9.7. Checkpoint Processing in PostgreSQL
In PostgreSQL, the checkpointer (background) process performs checkpoints. This process starts when one of the following events occurs:
-
The interval set in checkpoint_timeout elapses since the previous checkpoint (the default is 300 seconds).
-
In versions 9.4 or earlier, the number of WAL segment files set in checkpoint_segments is consumed since the previous checkpoint (the default is 3).
-
In versions 9.5 or later, the total size of WAL segment files in the
pg_waldirectory (orpg_xlogin versions 9.6 or earlier) exceeds the max_wal_size value (the default is 1GB or 64 files). -
The PostgreSQL server stops in smart or fast mode.
-
A superuser issues the CHECKPOINT command manually.
In versions 9.1 or earlier, as mentioned in Section 8.6, the background writer process performed both checkpointing and dirty-page writing.
The following subsections describe the outline of checkpointing and the pg_control file, which holds metadata for the current checkpoint.
9.7.1. Outline of the Checkpoint Processing
Checkpoint processing has two aspects: preparing for database recovery and cleaning dirty pages in the shared buffer pool.
Figure 9.19 shows an overview of the internal processing.
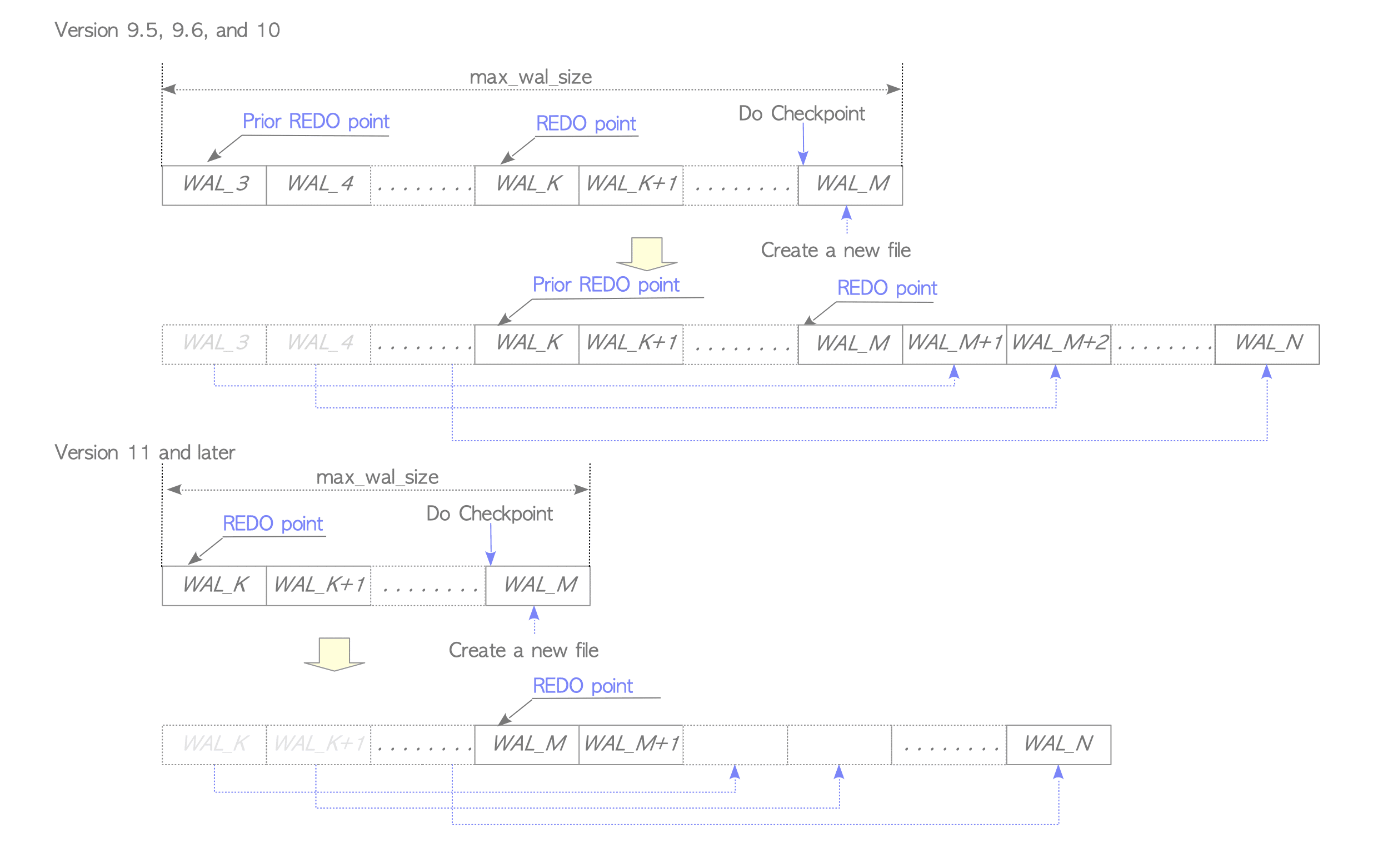
Figure 9.19. Internal processing of PostgreSQL Checkpoint.
-
Store the REDO point: When a checkpoint starts, the checkpointer stores the REDO point in memory. The REDO point is the LSN of the XLOG record written at the moment the checkpoint began. Database recovery starts from this point.
-
Flush shared memory: The checkpointer flushes all data in shared memory (e.g., clog contents) to storage.
-
Flush dirty pages: The checkpointer gradually writes and flushes all dirty pages in the shared buffer pool to storage.
-
Write the checkpoint record: The checkpointer writes a XLOG record for this checkpoint to the WAL buffer. The
CheckPointstructure defines the data portion of this record and contains variables such as the REDO point. The write location of the checkpoint record is called the checkpoint. -
Update pg_control: The checkpointer updates the pg_control file. This file contains fundamental information, such as the checkpoint location.
9.7.2. pg_control File
The pg_control file is essential for database recovery because it contains fundamental checkpoint information. If this file is corrupted or unreadable, the recovery process cannot start because the starting point is missing.
While pg_control stores over 40 items, three items relevant to the next section are shown below:
-
State: The state of the database server when the latest checkpoint started. Total seven states exist, including:
- start up: The system is starting up.
- shut down: The system is shutting down normally.
- in production: The system is running.
-
Latest checkpoint location: The LSN of the latest checkpoint record.
The pg_control file is stored in the $PGDATA/global subdirectory of the base directory.
The pg_controldata utility displays its contents.
$ pg_controldata $PGDATA
pg_control version number: 1300
Catalog version number: 202306141
Database system identifier: 7250496631638317596
Database cluster state: in production
pg_control last modified: Mon Jan 1 15:16:38 2024
Latest checkpoint location: 0/16AF0090
Latest checkpoint's REDO location: 0/16AF0090
Latest checkpoint's REDO WAL file: 000000010000000000000016
... snip ...Up until version 10, PostgreSQL maintained WAL segments containing the last two REDO points — “Latest Checkpoint’s REDO point” and “Prior Checkpoint’s REDO point”. This served as a precaution if the Latest REDO point became unreadable.
However, version 11 and later store only the Latest REDO point to conserve storage space. This change reflects improved storage reliability.
See this thread for more details.