3.5.2. Merge Join
Unlike the nested loop join, the merge join can only be used in natural joins and equi-joins.
The cost of the merge join is estimated by the initial_cost_mergejoin() and final_cost_mergejoin() functions.
The exact cost estimation is complicated, so it is omitted here. Instead, we will only the runtime order of the merge join algorithm. The start-up cost of the merge join is the sum of sorting costs of both inner and outer tables. This means that the start-up cost is $ O(N_{outer} \log_2(N_{outer}) + N_{inner} \log_2(N_{inner})) $, where $ N_{outer} $ and $ N_{inner} $ are the number of tuples of the outer and inner tables, respectively. The run cost is $ O(N_{outer} + N_{inner}) $.
Similar to the nested loop join, the merge join in PostgreSQL has four variations.
3.5.2.1. Merge Join
Figure 3.23 shows a conceptual illustration of a merge join.
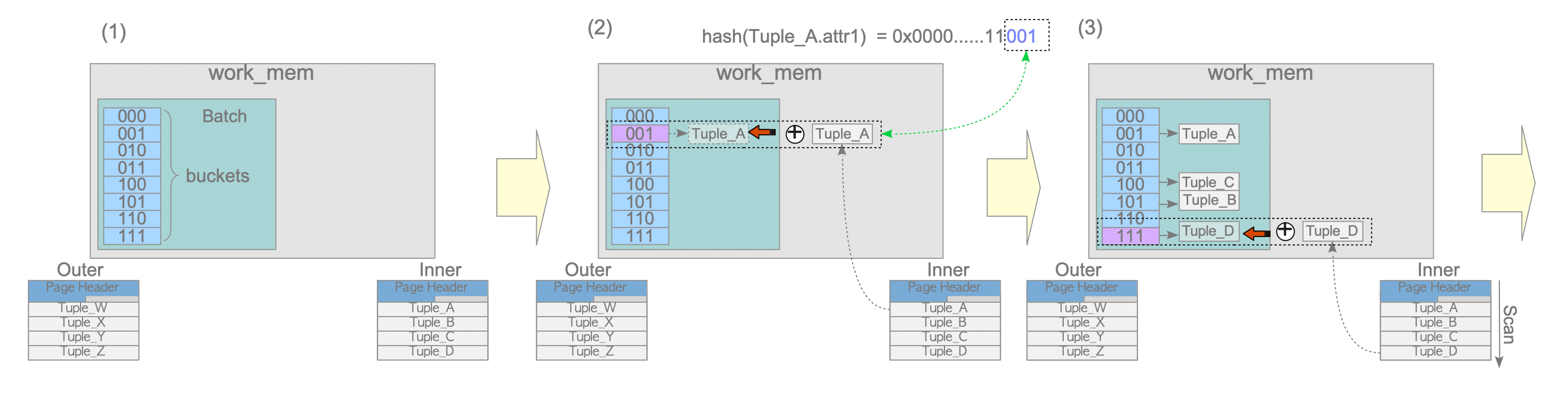
Figure 3.23. Merge join.
If all tuples can be stored in memory, the sorting operations will be able to be carried out in memory itself. Otherwise, temporary files will be used.
A specific example of the EXPLAIN command’s result of the merge join is shown below.
|
|
- Line 9: The executor sorts the inner table tbl_b using sequential scanning (Line 11).
- Line 6: The executor sorts the outer table tbl_a using sequential scanning (Line 8).
- Line 4: The executor carries out a merge join operation; the outer table is the sorted tbl_a and the inner one is the sorted tbl_b.
3.5.2.2. Materialized Merge Join
Same as in the nested loop join, the merge join also supports the materialized merge join to materialize the inner table to make the inner table scan more efficient.
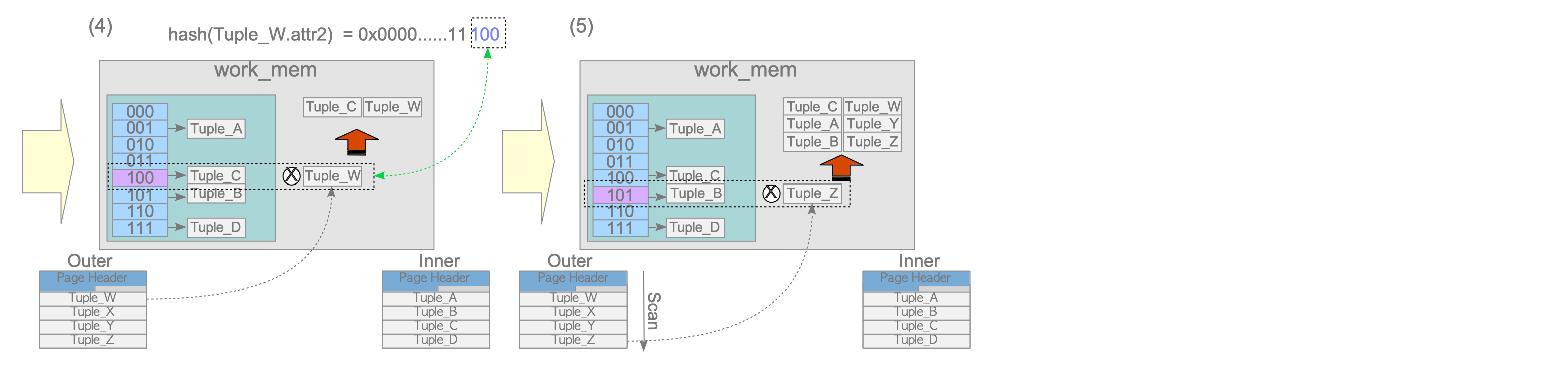
Figure 3.24. Materialized merge join.
An example of the result of the materialized merge join is shown. It is easy to see that the difference from the merge join result above is Line 9: ‘Materialize’.
|
|
- Line 10: The executor sorts the inner table tbl_b using sequential scanning (Line 12).
- Line 9: The executor materializes the result of the sorted tbl_b.
- Line 6: The executor sorts the outer table tbl_a using sequential scanning (Line 8).
- Line 4: The executor carries out a merge join operation; the outer table is the sorted tbl_a and the inner one is the materialized sorted tbl_b.
3.5.2.3. Other Variations
Similar to the nested loop join, the merge join in PostgreSQL also has variations based on which the index scanning of the outer table can be carried out.

Figure 3.25. The three variations of the merge join with an outer index scan.
The results of these joins’ EXPLAIN are shown below:
(a) Merge join with outer index scan
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_nestloop TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND b.id < 1000;
QUERY PLAN
--------------------------------------------------------------------------------------
Merge Join (cost=135.61..322.11 rows=1000 width=16)
Merge Cond: (c.id = b.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8)
-> Sort (cost=135.33..137.83 rows=1000 width=8)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1000 width=8)
Filter: (id < 1000)
(7 rows)(b) Materialized merge join with outer index scan
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_nestloop TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND b.id < 4500;
QUERY PLAN
--------------------------------------------------------------------------------------
Merge Join (cost=421.84..672.09 rows=4500 width=16)
Merge Cond: (c.id = b.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8)
-> Materialize (cost=421.55..444.05 rows=4500 width=8)
-> Sort (cost=421.55..432.80 rows=4500 width=8)
Sort Key: b.id
-> Seq Scan on tbl_b b (cost=0.00..85.50 rows=4500 width=8)
Filter: (id < 4500)
(8 rows)(c) Indexed merge join with outer index scan
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_nestloop TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_d AS d WHERE c.id = d.id AND d.id < 1000;
QUERY PLAN
--------------------------------------------------------------------------------------
Merge Join (cost=0.57..226.07 rows=1000 width=16)
Merge Cond: (c.id = d.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using tbl_d_pkey on tbl_d d (cost=0.28..41.78 rows=1000 width=8)
Index Cond: (id < 1000)
(5 rows)