7.1. Heap Only Tuple (HOT)
The HOT was implemented in version 8.3 to effectively use the pages of both index and table when the updated row is stored in the same table page that stores the old row. HOT also reduces the need for VACUUM processing.
Since the details of HOT are described in the README.HOT file in the source code directory, this chapter only provides a brief introduction to HOT.
Section 7.1.1 first describes how to update a row without HOT to clarify the issues that HOT resolves. Section 7.1.2 then describes how HOT works.
7.1.1. Update a Row Without HOT
Assume that the table ’tbl’ has two columns: ‘id’ and ‘data’; ‘id’ is the primary key of ’tbl’.
testdb=# \d tbl
Table "public.tbl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | not null |
data | text | | |
Indexes:
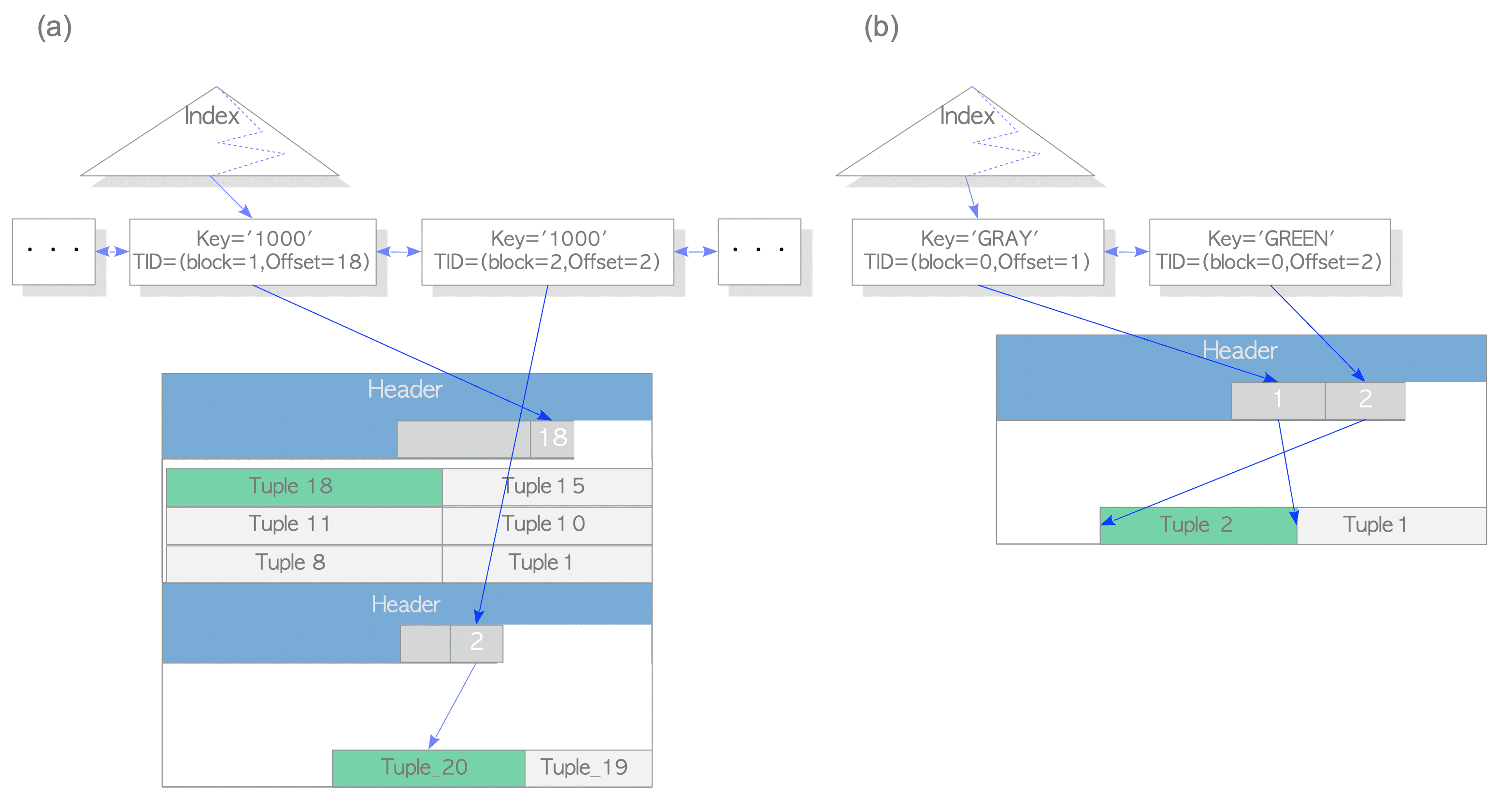
"tbl_pkey" PRIMARY KEY, btree (id)The table ’tbl’ has 1000 tuples; the last tuple, whose id is 1000, is stored in the 5th page of the table. The last tuple is pointed by the corresponding index tuple, whose key is 1000 and whose tid is ‘(5, 1)’. See Figure 7.1(a).
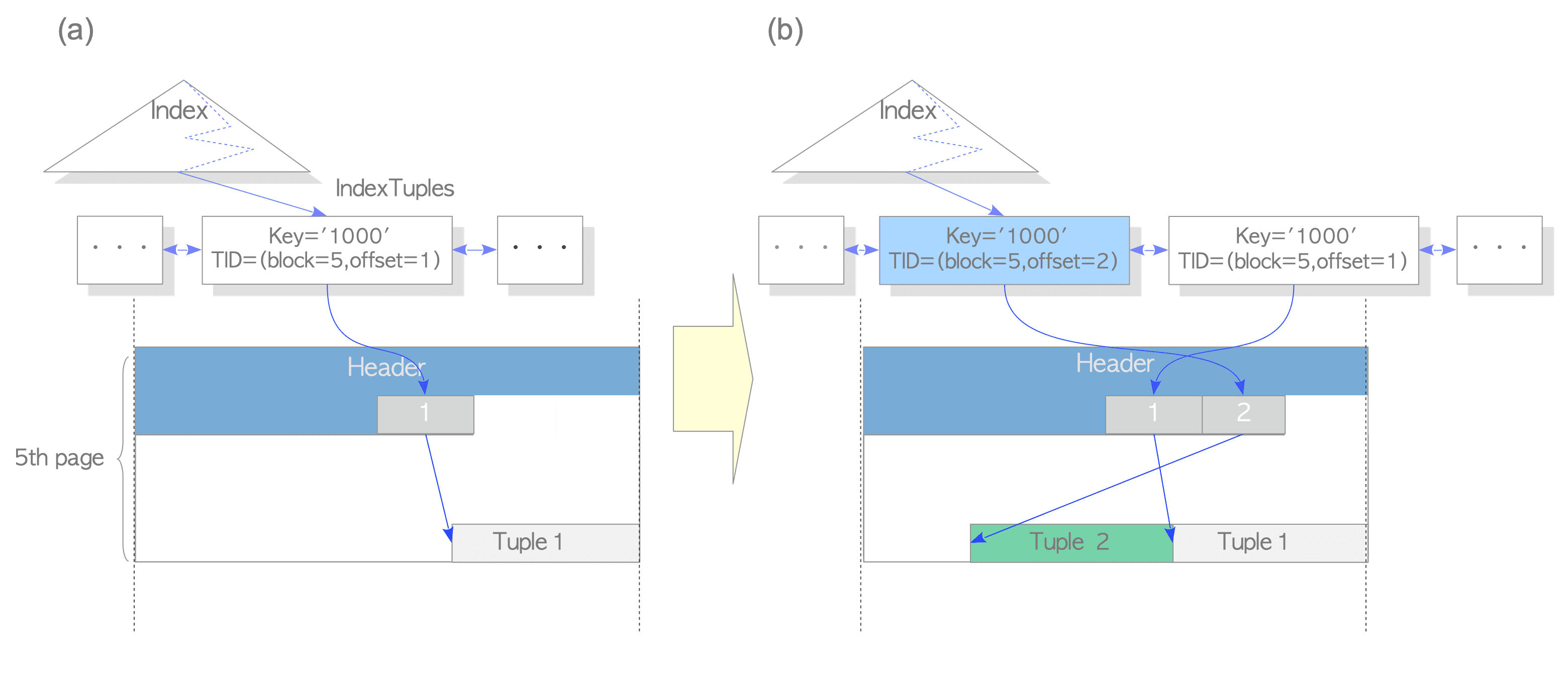
Figure 7.1. Update a row without HOT
We consider how the last tuple is updated without HOT.
testdb=# UPDATE tbl SET data = 'B' WHERE id = 1000;In this case, PostgreSQL inserts not only the new table tuple but also the new index tuple into the index page. See Figure 7.1(b).
The inserting of the index tuples consumes the index page space, and both the inserting and vacuuming costs of the index tuples are high. HOT reduces the impact of these issues.
7.1.2. How HOT Performs
When a row is updated with HOT, if the updated row will be stored in the same table page that stores the old row, PostgreSQL does not insert the corresponding index tuple and sets the HEAP_HOT_UPDATED bit and the HEAP_ONLY_TUPLE bit to the t_informask2 fields of the old tuple and the new tuple, respectively. See Figures. 7.2 and 7.3.
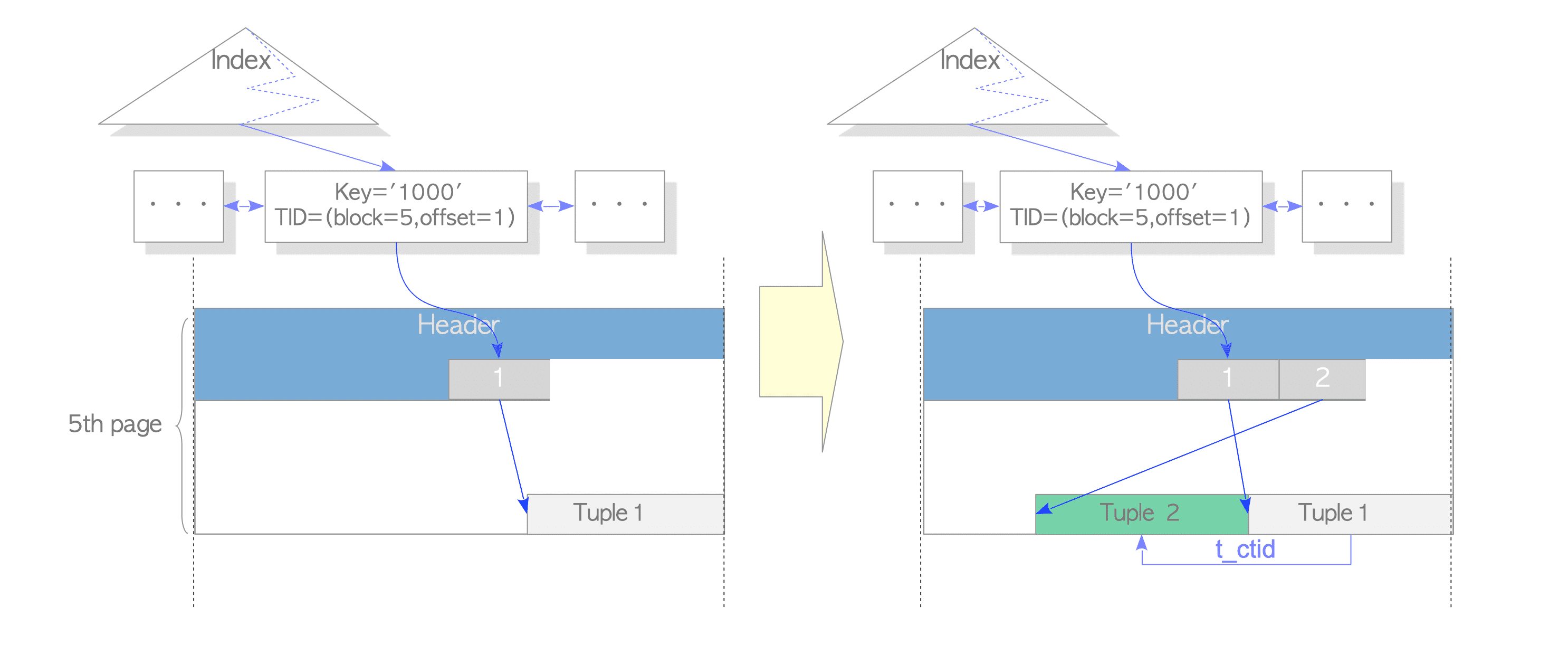
Figure 7.2. Update a row with HOT
For example, in this case, Tuple_1 and Tuple_2 are set to the HEAP_HOT_UPDATED bit and the HEAP_ONLY_TUPLE bit, respectively.
In addition, the HEAP_HOT_UPDATED and the HEAP_ONLY_TUPLE bits are used regardless of the pruning and the defragmentation processes, which are described in the following, are executed.

Figure 7.3. HEAP_HOT_UPDATED and HEAP_ONLY_TUPLE bits
In the following, a description of how PostgreSQL accesses the updated tuples using the index scan immediately after updating the tuples with HOT is given. See Figure 7.4(a).
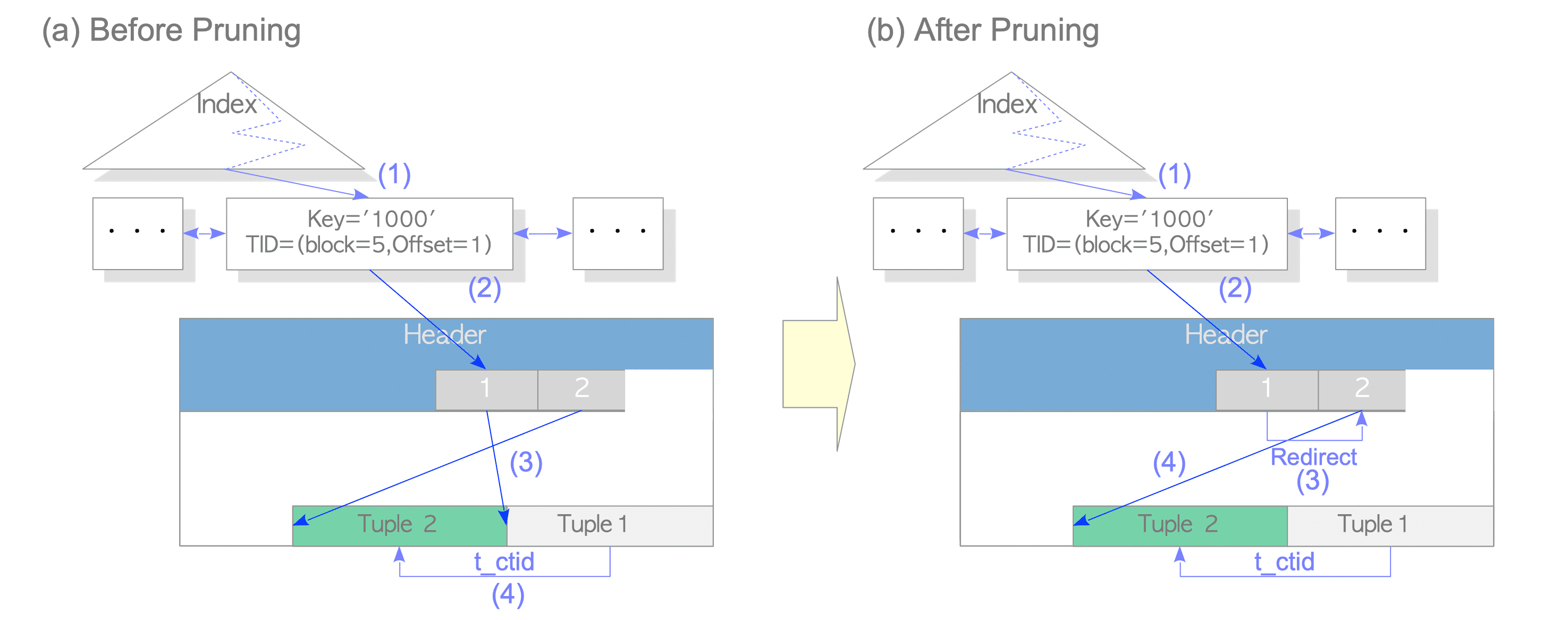
Figure 7.4. Pruning of the line pointers
- Find the index tuple that points to the target tuple.
- Access the line pointer [1] that is pointed by the index tuple.
- Read Tuple_1.
- Read Tuple_2 via the t_ctid of Tuple_1.
In this case, PostgreSQL reads two tuples, Tuple_1 and Tuple_2, and decides which is visible using the concurrency control mechanism described in Chapter 5.
However, a problem arises if the dead tuples in the table pages are removed. For example, in Figure 7.4(a), if Tuple_1 is removed since it is a dead tuple, Tuple_2 cannot be accessed from the index.
To resolve this problem, at an appropriate time, PostgreSQL redirects the line pointer that points to the old tuple to the line pointer that points to the new tuple. In PostgreSQL, this processing is called pruning. Figure 7.4(b) depicts how PostgreSQL accesses the updated tuples after pruning.
- Find the index tuple.
- Access the line pointer [1] that is pointed by the index tuple.
- Access the line pointer [2] that points to Tuple_2 via the redirected line pointer.
- Read Tuple_2 that is pointed by the line pointer [2].
The pruning processing will be executed, if possible, when a SQL command is executed such as SELECT, UPDATE, INSERT and DELETE. The exact execution timing is not described in this chapter because it is very complicated. The details are described in the README.HOT file.
PostgreSQL removes dead tuples if possible, as in the pruning process, at an appropriate time. In the document of PostgreSQL, this processing is called defragmentation. Figure 7.5 depicts the defragmentation by HOT.
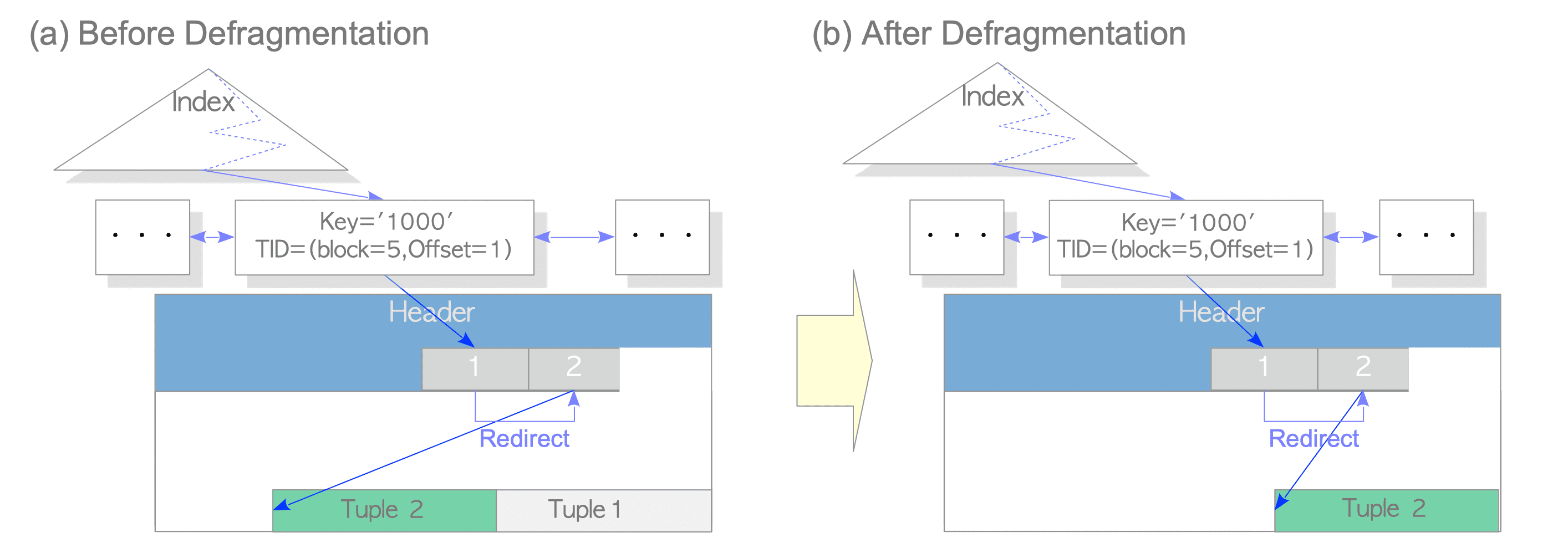
Figure 7.5. Defragmentation of the dead tuples
Note that the cost of defragmentation is less than the cost of normal VACUUM processing because defragmentation does not involve removing the index tuples.
Thus, using HOT reduces the consumption of both indexes and tables of pages; this also reduces the number of tuples that the VACUUM processing has to process. Therefore, HOT has a positive influence on performance because it eventually reduces the number of insertions of the index tuples by updating and the necessity of VACUUM processing.
To better understand HOT performance, we will describe cases where HOT is not available.
When the updated tuple is stored in a different page from the page that stores the old tuple, the index tuple that points to the tuple must also be inserted in the index page. See Figure 7.6(a).
When the key value of the index tuple is updated, a new index tuple must be inserted in the index page. See Figure 7.6(b).