9.8. Database Recovery in PostgreSQL
PostgreSQL implements redo log-based recovery. If the database server crashes, PostgreSQL can restore the database cluster by sequentially replaying the XLOG records in the WAL segment files from the REDO point.
We have already discussed database recovery several times. This section will cover two additional aspects of recovery.
The first thing is how PostgreSQL starts the recovery process. When PostgreSQL starts up, it first reads the pg_control file. The following are the details of the recovery process from that point. See Figure 9.20 and the following description.
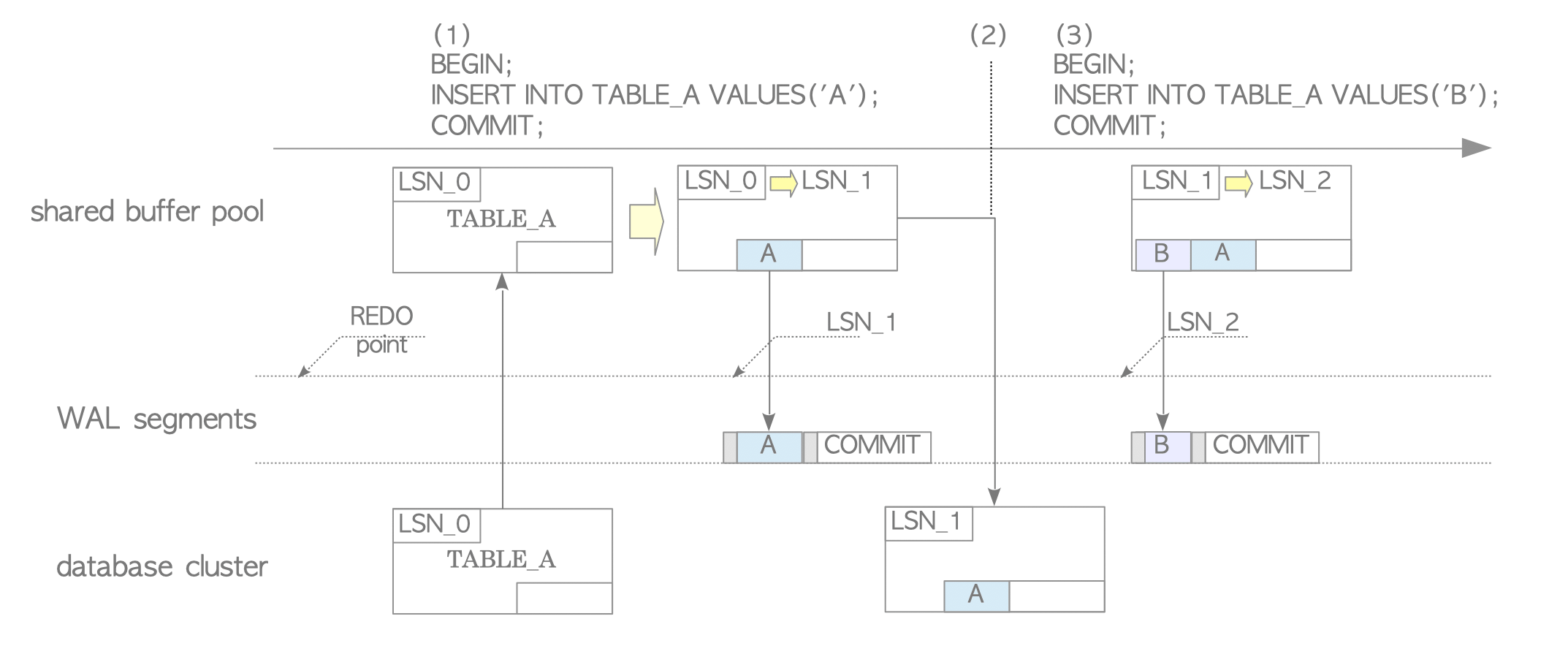
Figure 9.20. Details of the recovery process.
-
PostgreSQL reads all items in the pg_control file when it starts. If the state item is ‘in production’, PostgreSQL enters recovery-mode because this means that the database was not shut down normally. If it is ‘shut down’, PostgreSQL enters normal startup-mode.
-
PostgreSQL reads the latest checkpoint record, the location of which is written in the pg_control file, from the appropriate WAL segment file. It then gets the REDO point from the record. If the latest checkpoint record is invalid, PostgreSQL reads the one prior to it. If both records are unreadable, it gives up recovering by itself. (Note that the prior checkpoint is not stored in PostgreSQL 11 or later.)
-
The appropriate resource managers read and replay XLOG records in sequence from the REDO point until they reach the end of the latest WAL segment. When an XLOG record is replayed and if it is a backup block, it is overwritten on the corresponding table page regardless of its LSN. Otherwise, a (non-backup block) XLOG record is replayed only if the LSN of the record is greater than the ‘pd_lsn’ of the corresponding page.
The second point is about the comparison of LSNs: why the non-backup block’s LSN and the corresponding page’s pd_lsn should be compared. Unlike the previous examples, this will be explained using a specific example that emphasizes the need for this comparison. See Figures 9.21 and 9.22. (Note that the WAL buffer is omitted to simplify the description.)
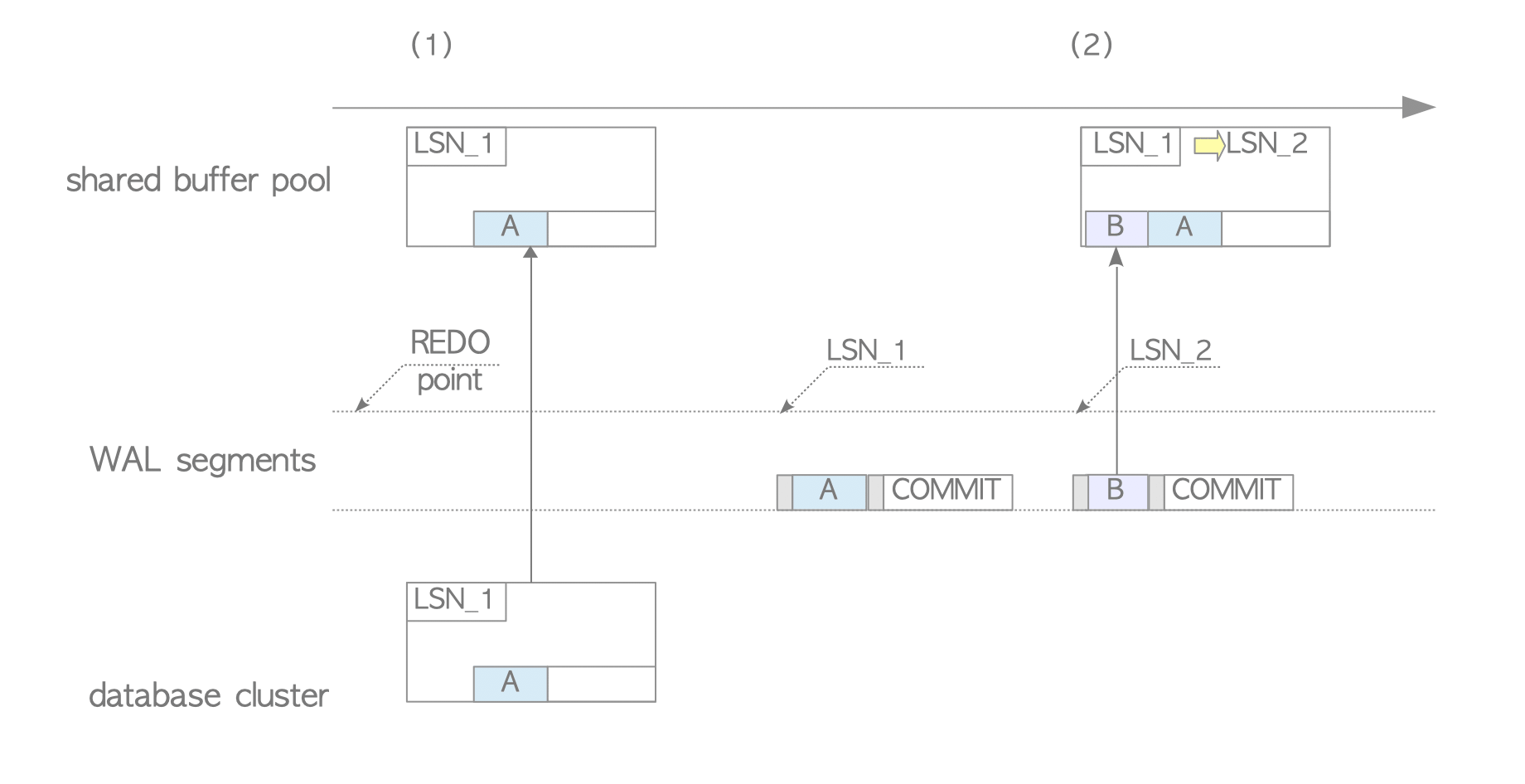
Figure 9.21. Insertion operations during the background writer working.
-
PostgreSQL inserts a tuple into the TABLE_A, and writes an XLOG record at LSN_1.
-
The background-writer process writes the TABLE_A page to storage. At this point, this page’s pd_lsn is LSN_1.
-
PostgreSQL inserts a new tuple into the TABLE_A, and writes a XLOG record at LSN_2. The modified page is not written into the storage yet.
Unlike the examples in overview, the TABLE_A’s page has been once written to the storage in this scenario.
Do shutdown with immediate-mode, and then start the database.
Figure 9.22. Database recovery.
-
PostgreSQL loads the first XLOG record and the TABLE_A page, but does not replay it because the LSN of the record (LSN_1) is not larger than the LSN of the page (also LSN_1). In fact, it is clear that there is no need to replay it.
-
Next, PostgreSQL replays the second XLOG record because the LSN of the record (LSN_2) is greater than the current LSN of the TABLE_A page (LSN_1).
In this example, if the replay order of non-backup blocks is incorrect or non-backup blocks are replayed more than once, the database cluster becomes inconsistent. This highlights that the redo (replay) operation for non-backup blocks is not idempotent. To ensure the correct replay order, non-backup block records should only be replayed when their LSN is greater than the corresponding page’s pd_lsn.
In contrast, the redo operation for backup blocks is idempotent, meaning these blocks can be replayed multiple times regardless of their LSN.