------
slot_name | standby_slot
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 236772
xmin | 754
catalog_xmin |
restart_lsn | 0/303B968
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |
two_phase | f
inactive_since |
conflicting |
invalidation_reason |
failover | f
synced | fThe primary PostgreSQL server regularly saves detailed information about its replication slots to state files in the pg_replslot directory. (When the primary server restarts, it loads this saved information back into memory to restore the status of its replication slots.)