8.4. Buffer management mechanisms
The buffer manager abstracts the mechanism of reading and writing block data from or to storage, allowing the executor to access data seamlessly.
This section explains the internal mechanism, focusing specifically on how PostgreSQL reads a target page of a relation table.
Section 8.4.1 describes the basic operation of the buffer manager using an example of reading a single page, and Section 8.4.2 explains the page replacement algorithm (clock sweep). Sections 8.4.3 and 8.4.5 provide details on the ring buffer — used for reading or writing a large table — and the local buffer.
Because the sequential scan mechanism has changed significantly with the introduction of Asynchronous I/O (AIO), Section 8.5 explains its details.
8.4.1. Reading A Single Page
This section considers the process of reading a single page.
In this case, when a backend process requires access to a specific page, it calls the ReadBuffer() function.
The behavior of ReadBuffer() depends on three logical cases. The following subsections describe each case.
8.4.1.1. Accessing a Page Stored in the Buffer Pool
This subsection describes the simplest case: the desired page is already stored in the buffer pool. In this case, the buffer manager performs the following steps (refer to Figure 8.9):
-
(1) Create the buffer_tag of the desired page (e.g., Tag_C) and compute the hash bucket slot.
-
(2) Acquire the BufMappingLock partition that covers the hash bucket slot in shared mode. This lock is released in step (5).
-
(3) Look up the entry with Tag_C and obtain the buffer_id (e.g., buffer_id 2) from that entry.
-
(4) Pin the buffer descriptor for buffer_id 2 by increasing its refcount and usage_count by 1.
-
(5) Release the BufMappingLock.
-
(6) Access the buffer pool slot with buffer_id 2.
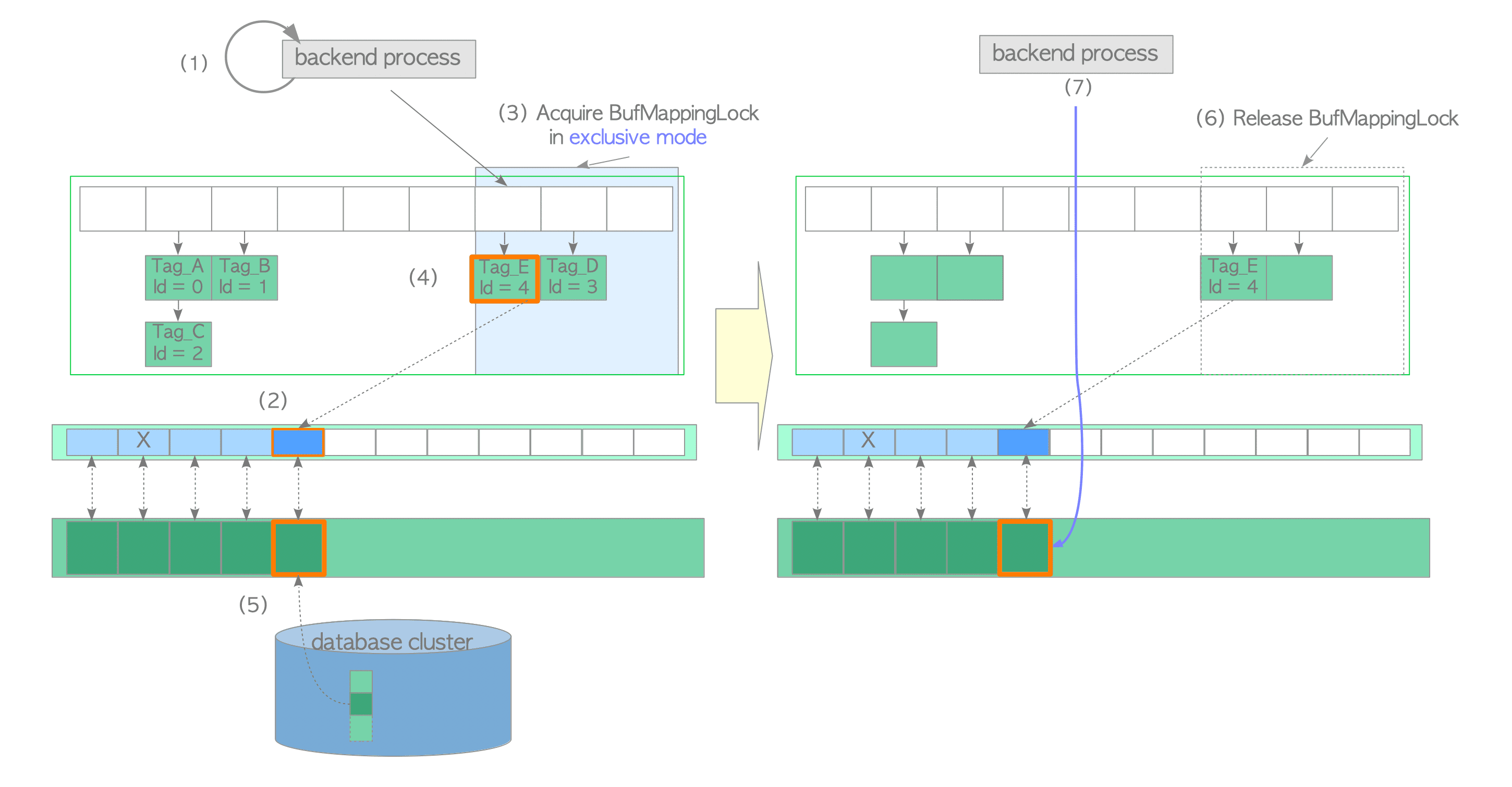
Figure 8.9. Accessing a page stored in the buffer pool.
When reading rows from the page, the PostgreSQL process acquires the shared content_lock of the corresponding buffer descriptor. This lock allows multiple processes to read the buffer pool slot simultaneously.
When inserting, updating, or deleting rows, a Postgres process acquires the exclusive content_lock of the corresponding buffer descriptor. The process must also set the BM_DIRTY bit of the page to 1.
After accessing the page, the PostgreSQL process decreases the refcount of the corresponding buffer descriptor by 1.
(Note that the usage_count remains unchanged once it reaches 15, as it is capped by its 4-bit width.)
Pseudocode
The following pseudocode illustrates this process:
ReadBuffer()
StartReadBuffer()
PinBufferForBlock()
BufferAlloc(blockNum)
/* (1) */
buffer_tag = InitBufferTag(specOid, dbOid, relNumber, blockNum, forkNum);
/* (2) */
LWLockAcquire(partitionLock, LW_SHARED);
/* (3) */
buf_id = BufTableLookup(buffer_tag);
bufDesc = GetBufferDescriptor(buf_id);
/* (4) */
PinBuffer(bufDesc);
/* (5) */
LWLockRelease(partitionLock);
return bufDesc;
return BufferDescriptorGetBuffer(bufDesc);
return buf_id;When reading a single page, PostgreSQL invokes the ReadBuffer() function, which sequentially calls StartReadBuffer(), PinBufferForBlock() and BufferAlloc().
The BufferAlloc() function internally executes the operations on the buffer descriptor (steps (1) to (5)).
Before introducing AIO, the ReadBuffer() function was simpler, as shown below:
ReadBuffer()
BufferAlloc(blockNum)
/* (1) */
buffer_tag = InitBufferTag(specOid, dbOid, relNumber, blockNum, forkNum);
/* (2) */
LWLockAcquire(partitionLock, LW_SHARED);
/* (3) */
buf_id = BufTableLookup(buffer_tag);
bufDesc = GetBufferDescriptor(buf_id);
/* (4) */
PinBuffer(bufDesc);
/* (5) */
LWLockRelease(partitionLock);
return bufDesc;
return buf_id;The same applies to the pseudocode within this section from here on; that is, ReadBuffer() directly calls BufferAlloc() without going through StartReadBuffer(), or PinBufferForBlock().
8.4.1.2. Loading a Page from Storage to Empty Slot
In this second case, assume that the buffer pool does not contain the desired page and the freelist has free elements (empty descriptors).
The buffer manager performs the following steps (refer to Figure 8.10):
-
(1) Look up the buffer table (assume the entry is not found).
- Create the buffer_tag of the desired page (in this example, the buffer_tag is Tag_E) and compute the hash bucket slot.
- Acquire the BufMappingLock partition in shared mode.
- Look up the buffer table. (Not found according to the assumption.)
- Release the BufMappingLock.
-
(2) Obtain an empty buffer descriptor from the freelist. In this example, the buffer_id of the obtained descriptor is 4.
-
(3) Acquire the BufMappingLock partition in exclusive mode. (This lock is released in step (5).)
-
(4) Create a new data entry that comprises the buffer_tag Tag_E and buffer_id 4. Insert the created entry into the buffer table, and pin the buffer descriptor.
-
(5) Release the BufMappingLock.
-
(6) Load the desired page data from storage to the buffer pool slot with buffer_id 4 as follows:
- Set the BM_IO_IN_PROGRESS bit of the corresponding descriptor to 1 to prevent access by other processes.
- Load the desired page data from storage to the buffer pool slot.
- Update the state of the corresponding descriptor: set the BM_IO_IN_PROGRESS bit to 0 and the BM_VALID bit to 1.
-
(7) Access the buffer pool slot with buffer_id 4.
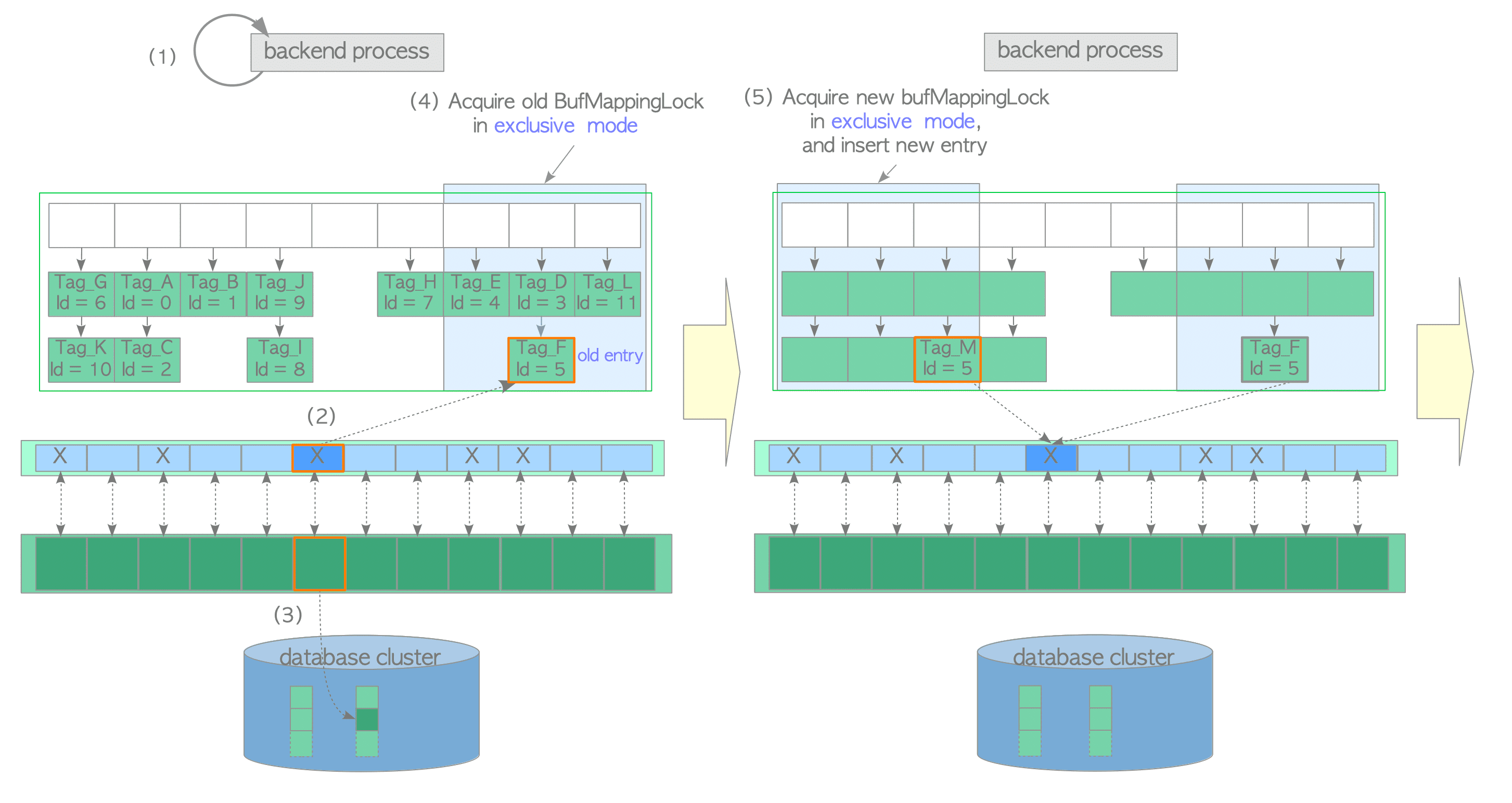
Figure 8.10. Loading a page from storage to an empty slot.
When loading a single page from storage, PostgreSQL synchronously reads it regardless of the io_method configuration parameter.
Pseudocode
The following pseudocode illustrates this process.
ReadBuffer()
StartReadBuffer()
PinBufferForBlock()
BufferAlloc(blockNum)
/* (1) Lookup but not found */
buffer_tag = InitBufferTag(specOid, dbOid, relNumber, blockNum, forkNum);
LWLockAcquire(partitionLock, LW_SHARED);
BufTableLookup(buffer_tag);
LWLockRelease(partitionLock);
/* (2) Get empty buffer */
buf_id = GetVictimBuffer();
bufDesc = GetBufferDescriptor(buf_id);
/* (3) */
LWLockAcquire(partitionLock, LW_EXCLUSIVE);
/* (4) */
BufTableInsert(buffer_tag, bufDesc->buf_id);
PinBuffer(bufDesc);
/* (5) */
LWLockRelease(partitionLock);
return bufDesc;
/* (6) load page */
AsyncReadBuffers()
StartBufferIO() /* BM_IO_IN_PROGRESS = 1 */
pgaio_io_perform_synchronously()
read()
TerminateBufferIO(bufDesc); /* BM_IO_IN_PROGRESS = 0; BM_VALID = 1 */
return bufDesc;ReadBuffer()
BufferAlloc()
/* (1) Lookup but not found */
buffer_tag = InitBufferTag(specOid, dbOid, relNumber, blockNum, forkNum);
LWLockAcquire(partitionLock, LW_SHARED);
BufTableLookup(buffer_tag);
LWLockRelease(partitionLock);
/* (2) Get empty buffer */
buf_id = GetVictimBuffer();
bufDesc = GetBufferDescriptor(buf_id);
/* (3) */
LWLockAcquire(partitionLock, LW_EXCLUSIVE);
/* (4) */
BufTableInsert(buffer_tag, bufDesc->buf_id);
PinBuffer(bufDesc);
/* (5) */
LWLockRelease(partitionLock);
StartBufferIO(bufDesc); /* BM_IO_IN_PROGRESS = 1 */
return bufDesc;
/* (6) */
read(); /* e.g., preadv() on Linux */
TerminateBufferIO(bufDesc); /* BM_IO_IN_PROGRESS = 0; BM_VALID = 1 */
return bufDesc;8.4.1.3. Loading a Page from Storage to a Victim Buffer Pool Slot
Assume that all buffer pool slots are occupied, but the buffer pool does not store the desired page. The buffer manager performs the following steps (refer to Figures 8.11 and 8.12):
-
(1) Create the buffer_tag of the desired page and look up the buffer table. In this example, the buffer_tag is Tag_M and is not found in the table.
-
(2) Select a victim buffer pool slot using the clock-sweep algorithm. Obtain the old entry, which contains the buffer_id of the victim pool slot, from the buffer table. Pin the victim pool slot in the buffer descriptors layer.
In this example, the buffer_id of the victim slot is 5 and the old entry is ‘Tag_F, id=5’.
-
(3) Flush (write and fsync) the victim page data if it is dirty; otherwise proceed to step (4).
The dirty page must be written to storage before overwriting with new data. Flushing a dirty page is performed by FlushBuffer() function as follows:- Acquire the shared content_lock of the descriptor with buffer_id 5 (released in step 6).
- Change the states of the corresponding descriptor; the BM_IO_IN_PROGRESS bit is set to 1 and the BM_JUST_DIRTIED bit is set to 0.
- Invoke the XLogFlush() function to write WAL data on the WAL buffer to the current WAL segment file (details are omitted; WAL and the XLogFlush() function are described in Chapter 9.
- Flush the victim page data to storage.
- Change the states of the corresponding descriptor; the BM_IO_IN_PROGRESS bit is set to 0 and the BM_VALID bit is set to 1.
- Release the content_lock.
-
(4) Acquire the old BufMappingLock partition that covers the slot that contains the old entry, in exclusive mode.
-
(5) Acquire the new BufMappingLock partition and insert the new entry to the buffer table:
- Create the new entry comprised of the new buffer_tag Tag_M and the victim’s buffer_id.
- Acquire the new BufMappingLock partition that covers the slot containing the new entry in exclusive mode.
- Insert the new entry to the buffer table.
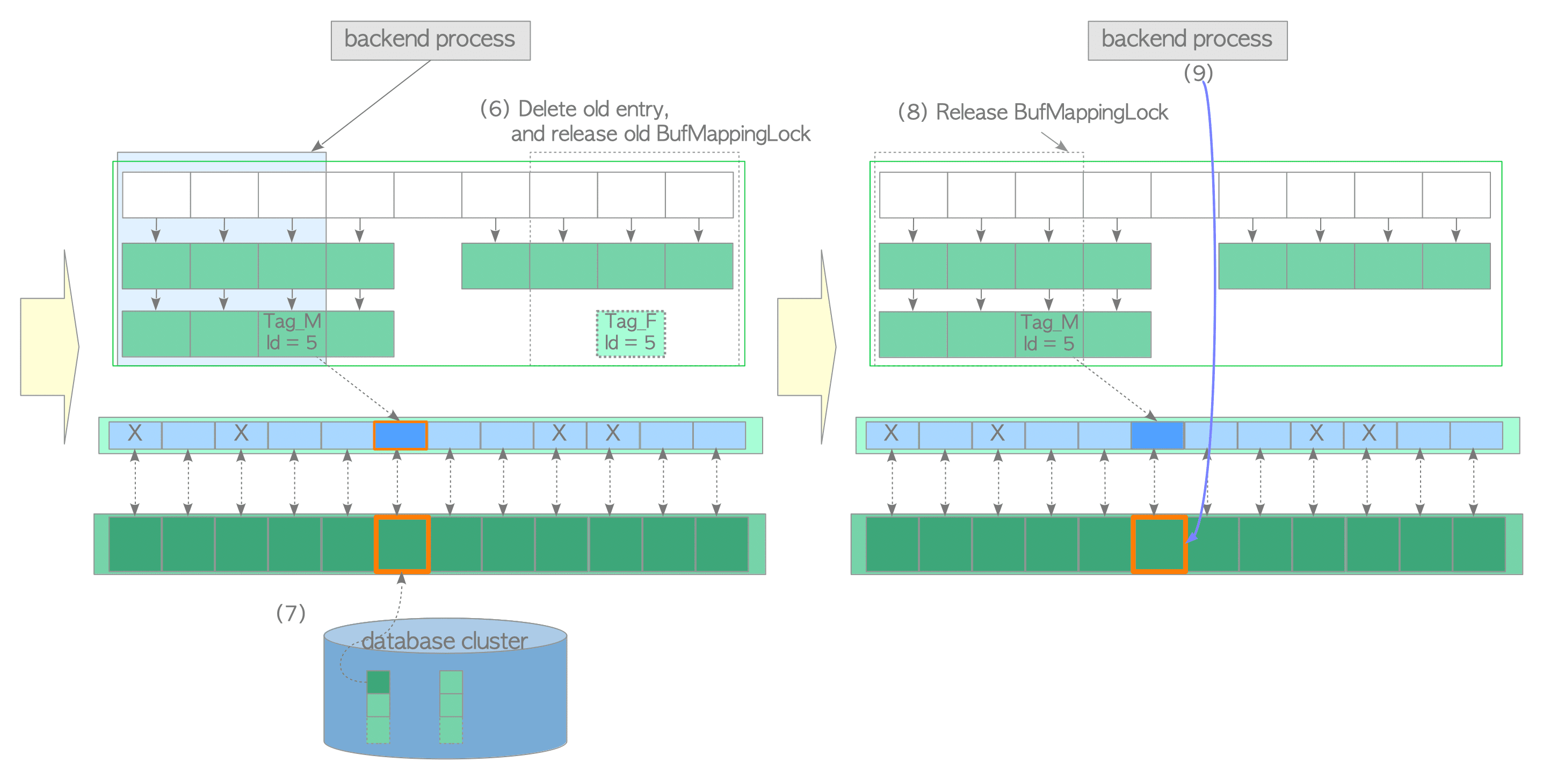
Figure 8.11. Loading a page from storage to a victim buffer pool slot.
-
(6) Delete the old entry from the buffer table, and release the old BufMappingLock partition.
-
(7) Load the desired page data from the storage to the victim buffer slot. Then, update the flags of the descriptor with buffer_id 5; the BM_DIRTY bit is set to 0 and other bits are initialized.
-
(8) Release the new BufMappingLock partition.
-
(9) Access the buffer pool slot with buffer_id 5.
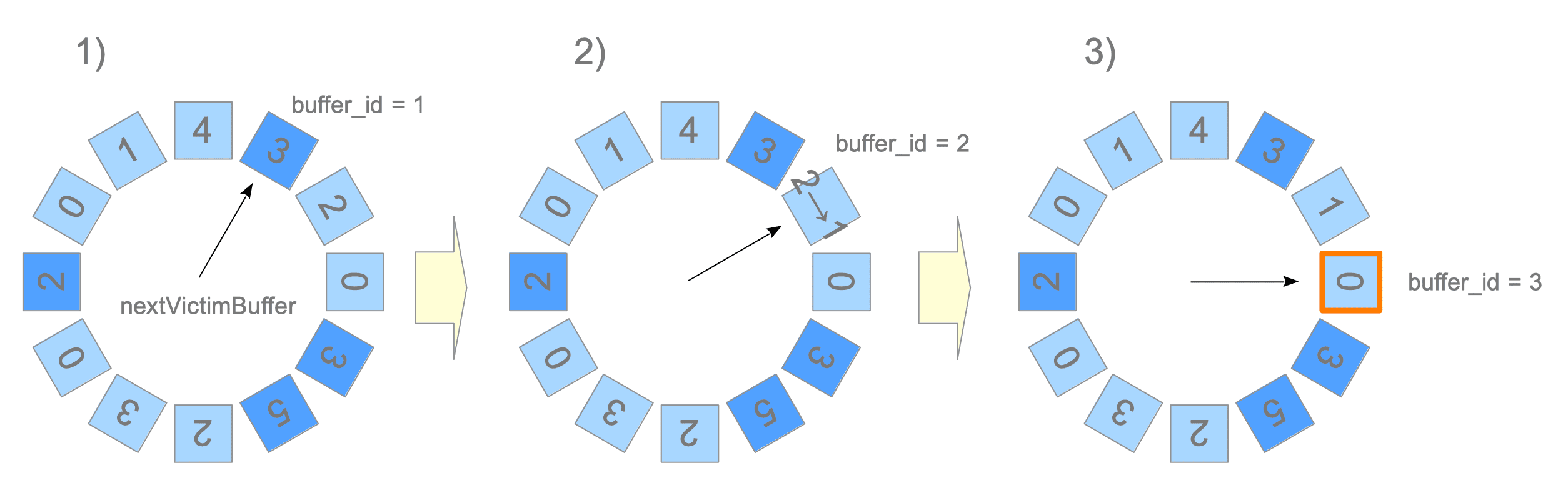
Figure 8.12. Loading a page from storage to a victim buffer pool slot (continued from Figure 8.11).
8.4.2. Page Replacement Algorithm: Clock Sweep
This section describes the clock-sweep algorithm. This algorithm is a variant of NFU (Not Frequently Used) with low overhead; it selects less frequently used pages efficiently.
Imagine buffer descriptors form a circular list (Figure 8.13). The nextVictimBuffer, an unsigned 32-bit integer, always points to one of the buffer descriptors and rotates clockwise. The pseudocode and description of the algorithm follow:
WHILE true
(1) Obtain the candidate buffer descriptor pointed by the nextVictimBuffer
(2) IF the candidate descriptor is 'unpinned' THEN
(3) IF the candidate descriptor's usage_count == 0 THEN
BREAK WHILE LOOP /* the corresponding slot of this descriptor */
/* is victim slot. */
ELSE
Decrease the candidate descriptpor's usage_count by 1
END IF
END IF
(4) Advance nextVictimBuffer to the next one
END WHILE
(5) RETURN buffer_id of the victim- (1) Obtain the candidate buffer descriptor pointed by nextVictimBuffer.
- (2) If the candidate buffer descriptor is unpinned, proceed to step (3). Otherwise, proceed to step (4).
- (3) If the usage_count of the candidate descriptor is 0, select the corresponding slot of this descriptor as a victim and proceed to step (5). Otherwise, decrease this descriptor’s usage_count by 1 and proceed to step (4).
- (4) Advance the nextVictimBuffer to the next descriptor (wrap around if at the end) and return to step (1). Repeat until a victim is found.
- (5) Return the buffer_id of the victim.
Figure 8.13 shows a specific example. The buffer descriptors are blue or cyan boxes, and the numbers in the boxes indicate the usage_count of each descriptor.
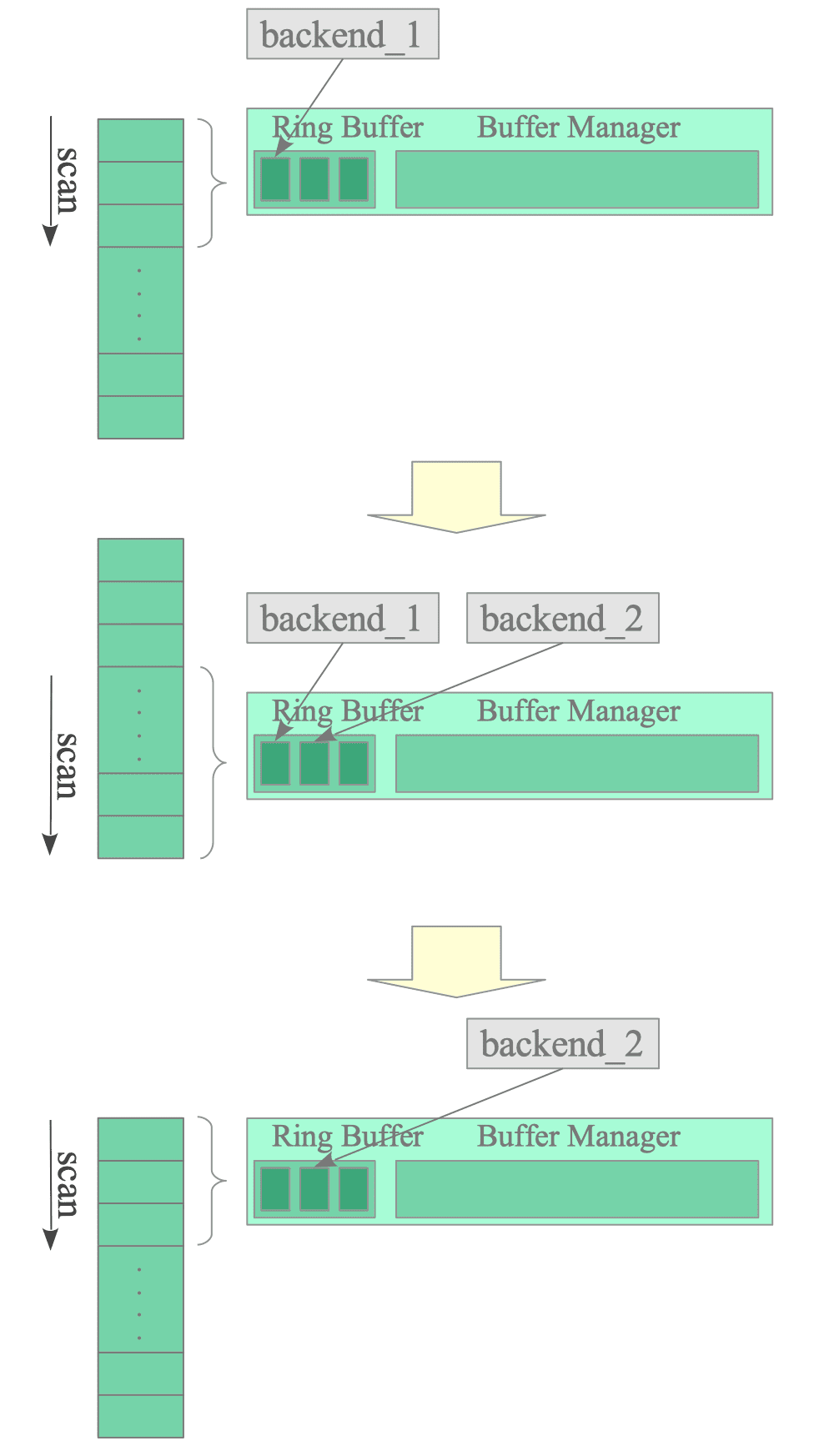
Figure 8.13. Clock Sweep.
-
1) The nextVictimBuffer points to the first descriptor (buffer_id 1). This descriptor is skipped because it is pinned.
-
2) The nextVictimBuffer points to the second descriptor (buffer_id 2). This descriptor is unpinned, but its usage_count is 2. Thus, the usage_count decreases by 1, and the nextVictimBuffer advances to the third candidate.
-
3) The nextVictimBuffer points to the third descriptor (buffer_id 3). This descriptor is unpinned and its usage_count is 0. Thus, this descriptor becomes the victim in this round.
Whenever the nextVictimBuffer sweeps an unpinned descriptor, the usage_count decreases by 1. Therefore, if unpinned descriptors exist in the buffer pool, this algorithm always finds a victim with a usage_count of 0 by rotating the nextVictimBuffer.
8.4.3. Ring Buffer
PostgreSQL uses a ring buffer instead of the buffer pool when reading or writing a large table. The ring buffer is a small, temporary buffer area.
It is allocated in shared memory when any of the following conditions is met:
-
Bulk-reading:
The relation size exceeds one-quarter of the buffer pool size (shared_buffers/4). In this case, the ring buffer size is 256 KB. -
Bulk-writing:
The following SQL commands are executed. In these cases, the ring buffer size is 16 MB:- COPY FROM command.
- CREATE TABLE AS command.
- CREATE MATERIALIZED VIEW or REFRESH MATERIALIZED VIEW command.
- ALTER TABLE command.
-
Vacuum-processing:
An autovacuum process performs vacuuming. In this case, the ring buffer size is 256 KB.
PostgreSQL releases the ring buffer immediately after use.
The benefit of the ring buffer is clear. If a backend process reads a large table without a ring buffer, the operation may evict all pages in the buffer pool, reducing the cache hit ratio. The ring buffer prevents this by providing a dedicated temporary area for large tables.
The README in the buffer manager’s source directory explains the reason:
For sequential scans, a 256 KB ring is used. That’s small enough to fit in L2 cache, which makes transferring pages from OS cache to shared buffer cache efficient. Even less would often be enough, but the ring must be big enough to accommodate all pages in the scan that are pinned concurrently. (snip)
When multiple backends access the same relation concurrently, they share the ring buffer.
Figure 8.14 illustrates how two backends access a ring buffer during a sequential scan:
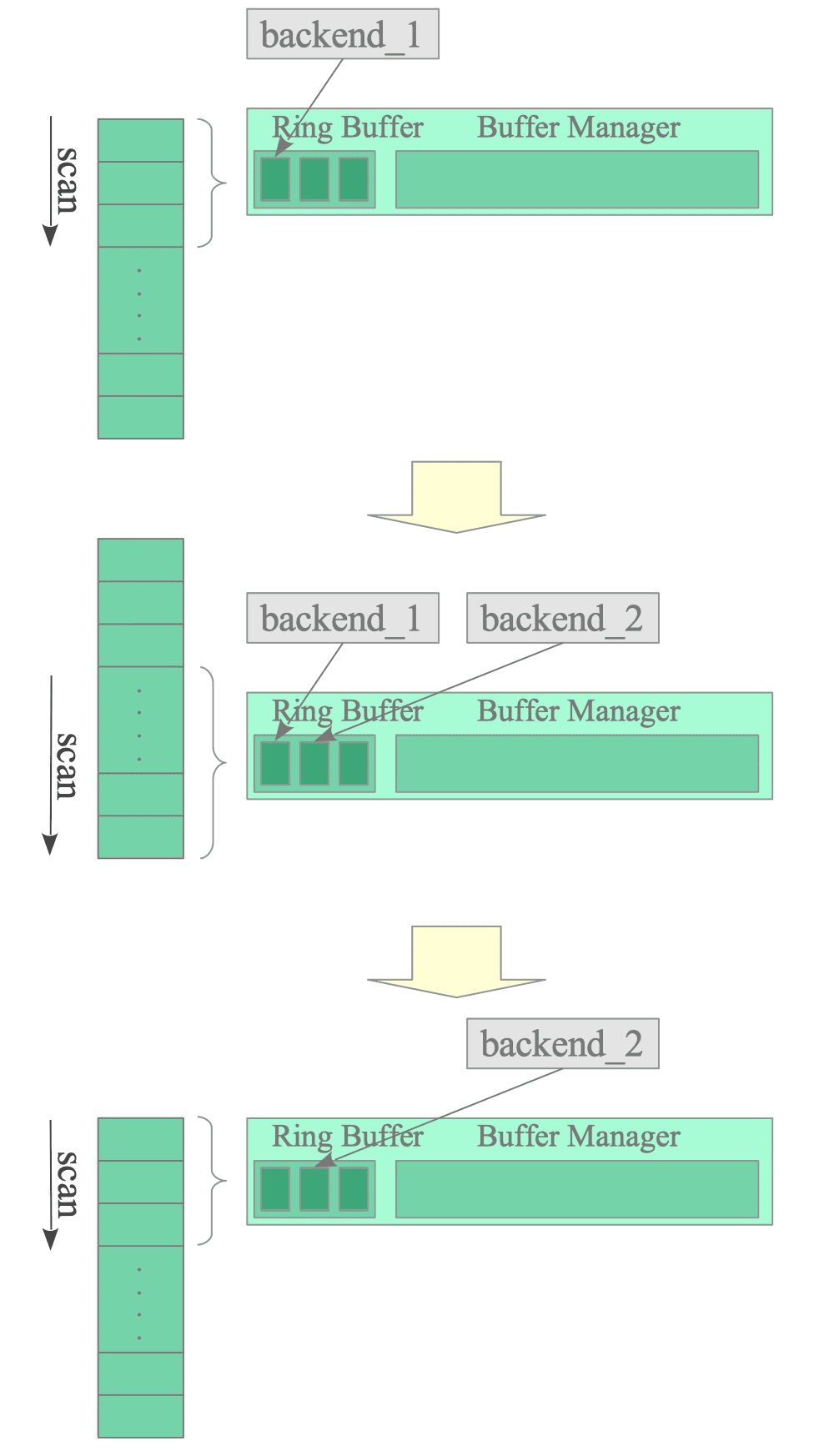
Figure 8.14. Sharing the Ring Buffer with Two Backends.
- Backend_1 creates and accesses a ring buffer to read a table.
- Backend_1 and Backend_2 access the table pages loaded into the shared ring buffer. Backend_2 starts its sequential scan from the middle of the table.
- After Backend_1 completes its scan, Backend_2 continues scanning the rest of the table, starting from the beginning and proceeding to the middle.
8.4.4. Temporary Tables and Local Buffer Management
When a backend creates a temporary table, the buffer manager allocates a private memory area and creates a local buffer.
Shared buffer bucket slots use positive numbers. In contrast, local buffer bucket slots use negative numbers (e.g., -1, -2). This distinction allows the backend to access both regular and temporary tables seamlessly.
Managing local buffers does not require locks because only the owner backend accesses them. Additionally, local buffers do not require WAL logging or checkpointing.