2.1. Process Architecture
PostgreSQL is a client/server relational database management system featuring a multi-process architecture that runs on a single host.
A collection of multiple processes that cooperatively manage a database cluster is referred to as a “PostgreSQL server,” which includes the following types of processes:
- Postgres server process: The parent of all processes related to database cluster management.
- Backend processes: Each backend process handles all queries and statements issued by a connected client.
- Background processes: Various processes that perform tasks for database management, such as VACUUM and CHECKPOINT operations.
- Replication-associated processes: Processes that perform streaming replication. Further details are provided in Chapter 11 and Chapter 12.
- Background worker processes: Supported since version 9.3, these processes can perform any user-implemented logic. For more information, refer to the official documentation.
The following subsections describe the details of the first three process types.
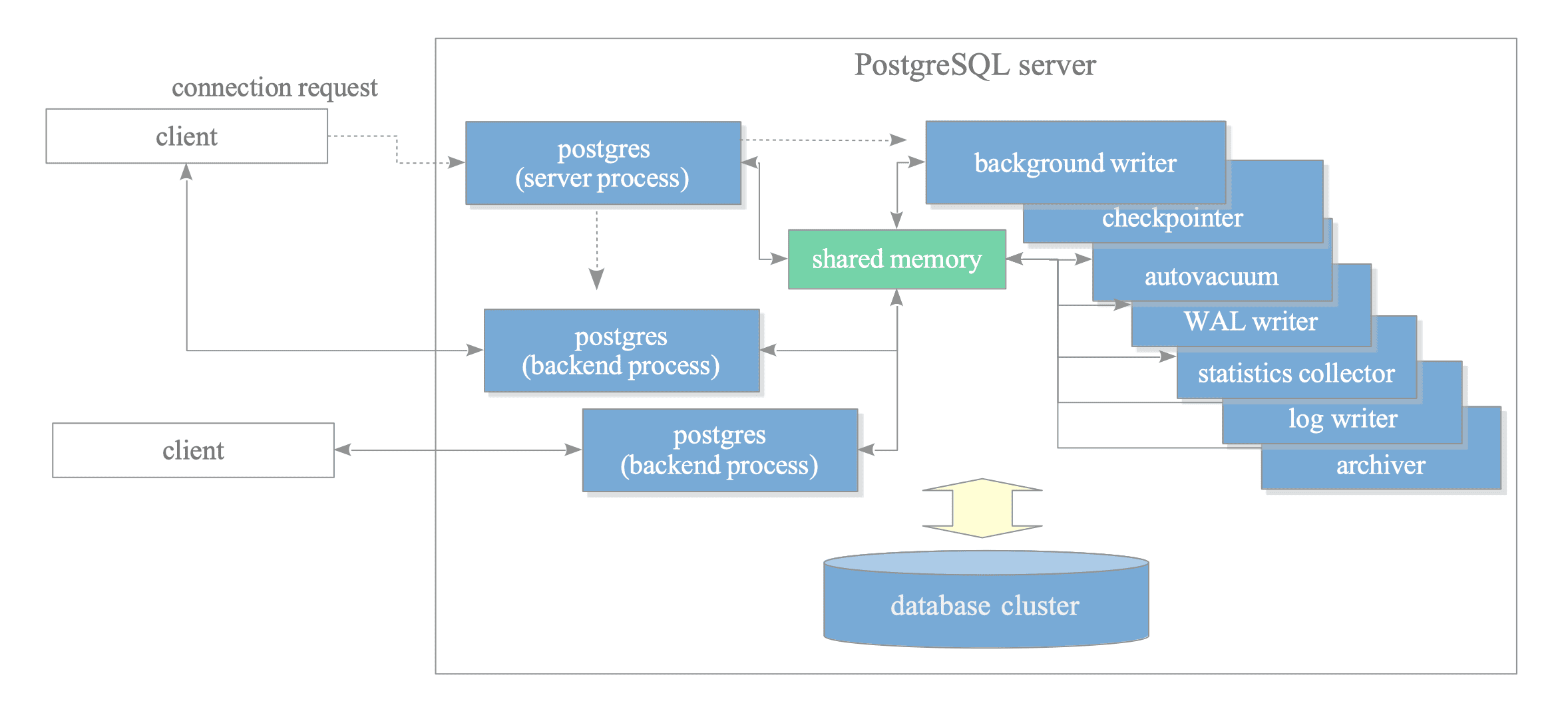
Figure 2.1. An example of the process architecture in PostgreSQL.
This figure illustrates the process architecture of a PostgreSQL server, including a postgres server process, two backend processes, seven background processes, and two client processes. The database cluster and shared memory are also shown.
In the early 1990s, when PostgreSQL development began, using a process-based model was the only practical choice. At that time, POSIX Threads were not yet standardized, and thread implementations were very unstable. By maintaining this architecture to this day, PostgreSQL continues to reap the following benefits:
- Robust Isolation: Since each backend process operates independently, a crash in a specific session is prevented from cascading to the rest of the system.
- OS-Level Memory Management: Memory spaces are strictly partitioned between processes, ensuring data integrity. Furthermore, the operating system reliably handles resource reclamation upon process termination.
In recent years, there have been recurring debates regarding a transition to threads to eliminate the overhead of process creation. However, the cost and risk of refactoring a massive legacy codebase to be thread-safe are immense. Furthermore, advancements in modern operating systems have significantly reduced this overhead. Consequently, PostgreSQL persists with its highly reliable process model.
2.1.1. Postgres Server Process
The postgres server process is the parent of all processes within a PostgreSQL server. In earlier versions, this process was referred to as postmaster.
The postgres server process starts when the pg_ctl utility is executed with the “start” option.
Upon initiation, it allocates a shared memory area, launches various background processes, and starts replication-associated or background worker processes as required. It then waits for connection requests from clients. Whenever a connection request is received, the postgres server process spawns a dedicated backend process to handle the client session.
A postgres server process listens on a specific network port, with the default being 5432. While multiple PostgreSQL servers can run on the same host, each instance must be configured to listen on a unique port number (e.g., 5432, 5433, etc.).
2.1.2. Backend Processes
A backend process, also referred to as a postgres process, is started by the postgres server process and handles all queries issued by a single connected client. It communicates with the client via a single TCP connection and terminates upon the client’s disconnection.
Each backend process can operate on only one database at a time; therefore, a specific database must be selected during the connection process.
PostgreSQL supports concurrent connections from multiple clients, with the maximum number governed by the max_connections configuration parameter (default: 100).
Because PostgreSQL does not have a native connection pooling feature, frequent connection and disconnection cycles — common in applications like web services — can increase the overhead of establishing connections and spawning backend processes.
This overhead can negatively impact the overall performance of the database server. To mitigate this, connection pooling middleware such as pgbouncer or pgpool-II is typically employed.
2.1.3. Background Processes
Table 2.1 lists the primary background processes.
Unlike the postgres server and backend processes, the functions of background processes cannot be easily summarized because they depend on specific features and deep PostgreSQL internals.
Therefore, this section provides only a brief introduction to each process. Detailed explanations are provided in the subsequent chapters.
| process | description | reference |
|---|---|---|
| background writer | Periodically and gradually writes dirty pages from the shared buffer pool to persistent storage (e.g., HDD, SSD). (In versions 9.1 and earlier, it was also responsible for performing checkpoints.) | Section 8.6 |
| checkpointer | Performs checkpoint operations in versions 9.2 or later. | Section 8.6, Section 9.7 |
| autovacuum launcher | Periodically invokes autovacuum-worker processes for VACUUM and ANALYZE operations. (Technically, it requests the postgres server process to spawn the autovacuum workers.) | Section 6.5 |
| WAL writer | Periodically writes and flushes WAL data from the WAL buffer to persistent storage. | Section 9.6.1 |
| WAL Summarizer | Tracks changes to all database blocks and writes these modifications to WAL summary files. This process was introduced in version 17 (2024). | Section 9.6.2 |
| statistics collector | Collects statistics for system views such as pg_stat_activity and pg_stat_database. | |
| logging collector (logger) | Captures error messages and writes them into log files. | |
| io worker | Handles read operations asynchronously to offload I/O tasks from backend processes. (Asynchronous I/O was introduced in version 18 (2025) to improve I/O performance.) | Section 8.5.2.2 |
| archiver | Executes the log archiving process. | Section 9.10 |
The actual processes of a PostgreSQL server are shown below.
In this example, there is one postgres server process (PID 6541), two backend processes (PIDs 8412 and 8482), and several background processes as listed in Table 2.1. See also Figure 2.1.
$ pstree -p 6541
-+= 00001 root /sbin/launchd
\-+= 06541 postgres /usr/local/pgsql/bin/postgres -D data
|--= 06542 postgres postgres: io worker 0
|--= 06543 postgres postgres: io worker 1
|--= 06544 postgres postgres: io worker 2
|--= 06545 postgres postgres: checkpointer
|--= 06546 postgres postgres: background writer
|--= 06548 postgres postgres: walwriter
|--= 06549 postgres postgres: autovacuum launcher
|--= 06550 postgres postgres: walsummarizer
|--= 06551 postgres postgres: logical replication launcher
|--= 08412 postgres postgres: postgres testdb [local] idle
\--= 08482 postgres postgres: postgres testdb [local] idle in transaction