3.3. Creating the Plan Tree of a Single-Table Query
Because planner processing is highly complex, this section outlines the most fundamental case: the creation of a plan tree for a single-table query.
The more complex process of creating plan trees for multi-table queries is covered in Section 3.6.
The PostgreSQL planner performs the following three steps:
Preprocessing: Performs initial transformations and simplifications on the query.
Path Creation and Cost Estimation: Estimates the costs of all possible access paths to identify the cheapest option.
Plan Tree Creation: Creates the final plan tree based on the identified cheapest path.
An access path is a processing unit used exclusively during the cost estimation phase.
For example, sequential scans, index scans, sorting, and various join operations each have corresponding paths.
These paths exist only within the planner to facilitate the selection of an optimal plan; they are not used during the actual execution.
The most fundamental data structure for access paths is the Path structure, defined in pathnodes.h,
which corresponds to a sequential scan.
All other access paths are extensions or variations of this base structure.
typedefstruct PathKey
{
pg_node_attr(no_read, no_query_jumble)
NodeTag type;
/* the value that is ordered */ EquivalenceClass *pk_eclass pg_node_attr(copy_as_scalar, equal_as_scalar);
Oid pk_opfamily; /* index opfamily defining the ordering */ CompareType pk_cmptype; /* sort direction (ASC or DESC) */bool pk_nulls_first; /* do NULLs come before normal values? */} PathKey;
typedefstruct Path
{
pg_node_attr(no_copy_equal, no_read, no_query_jumble)
NodeTag type;
/* tag identifying scan/join method */ NodeTag pathtype;
/*
* the relation this path can build
*
* We do NOT print the parent, else we'd be in infinite recursion. We can
* print the parent's relids for identification purposes, though.
*/ RelOptInfo *parent pg_node_attr(write_only_relids);
/*
* list of Vars/Exprs, cost, width
*
* We print the pathtarget only if it's not the default one for the rel.
*/ PathTarget *pathtarget pg_node_attr(write_only_nondefault_pathtarget);
/*
* parameterization info, or NULL if none
*
* We do not print the whole of param_info, since it's printed via
* RelOptInfo; it's sufficient and less cluttering to print just the
* required outer relids.
*/ ParamPathInfo *param_info pg_node_attr(write_only_req_outer);
/* engage parallel-aware logic? */bool parallel_aware;
/* OK to use as part of parallel plan? */bool parallel_safe;
/* desired # of workers; 0 = not parallel */int parallel_workers;
/* estimated size/costs for path (see costsize.c for more info) */ Cardinality rows; /* estimated number of result tuples */int disabled_nodes; /* count of disabled nodes */ Cost startup_cost; /* cost expended before fetching any tuples */ Cost total_cost; /* total cost (assuming all tuples fetched) *//* sort ordering of path's output; a List of PathKey nodes; see above */ List *pathkeys;
} Path;
To manage these steps, the planner internally maintains a PlannerInfo structure,
which holds the query tree, metadata regarding the relations involved, and the candidate access paths.
/*----------
* PlannerInfo
* Per-query information for planning/optimization
*
* This struct is conventionally called "root" in all the planner routines.
* It holds links to all of the planner's working state, in addition to the
* original Query. Note that at present the planner extensively modifies
* the passed-in Query data structure; someday that should stop.
*
* For reasons explained in optimizer/optimizer.h, we define the typedef
* either here or in that header, whichever is read first.
*
* Not all fields are printed. (In some cases, there is no print support for
* the field type; in others, doing so would lead to infinite recursion or
* bloat dump output more than seems useful.)
*
* NOTE: When adding new entries containing relids and relid bitmapsets,
* remember to check that they will be correctly processed by
* the remove_self_join_rel function - relid of removing relation will be
* correctly replaced with the keeping one.
*----------
*/#ifndef HAVE_PLANNERINFO_TYPEDEF
typedefstruct PlannerInfo PlannerInfo;
#define HAVE_PLANNERINFO_TYPEDEF 1
#endif
struct PlannerInfo
{
pg_node_attr(no_copy_equal, no_read, no_query_jumble)
NodeTag type;
/* the Query being planned */ Query *parse;
/* global info for current planner run */ PlannerGlobal *glob;
/* 1 at the outermost Query */ Index query_level;
/* NULL at outermost Query */ PlannerInfo *parent_root pg_node_attr(read_write_ignore);
/*
* plan_params contains the expressions that this query level needs to
* make available to a lower query level that is currently being planned.
* outer_params contains the paramIds of PARAM_EXEC Params that outer
* query levels will make available to this query level.
*//* list of PlannerParamItems, see below */ List *plan_params;
Bitmapset *outer_params;
/*
* simple_rel_array holds pointers to "base rels" and "other rels" (see
* comments for RelOptInfo for more info). It is indexed by rangetable
* index (so entry 0 is always wasted). Entries can be NULL when an RTE
* does not correspond to a base relation, such as a join RTE or an
* unreferenced view RTE; or if the RelOptInfo hasn't been made yet.
*/struct RelOptInfo **simple_rel_array pg_node_attr(array_size(simple_rel_array_size));
/* allocated size of array */int simple_rel_array_size;
/*
* simple_rte_array is the same length as simple_rel_array and holds
* pointers to the associated rangetable entries. Using this is a shade
* faster than using rt_fetch(), mostly due to fewer indirections. (Not
* printed because it'd be redundant with parse->rtable.)
*/ RangeTblEntry **simple_rte_array pg_node_attr(read_write_ignore);
/*
* append_rel_array is the same length as the above arrays, and holds
* pointers to the corresponding AppendRelInfo entry indexed by
* child_relid, or NULL if the rel is not an appendrel child. The array
* itself is not allocated if append_rel_list is empty. (Not printed
* because it'd be redundant with append_rel_list.)
*/struct AppendRelInfo **append_rel_array pg_node_attr(read_write_ignore);
/*
* all_baserels is a Relids set of all base relids (but not joins or
* "other" rels) in the query. This is computed in deconstruct_jointree.
*/ Relids all_baserels;
/*
* outer_join_rels is a Relids set of all outer-join relids in the query.
* This is computed in deconstruct_jointree.
*/ Relids outer_join_rels;
/*
* all_query_rels is a Relids set of all base relids and outer join relids
* (but not "other" relids) in the query. This is the Relids identifier
* of the final join we need to form. This is computed in
* deconstruct_jointree.
*/ Relids all_query_rels;
/*
* join_rel_list is a list of all join-relation RelOptInfos we have
* considered in this planning run. For small problems we just scan the
* list to do lookups, but when there are many join relations we build a
* hash table for faster lookups. The hash table is present and valid
* when join_rel_hash is not NULL. Note that we still maintain the list
* even when using the hash table for lookups; this simplifies life for
* GEQO.
*/ List *join_rel_list;
struct HTAB *join_rel_hash pg_node_attr(read_write_ignore);
/*
* When doing a dynamic-programming-style join search, join_rel_level[k]
* is a list of all join-relation RelOptInfos of level k, and
* join_cur_level is the current level. New join-relation RelOptInfos are
* automatically added to the join_rel_level[join_cur_level] list.
* join_rel_level is NULL if not in use.
*
* Note: we've already printed all baserel and joinrel RelOptInfos above,
* so we don't dump join_rel_level or other lists of RelOptInfos.
*//* lists of join-relation RelOptInfos */ List **join_rel_level pg_node_attr(read_write_ignore);
/* index of list being extended */int join_cur_level;
/* init SubPlans for query */ List *init_plans;
/*
* per-CTE-item list of subplan IDs (or -1 if no subplan was made for that
* CTE)
*/ List *cte_plan_ids;
/* List of Lists of Params for MULTIEXPR subquery outputs */ List *multiexpr_params;
/* list of JoinDomains used in the query (higher ones first) */ List *join_domains;
/* list of active EquivalenceClasses */ List *eq_classes;
/* set true once ECs are canonical */bool ec_merging_done;
/* list of "canonical" PathKeys */ List *canon_pathkeys;
/*
* list of OuterJoinClauseInfos for mergejoinable outer join clauses
* w/nonnullable var on left
*/ List *left_join_clauses;
/*
* list of OuterJoinClauseInfos for mergejoinable outer join clauses
* w/nonnullable var on right
*/ List *right_join_clauses;
/*
* list of OuterJoinClauseInfos for mergejoinable full join clauses
*/ List *full_join_clauses;
/* list of SpecialJoinInfos */ List *join_info_list;
/* counter for assigning RestrictInfo serial numbers */int last_rinfo_serial;
/*
* all_result_relids is empty for SELECT, otherwise it contains at least
* parse->resultRelation. For UPDATE/DELETE/MERGE across an inheritance
* or partitioning tree, the result rel's child relids are added. When
* using multi-level partitioning, intermediate partitioned rels are
* included. leaf_result_relids is similar except that only actual result
* tables, not partitioned tables, are included in it.
*//* set of all result relids */ Relids all_result_relids;
/* set of all leaf relids */ Relids leaf_result_relids;
/*
* list of AppendRelInfos
*
* Note: for AppendRelInfos describing partitions of a partitioned table,
* we guarantee that partitions that come earlier in the partitioned
* table's PartitionDesc will appear earlier in append_rel_list.
*/ List *append_rel_list;
/* list of RowIdentityVarInfos */ List *row_identity_vars;
/* list of PlanRowMarks */ List *rowMarks;
/* list of PlaceHolderInfos */ List *placeholder_list;
/* array of PlaceHolderInfos indexed by phid */struct PlaceHolderInfo **placeholder_array pg_node_attr(read_write_ignore, array_size(placeholder_array_size));
/* allocated size of array */int placeholder_array_size pg_node_attr(read_write_ignore);
/* list of ForeignKeyOptInfos */ List *fkey_list;
/* desired pathkeys for query_planner() */ List *query_pathkeys;
/* groupClause pathkeys, if any */ List *group_pathkeys;
/*
* The number of elements in the group_pathkeys list which belong to the
* GROUP BY clause. Additional ones belong to ORDER BY / DISTINCT
* aggregates.
*/int num_groupby_pathkeys;
/* pathkeys of bottom window, if any */ List *window_pathkeys;
/* distinctClause pathkeys, if any */ List *distinct_pathkeys;
/* sortClause pathkeys, if any */ List *sort_pathkeys;
/* set operator pathkeys, if any */ List *setop_pathkeys;
/* Canonicalised partition schemes used in the query. */ List *part_schemes pg_node_attr(read_write_ignore);
/* RelOptInfos we are now trying to join */ List *initial_rels pg_node_attr(read_write_ignore);
/*
* Upper-rel RelOptInfos. Use fetch_upper_rel() to get any particular
* upper rel.
*/ List *upper_rels[UPPERREL_FINAL +1] pg_node_attr(read_write_ignore);
/* Result tlists chosen by grouping_planner for upper-stage processing */struct PathTarget *upper_targets[UPPERREL_FINAL +1] pg_node_attr(read_write_ignore);
/*
* The fully-processed groupClause is kept here. It differs from
* parse->groupClause in that we remove any items that we can prove
* redundant, so that only the columns named here actually need to be
* compared to determine grouping. Note that it's possible for *all* the
* items to be proven redundant, implying that there is only one group
* containing all the query's rows. Hence, if you want to check whether
* GROUP BY was specified, test for nonempty parse->groupClause, not for
* nonempty processed_groupClause. Optimizer chooses specific order of
* group-by clauses during the upper paths generation process, attempting
* to use different strategies to minimize number of sorts or engage
* incremental sort. See preprocess_groupclause() and
* get_useful_group_keys_orderings() for details.
*
* Currently, when grouping sets are specified we do not attempt to
* optimize the groupClause, so that processed_groupClause will be
* identical to parse->groupClause.
*/ List *processed_groupClause;
/*
* The fully-processed distinctClause is kept here. It differs from
* parse->distinctClause in that we remove any items that we can prove
* redundant, so that only the columns named here actually need to be
* compared to determine uniqueness. Note that it's possible for *all*
* the items to be proven redundant, implying that there should be only
* one output row. Hence, if you want to check whether DISTINCT was
* specified, test for nonempty parse->distinctClause, not for nonempty
* processed_distinctClause.
*/ List *processed_distinctClause;
/*
* The fully-processed targetlist is kept here. It differs from
* parse->targetList in that (for INSERT) it's been reordered to match the
* target table, and defaults have been filled in. Also, additional
* resjunk targets may be present. preprocess_targetlist() does most of
* that work, but note that more resjunk targets can get added during
* appendrel expansion. (Hence, upper_targets mustn't get set up till
* after that.)
*/ List *processed_tlist;
/*
* For UPDATE, this list contains the target table's attribute numbers to
* which the first N entries of processed_tlist are to be assigned. (Any
* additional entries in processed_tlist must be resjunk.) DO NOT use the
* resnos in processed_tlist to identify the UPDATE target columns.
*/ List *update_colnos;
/*
* Fields filled during create_plan() for use in setrefs.c
*//* for GroupingFunc fixup (can't print: array length not known here) */ AttrNumber *grouping_map pg_node_attr(read_write_ignore);
/* List of MinMaxAggInfos */ List *minmax_aggs;
/* context holding PlannerInfo */ MemoryContext planner_cxt pg_node_attr(read_write_ignore);
/* # of pages in all non-dummy tables of query */ Cardinality total_table_pages;
/* tuple_fraction passed to query_planner */ Selectivity tuple_fraction;
/* limit_tuples passed to query_planner */ Cardinality limit_tuples;
/*
* Minimum security_level for quals. Note: qual_security_level is zero if
* there are no securityQuals.
*/ Index qual_security_level;
/* true if any RTEs are RTE_JOIN kind */bool hasJoinRTEs;
/* true if any RTEs are marked LATERAL */bool hasLateralRTEs;
/* true if havingQual was non-null */bool hasHavingQual;
/* true if any RestrictInfo has pseudoconstant = true */bool hasPseudoConstantQuals;
/* true if we've made any of those */bool hasAlternativeSubPlans;
/* true once we're no longer allowed to add PlaceHolderInfos */bool placeholdersFrozen;
/* true if planning a recursive WITH item */bool hasRecursion;
/*
* The rangetable index for the RTE_GROUP RTE, or 0 if there is no
* RTE_GROUP RTE.
*/int group_rtindex;
/*
* Information about aggregates. Filled by preprocess_aggrefs().
*//* AggInfo structs */ List *agginfos;
/* AggTransInfo structs */ List *aggtransinfos;
/* number of aggs with DISTINCT/ORDER BY/WITHIN GROUP */int numOrderedAggs;
/* does any agg not support partial mode? */bool hasNonPartialAggs;
/* is any partial agg non-serializable? */bool hasNonSerialAggs;
/*
* These fields are used only when hasRecursion is true:
*//* PARAM_EXEC ID for the work table */int wt_param_id;
/* a path for non-recursive term */struct Path *non_recursive_path;
/*
* These fields are workspace for createplan.c
*//* outer rels above current node */ Relids curOuterRels;
/* not-yet-assigned NestLoopParams */ List *curOuterParams;
/*
* These fields are workspace for setrefs.c. Each is an array
* corresponding to glob->subplans. (We could probably teach
* gen_node_support.pl how to determine the array length, but it doesn't
* seem worth the trouble, so just mark them read_write_ignore.)
*/bool*isAltSubplan pg_node_attr(read_write_ignore);
bool*isUsedSubplan pg_node_attr(read_write_ignore);
/* optional private data for join_search_hook, e.g., GEQO */void*join_search_private pg_node_attr(read_write_ignore);
/* Does this query modify any partition key columns? */bool partColsUpdated;
/* PartitionPruneInfos added in this query's plan. */ List *partPruneInfos;
};
The following examples illustrate the transformation of query trees into plan trees.
Before creating a plan tree, the planner performs preprocessing on the query tree stored in the PlannerInfo structure.
While preprocessing involves numerous operations, this subsection focuses on the primary steps relevant to single-table queries.
Additional preprocessing operations, such as those related to joins and subqueries, are detailed in Section 3.6.
The core preprocessing steps include:
Simplifying Target Lists and Clauses: The planner simplifies target lists, LIMIT clauses, and other expressions. For example, the eval_const_expressions() function, defined in clauses.c, performs constant folding by rewriting expressions such as “(1 + 2)” into “3”.
Normalizing Boolean Expressions: Boolean logic is simplified for efficiency; for instance, the double negation “NOT(NOT a)” is rewritten as “a”.
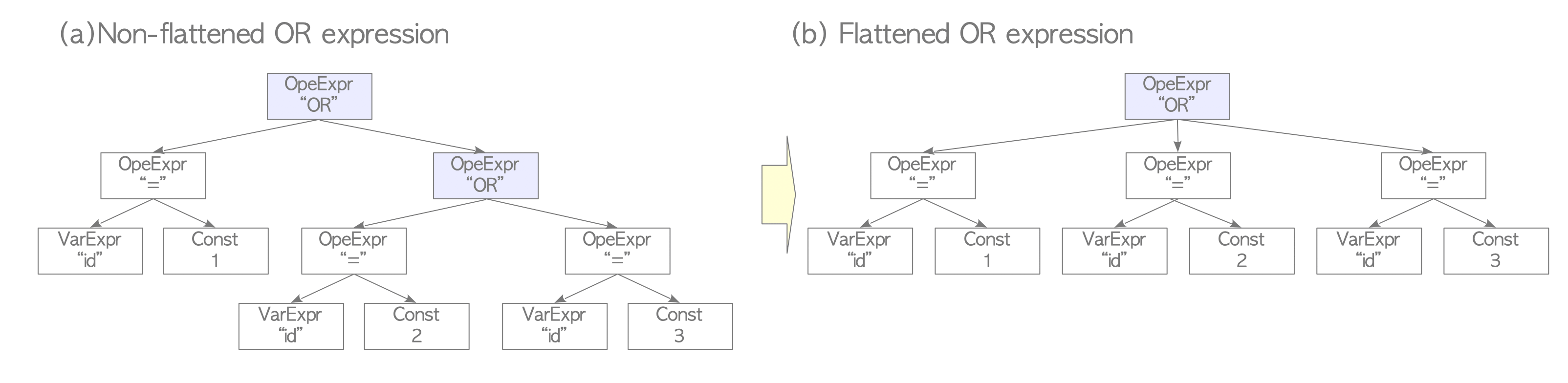
Flattening AND/OR Expressions: While the SQL standard defines AND and OR as binary operators, PostgreSQL treats them internally as n-ary operators. The planner assumes that all nested AND and OR expressions should be flattened to reduce tree depth and improve evaluation speed.
As a specific example, consider the Boolean expression “(id = 1) OR (id = 2) OR (id = 3)”.
Figure 3.9(a) illustrates the initial structure of the query tree using binary operators.
The planner simplifies this tree by flattening it into a single ternary operator, as shown in Figure 3.9(b).
Figure 3.9. An example of flattening AND/OR expressions.
3.3.2. Determining the Cheapest Access Path
To determine the cheapest access path, the planner estimates the costs of all possible access paths and selects the one with the lowest cost.
Specifically, the planner performs the following operations:
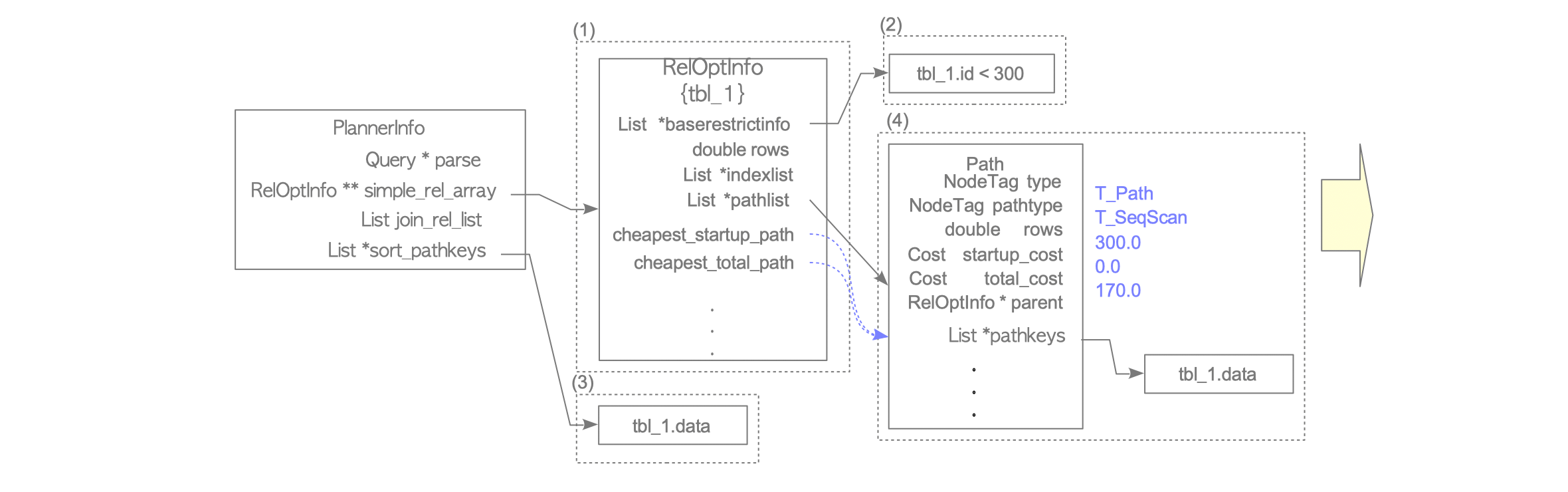
Create a RelOptInfo structure: The RelOptInfo structure is created by the make_one_rel() function and stored in the simple_rel_array of the PlannerInfo structure (see Figure 3.10).
In its initial state, RelOptInfo holds the baserestrictinfo — which contains the WHERE clauses of the query — and the indexlist, which stores metadata for any indexes associated with the target table.
typedefenum RelOptKind
{
RELOPT_BASEREL,
RELOPT_JOINREL,
RELOPT_OTHER_MEMBER_REL,
RELOPT_OTHER_JOINREL,
RELOPT_UPPER_REL,
RELOPT_OTHER_UPPER_REL
} RelOptKind;
/*
* Is the given relation a simple relation i.e a base or "other" member
* relation?
*/#define IS_SIMPLE_REL(rel) \
((rel)->reloptkind == RELOPT_BASEREL || \
(rel)->reloptkind == RELOPT_OTHER_MEMBER_REL)
/* Is the given relation a join relation? */#define IS_JOIN_REL(rel) \
((rel)->reloptkind == RELOPT_JOINREL || \
(rel)->reloptkind == RELOPT_OTHER_JOINREL)
/* Is the given relation an upper relation? */#define IS_UPPER_REL(rel) \
((rel)->reloptkind == RELOPT_UPPER_REL || \
(rel)->reloptkind == RELOPT_OTHER_UPPER_REL)
/* Is the given relation an "other" relation? */#define IS_OTHER_REL(rel) \
((rel)->reloptkind == RELOPT_OTHER_MEMBER_REL || \
(rel)->reloptkind == RELOPT_OTHER_JOINREL || \
(rel)->reloptkind == RELOPT_OTHER_UPPER_REL)
typedefstruct RelOptInfo
{
pg_node_attr(no_copy_equal, no_read, no_query_jumble)
NodeTag type;
RelOptKind reloptkind;
/*
* all relations included in this RelOptInfo; set of base + OJ relids
* (rangetable indexes)
*/ Relids relids;
/*
* size estimates generated by planner
*//* estimated number of result tuples */ Cardinality rows;
/*
* per-relation planner control flags
*//* keep cheap-startup-cost paths? */bool consider_startup;
/* ditto, for parameterized paths? */bool consider_param_startup;
/* consider parallel paths? */bool consider_parallel;
/*
* default result targetlist for Paths scanning this relation; list of
* Vars/Exprs, cost, width
*/struct PathTarget *reltarget;
/*
* materialization information
*/ List *pathlist; /* Path structures */ List *ppilist; /* ParamPathInfos used in pathlist */ List *partial_pathlist; /* partial Paths */struct Path *cheapest_startup_path;
struct Path *cheapest_total_path;
struct Path *cheapest_unique_path;
List *cheapest_parameterized_paths;
/*
* parameterization information needed for both base rels and join rels
* (see also lateral_vars and lateral_referencers)
*//* rels directly laterally referenced */ Relids direct_lateral_relids;
/* minimum parameterization of rel */ Relids lateral_relids;
/*
* information about a base rel (not set for join rels!)
*/ Index relid;
/* containing tablespace */ Oid reltablespace;
/* RELATION, SUBQUERY, FUNCTION, etc */ RTEKind rtekind;
/* smallest attrno of rel (often <0) */ AttrNumber min_attr;
/* largest attrno of rel */ AttrNumber max_attr;
/* array indexed [min_attr .. max_attr] */ Relids *attr_needed pg_node_attr(read_write_ignore);
/* array indexed [min_attr .. max_attr] */ int32 *attr_widths pg_node_attr(read_write_ignore);
/*
* Zero-based set containing attnums of NOT NULL columns. Not populated
* for rels corresponding to non-partitioned inh==true RTEs.
*/ Bitmapset *notnullattnums;
/* relids of outer joins that can null this baserel */ Relids nulling_relids;
/* LATERAL Vars and PHVs referenced by rel */ List *lateral_vars;
/* rels that reference this baserel laterally */ Relids lateral_referencers;
/* list of IndexOptInfo */ List *indexlist;
/* list of StatisticExtInfo */ List *statlist;
/* size estimates derived from pg_class */ BlockNumber pages;
Cardinality tuples;
double allvisfrac;
/* indexes in PlannerInfo's eq_classes list of ECs that mention this rel */ Bitmapset *eclass_indexes;
PlannerInfo *subroot; /* if subquery */ List *subplan_params; /* if subquery *//* wanted number of parallel workers */int rel_parallel_workers;
/* Bitmask of optional features supported by the table AM */ uint32 amflags;
/*
* Information about foreign tables and foreign joins
*//* identifies server for the table or join */ Oid serverid;
/* identifies user to check access as; 0 means to check as current user */ Oid userid;
/* join is only valid for current user */bool useridiscurrent;
/* use "struct FdwRoutine" to avoid including fdwapi.h here */struct FdwRoutine *fdwroutine pg_node_attr(read_write_ignore);
void*fdw_private pg_node_attr(read_write_ignore);
/*
* cache space for remembering if we have proven this relation unique
*//* known unique for these other relid set(s) given in UniqueRelInfo(s) */ List *unique_for_rels;
/* known not unique for these set(s) */ List *non_unique_for_rels;
/*
* used by various scans and joins:
*//* RestrictInfo structures (if base rel) */ List *baserestrictinfo;
/* cost of evaluating the above */ QualCost baserestrictcost;
/* min security_level found in baserestrictinfo */ Index baserestrict_min_security;
/* RestrictInfo structures for join clauses involving this rel */ List *joininfo;
/* T means joininfo is incomplete */bool has_eclass_joins;
/*
* used by partitionwise joins:
*//* consider partitionwise join paths? (if partitioned rel) */bool consider_partitionwise_join;
/*
* inheritance links, if this is an otherrel (otherwise NULL):
*//* Immediate parent relation (dumping it would be too verbose) */struct RelOptInfo *parent pg_node_attr(read_write_ignore);
/* Topmost parent relation (dumping it would be too verbose) */struct RelOptInfo *top_parent pg_node_attr(read_write_ignore);
/* Relids of topmost parent (redundant, but handy) */ Relids top_parent_relids;
/*
* used for partitioned relations:
*//* Partitioning scheme */ PartitionScheme part_scheme pg_node_attr(read_write_ignore);
/*
* Number of partitions; -1 if not yet set; in case of a join relation 0
* means it's considered unpartitioned
*/int nparts;
/* Partition bounds */struct PartitionBoundInfoData *boundinfo pg_node_attr(read_write_ignore);
/* True if partition bounds were created by partition_bounds_merge() */bool partbounds_merged;
/* Partition constraint, if not the root */ List *partition_qual;
/*
* Array of RelOptInfos of partitions, stored in the same order as bounds
* (don't print, too bulky and duplicative)
*/struct RelOptInfo **part_rels pg_node_attr(read_write_ignore);
/*
* Bitmap with members acting as indexes into the part_rels[] array to
* indicate which partitions survived partition pruning.
*/ Bitmapset *live_parts;
/* Relids set of all partition relids */ Relids all_partrels;
/*
* These arrays are of length partkey->partnatts, which we don't have at
* hand, so don't try to print
*//* Non-nullable partition key expressions */ List **partexprs pg_node_attr(read_write_ignore);
/* Nullable partition key expressions */ List **nullable_partexprs pg_node_attr(read_write_ignore);
} RelOptInfo;
Estimate costs and add the access paths: The planner evaluates all potential access methods through the following sub-steps:
Sequential Scan: A path is created for a sequential scan, its cost is estimated, and the path is added to the pathlist of the RelOptInfo structure.
Index Scan: If relevant indexes exist, index access paths are created. The planner estimates the costs for these index scans and adds the resulting paths to the pathlist.
Bitmap Scan: If a bitmap scan is feasible, corresponding paths are created. Their costs are estimated and added to the pathlist.
Select the cheapest path: The planner compares all entries in the pathlist of the RelOptInfo structure and selects the one with the cheapest total cost.
Estimate auxiliary costs: If the query includes LIMIT, ORDER BY, or AGGREGATE functions, the planner estimates the additional costs associated with these operations and updates the plan accordingly.
The following two examples illustrate this process in detail.
3.3.2.1. Example 1
This example explores a simple single-table query without indexes.
The query contains both WHERE and ORDER BY clauses:
testdb=#\d tbl_1
Table"public.tbl_1"Column|Type| Modifiers
--------+---------+-----------
id | integer |data| integer |testdb=#SELECT*FROM tbl_1 WHERE id <300ORDERBYdata;
Figures 3.10 and 3.11 illustrate the planner’s operations for this query.
Figure 3.10. How to identify the cheapest path of Example 1
Create the RelOptInfo structure: The planner creates a RelOptInfo structure and stores it in the simple_rel_array of the PlannerInfo.
Add the WHERE clause to baserestrictinfo: The clause “id < 300” is added to the baserestrictinfo by the distribute_restrictinfo_to_rels() function (defined in initsplan.c). Since the target table has no indexes, the indexlist of the RelOptInfo remains NULL.
Add the pathkey for sorting to sort_pathkeys: The standard_qp_callback() function (defined in planner.c) adds the relevant pathkeys to the sort_pathkeys of the PlannerInfo. A pathkey is a data structure representing the sort order for a path. In this example, the column ‘data’ is added as a pathkey because of the ORDER BY clause.
Estimate the Sequential Scan cost: The planner creates a Path structure and estimates the sequential scan cost using the cost_seqscan() function. These estimated costs are written into the path, which is then added to the RelOptInfo by the add_path() function (defined in pathnode.c).
Because no indexes exist, the sequential scan is the only available access method,
making it the automatically determined cheapest access path for the base relation.
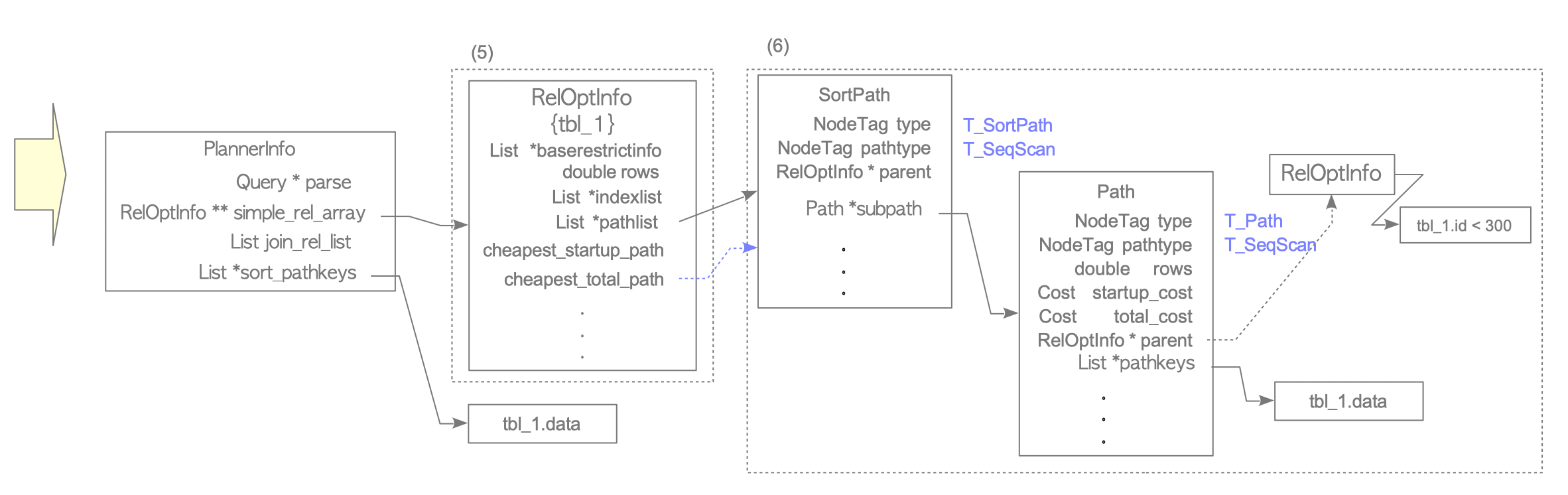
Figure 3.11. How to identify the cheapest path of Example 1. (continued from Figure 3.10)
Create a new RelOptInfo for sorting: A new RelOptInfo structure is created specifically to process the ORDER BY procedure. Note that this new structure does not contain the baserestrictinfo (the WHERE clause information).
Create and link the SortPath: A SortPath structure is created and added to the new RelOptInfo. The SortPath consists of two primary components: the path itself (storing sort operation metadata) and a subpath (pointing to the cheapest underlying access path).
Even though the new RelOptInfo lacks the baserestrictinfo, the parent field of the sequential scan path maintains a link to the original RelOptInfo.
Consequently, during the plan tree creation stage (described in Section 3.3.3),
the planner can correctly attach the WHERE clause to the sequential scan node as a ‘Filter’.
The final plan tree is created based on the cheapest access path identified here.
Details on this transformation are provided in Section 3.3.3.
3.3.2.2. Example 2
This example examines a single-table query on a table with two indexes. The query includes a WHERE clause:
testdb=#\d tbl_2
Table"public.tbl_2"Column|Type| Modifiers
--------+---------+-----------
id | integer |notnulldata| integer |Indexes:
"tbl_2_pkey"PRIMARYKEY, btree (id)
"tbl_2_data_idx" btree (data)
testdb=#SELECT*FROM tbl_2 WHERE id <240;
Figures 3.12 through 3.14 illustrate the planner’s operations for this query.
Figure 3.12. How to identify the cheapest path of Example 2.
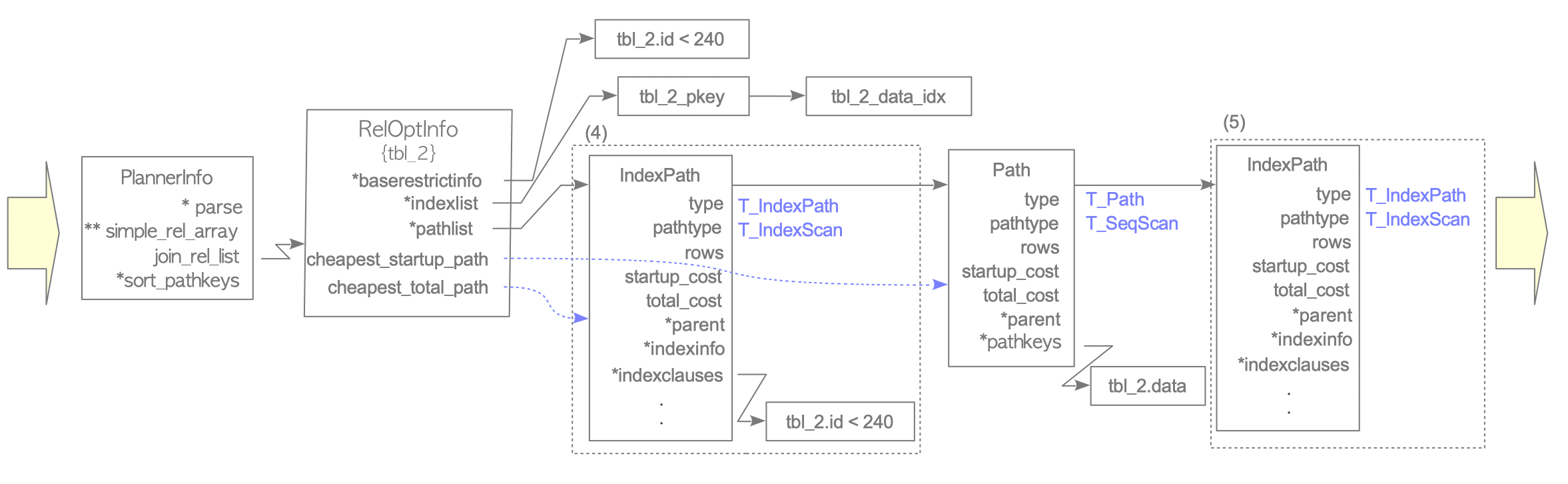
Create the RelOptInfo structure: The planner initializes a RelOptInfo structure for the target table.
Add baserestrictinfo and indexlist: The WHERE clause “id < 240” is added to the baserestrictinfo. Simultaneously, metadata for the two indexes – tbl_2_pkey and tbl_2_data_idx – is added to the indexlist.
Estimate the Sequential Scan cost: The planner creates a Path for a sequential scan, estimates its cost, and adds it to the pathlist of the RelOptInfo.
Figure 3.13. How to identify the cheapest path of Example 2. (continued from Figure 3.12)
Create and evaluate the first IndexPath: The planner processes the indexes in the indexlist sequentially. First, it creates an IndexPath for tbl_2_pkey. Since tbl_2_pkey is defined on the column ‘id’ and the WHERE clause filters by that same column, the clause is stored in the indexclauses field of the IndexPath.
The add_path() function then evaluates this path. If its total cost is lower than the existing sequential scan path, it is inserted at the beginning of the pathlist.
typedefstruct IndexPath
{
Path path;
IndexOptInfo *indexinfo;
List *indexclauses;
List *indexorderbys;
List *indexorderbycols;
ScanDirection indexscandir;
Cost indextotalcost;
Selectivity indexselectivity;
} IndexPath;
/*
* IndexOptInfo
* Per-index information for planning/optimization
*
* indexkeys[] and canreturn[] each have ncolumns entries.
*
* indexcollations[], opfamily[], and opcintype[] each have nkeycolumns
* entries. These don't contain any information about INCLUDE columns.
*
* sortopfamily[], reverse_sort[], and nulls_first[] have
* nkeycolumns entries, if the index is ordered; but if it is unordered,
* those pointers are NULL.
*
* Zeroes in the indexkeys[] array indicate index columns that are
* expressions; there is one element in indexprs for each such column.
*
* For an ordered index, reverse_sort[] and nulls_first[] describe the
* sort ordering of a forward indexscan; we can also consider a backward
* indexscan, which will generate the reverse ordering.
*
* The indexprs and indpred expressions have been run through
* prepqual.c and eval_const_expressions() for ease of matching to
* WHERE clauses. indpred is in implicit-AND form.
*
* indextlist is a TargetEntry list representing the index columns.
* It provides an equivalent base-relation Var for each simple column,
* and links to the matching indexprs element for each expression column.
*
* While most of these fields are filled when the IndexOptInfo is created
* (by plancat.c), indrestrictinfo and predOK are set later, in
* check_index_predicates().
*/#ifndef HAVE_INDEXOPTINFO_TYPEDEF
typedefstruct IndexOptInfo IndexOptInfo;
#define HAVE_INDEXOPTINFO_TYPEDEF 1
#endif
struct IndexPath; /* forward declaration */struct IndexOptInfo
{
pg_node_attr(no_copy_equal, no_read, no_query_jumble)
NodeTag type;
/* OID of the index relation */ Oid indexoid;
/* tablespace of index (not table) */ Oid reltablespace;
/* back-link to index's table; don't print, else infinite recursion */ RelOptInfo *rel pg_node_attr(read_write_ignore);
/*
* index-size statistics (from pg_class and elsewhere)
*//* number of disk pages in index */ BlockNumber pages;
/* number of index tuples in index */ Cardinality tuples;
/* index tree height, or -1 if unknown */int tree_height;
/*
* index descriptor information
*//* number of columns in index */int ncolumns;
/* number of key columns in index */int nkeycolumns;
/*
* table column numbers of index's columns (both key and included
* columns), or 0 for expression columns
*/int*indexkeys pg_node_attr(array_size(ncolumns));
/* OIDs of collations of index columns */ Oid *indexcollations pg_node_attr(array_size(nkeycolumns));
/* OIDs of operator families for columns */ Oid *opfamily pg_node_attr(array_size(nkeycolumns));
/* OIDs of opclass declared input data types */ Oid *opcintype pg_node_attr(array_size(nkeycolumns));
/* OIDs of btree opfamilies, if orderable. NULL if partitioned index */ Oid *sortopfamily pg_node_attr(array_size(nkeycolumns));
/* is sort order descending? or NULL if partitioned index */bool*reverse_sort pg_node_attr(array_size(nkeycolumns));
/* do NULLs come first in the sort order? or NULL if partitioned index */bool*nulls_first pg_node_attr(array_size(nkeycolumns));
/* opclass-specific options for columns */ bytea **opclassoptions pg_node_attr(read_write_ignore);
/* which index cols can be returned in an index-only scan? */bool*canreturn pg_node_attr(array_size(ncolumns));
/* OID of the access method (in pg_am) */ Oid relam;
/*
* expressions for non-simple index columns; redundant to print since we
* print indextlist
*/ List *indexprs pg_node_attr(read_write_ignore);
/* predicate if a partial index, else NIL */ List *indpred;
/* targetlist representing index columns */ List *indextlist;
/*
* parent relation's baserestrictinfo list, less any conditions implied by
* the index's predicate (unless it's a target rel, see comments in
* check_index_predicates())
*/ List *indrestrictinfo;
/* true if index predicate matches query */bool predOK;
/* true if a unique index */bool unique;
/* true if the index was defined with NULLS NOT DISTINCT */bool nullsnotdistinct;
/* is uniqueness enforced immediately? */bool immediate;
/* true if index doesn't really exist */bool hypothetical;
/*
* Remaining fields are copied from the index AM's API struct
* (IndexAmRoutine). These fields are not set for partitioned indexes.
*/bool amcanorderbyop;
bool amoptionalkey;
bool amsearcharray;
bool amsearchnulls;
/* does AM have amgettuple interface? */bool amhasgettuple;
/* does AM have amgetbitmap interface? */bool amhasgetbitmap;
bool amcanparallel;
/* does AM have ammarkpos interface? */bool amcanmarkpos;
/* AM's cost estimator *//* Rather than include amapi.h here, we declare amcostestimate like this */void (*amcostestimate) (struct PlannerInfo *, struct IndexPath *, double, Cost *, Cost *, Selectivity *, double*, double*) pg_node_attr(read_write_ignore);
};
Create and evaluate subsequent IndexPaths: Next, an IndexPath is created for tbl_2_data_idx. However, because the query does not contain a filter related to the ‘data’ column, the indexclauses for this path remain NULL. The cost is estimated, and the path is passed to add_path().
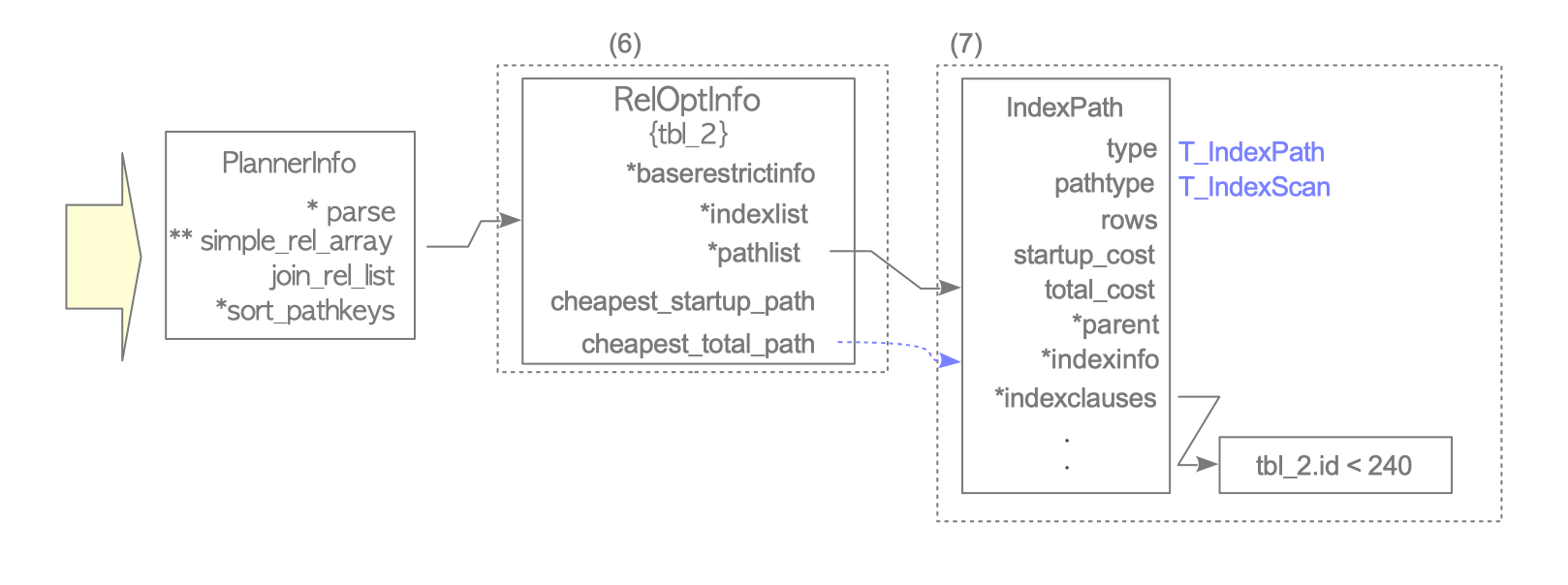
Figure 3.14. How to identify the cheapest path of Example 2. (continued from Figure 3.13)
Create a new RelOptInfo structure: A new RelOptInfo is initialized to finalize the selection process.
Select and store the cheapest path: In this example, the index scan using tbl_2_pkey is selected as the cheapest path. This path is consequently added to the pathlist of the new RelOptInfo as the optimal plan.
Note
The add_path() function does not necessarily add every path it receives.
It may discard a new path if it is significantly more expensive than an existing path with the same or better sort order (pathkeys).
Due to the complexity of this pruning logic, refer to the source code comments for add_path() for further details.
3.3.3. Creating a Plan Tree
In the final stage, the planner creates a plan tree based on the identified cheapest path.
The root of the plan tree is a PlannedStmt structure, defined in plannodes.h.
While it contains nineteen fields, four representative fields are described below:
commandType stores the type of operation, such as SELECT, UPDATE, or INSERT.
rtable stores the range table entries.
relationOids stores the OIDs of the tables related to the query.
plantree stores the actual plan tree, which is composed of various plan nodes.
typedefstruct PlannedStmt
{
pg_node_attr(no_equal, no_query_jumble)
NodeTag type;
/* select|insert|update|delete|merge|utility */ CmdType commandType;
/* query identifier (copied from Query) */ int64 queryId;
/* plan identifier (can be set by plugins) */ int64 planId;
/* is it insert|update|delete|merge RETURNING? */bool hasReturning;
/* has insert|update|delete|merge in WITH? */bool hasModifyingCTE;
/* do I set the command result tag? */bool canSetTag;
/* redo plan when TransactionXmin changes? */bool transientPlan;
/* is plan specific to current role? */bool dependsOnRole;
/* parallel mode required to execute? */bool parallelModeNeeded;
/* which forms of JIT should be performed */int jitFlags;
/* tree of Plan nodes */struct Plan *planTree;
/*
* List of PartitionPruneInfo contained in the plan
*/ List *partPruneInfos;
/* list of RangeTblEntry nodes */ List *rtable;
/*
* RT indexes of relations that are not subject to runtime pruning or are
* needed to perform runtime pruning
*/ Bitmapset *unprunableRelids;
/*
* list of RTEPermissionInfo nodes for rtable entries needing one
*/ List *permInfos;
/* rtable indexes of target relations for INSERT/UPDATE/DELETE/MERGE *//* integer list of RT indexes, or NIL */ List *resultRelations;
/* list of AppendRelInfo nodes */ List *appendRelations;
/*
* Plan trees for SubPlan expressions; note that some could be NULL
*/ List *subplans;
/* indices of subplans that require REWIND */ Bitmapset *rewindPlanIDs;
/* a list of PlanRowMark's */ List *rowMarks;
/* OIDs of relations the plan depends on */ List *relationOids;
/* other dependencies, as PlanInvalItems */ List *invalItems;
/* type OIDs for PARAM_EXEC Params */ List *paramExecTypes;
/* non-null if this is utility stmt */ Node *utilityStmt;
/* statement location in source string (copied from Query) *//* start location, or -1 if unknown */ ParseLoc stmt_location;
/* length in bytes; 0 means "rest of string" */ ParseLoc stmt_len;
} PlannedStmt;
Each node in the plan tree corresponds to a specific operation, such as a sequential scan, sort, or index scan.
The PlanNode structure serves as the base node, and all other specific plan nodes (such as SeqScan or Sort) begin with a Plan field.
For example, ScanNode, which is an abstract type that all relation-scan plan types inherit from, consists of a Plan structure followed by the integer variable scanrelid.
The PlanNode structure contains fourteen fields, including the following seven representative fields:
startup_cost and total_cost represent the estimated costs for the operation corresponding to the node.
plan_rows is the estimated number of rows to be scanned.
targetlist stores the target list items retrieved from the query tree.
qual is a list of qualifier conditions (filters) to be applied.
lefttree and righttree are pointers to child nodes, enabling the hierarchical structure of the tree.
/* ----------------
* Plan node
*
* All plan nodes "derive" from the Plan structure by having the
* Plan structure as the first field. This ensures that everything works
* when nodes are cast to Plan's. (node pointers are frequently cast to Plan*
* when passed around generically in the executor)
*
* We never actually instantiate any Plan nodes; this is just the common
* abstract superclass for all Plan-type nodes.
* ----------------
*/typedefstruct Plan
{
pg_node_attr(abstract, no_equal, no_query_jumble)
NodeTag type;
/*
* estimated execution costs for plan (see costsize.c for more info)
*//* count of disabled nodes */int disabled_nodes;
/* cost expended before fetching any tuples */ Cost startup_cost;
/* total cost (assuming all tuples fetched) */ Cost total_cost;
/*
* planner's estimate of result size of this plan step
*//* number of rows plan is expected to emit */ Cardinality plan_rows;
/* average row width in bytes */int plan_width;
/*
* information needed for parallel query
*//* engage parallel-aware logic? */bool parallel_aware;
/* OK to use as part of parallel plan? */bool parallel_safe;
/*
* information needed for asynchronous execution
*//* engage asynchronous-capable logic? */bool async_capable;
/*
* Common structural data for all Plan types.
*//* unique across entire final plan tree */int plan_node_id;
/* target list to be computed at this node */ List *targetlist;
/* implicitly-ANDed qual conditions */ List *qual;
/* input plan tree(s) */struct Plan *lefttree;
struct Plan *righttree;
/* Init Plan nodes (un-correlated expr subselects) */ List *initPlan;
/*
* Information for management of parameter-change-driven rescanning
*
* extParam includes the paramIDs of all external PARAM_EXEC params
* affecting this plan node or its children. setParam params from the
* node's initPlans are not included, but their extParams are.
*
* allParam includes all the extParam paramIDs, plus the IDs of local
* params that affect the node (i.e., the setParams of its initplans).
* These are _all_ the PARAM_EXEC params that affect this node.
*/ Bitmapset *extParam;
Bitmapset *allParam;
} Plan;
/*
* ==========
* Scan nodes
*
* Scan is an abstract type that all relation scan plan types inherit from.
* ==========
*/typedefstruct Scan
{
pg_node_attr(abstract)
Plan plan;
/* relid is index into the range table */ Index scanrelid;
} Scan;
/* ----------------
* sequential scan node
* ----------------
*/typedefstruct SeqScan
{
Scan scan;
} SeqScan;
The following sections describe the two plan trees created from the cheapest paths identified in the previous examples.
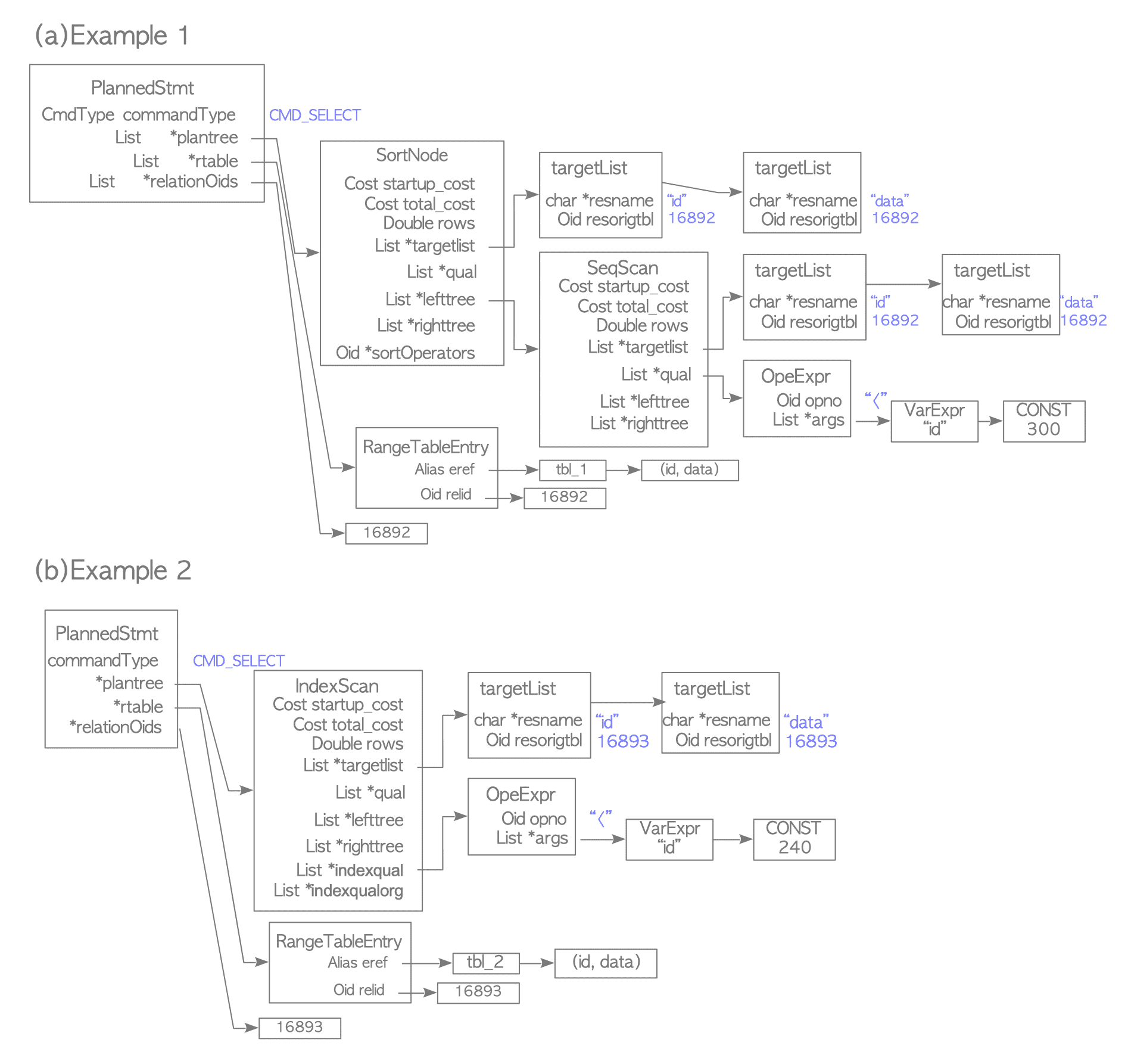
3.3.3.1. Example 1
This section describes the plan tree created for the query in Section 3.3.2.1.
The cheapest path, illustrated in Figure 3.11, consists of a SortPath as the root and a Sequential Scan Path as its child.
While the complex details of the transformation are omitted here,
the plan tree is created almost directly from the hierarchical structure of the cheapest path.
In this example, a SortNode is assigned to the plantree field of the PlannedStmt structure,
and a SeqScanNode is assigned to the lefttree of the Sort node. This structure is shown in Figure 3.15(a).
/* ----------------
* sort node
* ----------------
*/typedefstruct Sort
{
Plan plan;
/* number of sort-key columns */int numCols;
/* their indexes in the target list */ AttrNumber *sortColIdx pg_node_attr(array_size(numCols));
/* OIDs of operators to sort them by */ Oid *sortOperators pg_node_attr(array_size(numCols));
/* OIDs of collations */ Oid *collations pg_node_attr(array_size(numCols));
/* NULLS FIRST/LAST directions */bool*nullsFirst pg_node_attr(array_size(numCols));
} Sort;
Figure 3.15. Examples of plan trees.
In the SortNode, the lefttree pointer targets the SeqScanNode.
In the SeqScanNode, the qual field stores the WHERE clause “id < 300”.
3.3.3.2. Example 2
The second example describes the plan tree for the query in Section 3.3.2.2.
As illustrated in Figure 3.14, the cheapest path is an index scan path; therefore, the resulting plan tree consists solely of an IndexScanNode.
This is shown in Figure 3.15(b).
/* ----------------
* index scan node
*
* indexqualorig is an implicitly-ANDed list of index qual expressions, each
* in the same form it appeared in the query WHERE condition. Each should
* be of the form (indexkey OP comparisonval) or (comparisonval OP indexkey).
* The indexkey is a Var or expression referencing column(s) of the index's
* base table. The comparisonval might be any expression, but it won't use
* any columns of the base table. The expressions are ordered by index
* column position (but items referencing the same index column can appear
* in any order). indexqualorig is used at runtime only if we have to recheck
* a lossy indexqual.
*
* indexqual has the same form, but the expressions have been commuted if
* necessary to put the indexkeys on the left, and the indexkeys are replaced
* by Var nodes identifying the index columns (their varno is INDEX_VAR and
* their varattno is the index column number).
*
* indexorderbyorig is similarly the original form of any ORDER BY expressions
* that are being implemented by the index, while indexorderby is modified to
* have index column Vars on the left-hand side. Here, multiple expressions
* must appear in exactly the ORDER BY order, and this is not necessarily the
* index column order. Only the expressions are provided, not the auxiliary
* sort-order information from the ORDER BY SortGroupClauses; it's assumed
* that the sort ordering is fully determinable from the top-level operators.
* indexorderbyorig is used at runtime to recheck the ordering, if the index
* cannot calculate an accurate ordering. It is also needed for EXPLAIN.
*
* indexorderbyops is a list of the OIDs of the operators used to sort the
* ORDER BY expressions. This is used together with indexorderbyorig to
* recheck ordering at run time. (Note that indexorderby, indexorderbyorig,
* and indexorderbyops are used for amcanorderbyop cases, not amcanorder.)
*
* indexorderdir specifies the scan ordering, for indexscans on amcanorder
* indexes (for other indexes it should be "don't care").
* ----------------
*/typedefstruct Scan
{
pg_node_attr(abstract)
Plan plan;
Index scanrelid; /* relid is index into the range table */} Scan;
typedefstruct IndexScan
{
Scan scan;
/* OID of index to scan */ Oid indexid;
/* list of index quals (usually OpExprs) */ List *indexqual;
/* the same in original form */ List *indexqualorig;
/* list of index ORDER BY exprs */ List *indexorderby;
/* the same in original form */ List *indexorderbyorig;
/* OIDs of sort ops for ORDER BY exprs */ List *indexorderbyops;
/* forward or backward or don't care */ ScanDirection indexorderdir;
} IndexScan;
In this example, the WHERE clause “id < 240” acts as an access predicate.
Consequently, it is stored in the indexqual field of the IndexScanNode, rather than the general qual field.