1.4. The Methods of Writing and Reading Tuples
The final section of this chapter describes the methods for writing and reading heap tuples.
1.4.1. Writing Heap Tuples
Consider a table consisting of a single page that contains one heap tuple. In this state, the pd_lower of the page points to the first line pointer, while both the line pointer and pd_upper point to the first heap tuple, as illustrated in Figure 1.6(a).
When a second tuple is inserted, it is placed preceding the first one (stacked from the bottom). A second line pointer is appended to the first, pointing to this new tuple. Consequently, pd_lower is updated to point to the end of the second line pointer, and pd_upper is updated to the beginning of the second heap tuple. See Figure 1.6(b). Other header data within this page (e.g., pd_lsn, pd_checksum, pd_flags) are also updated to appropriate values; further details are provided in Section 5.3 and Section 9.4.
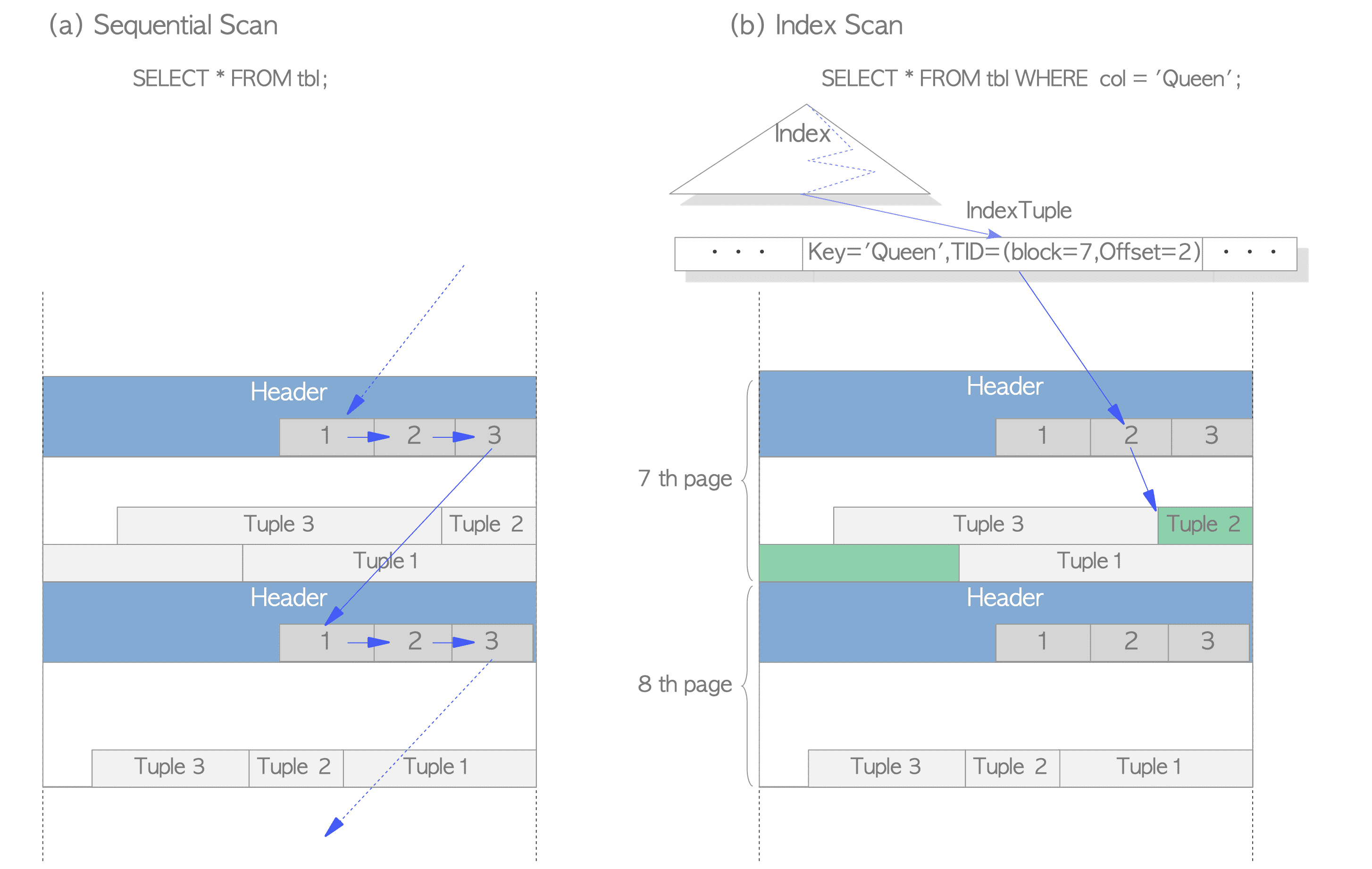
Figure 1.6. Writing a heap tuple.
1.4.2. Reading Heap Tuples
Two typical access methods, sequential scan and B-tree index scan, are outlined below:
-
Sequential scan: This method reads all tuples in all pages sequentially by scanning every line pointer in each page. See Figure 1.7(a).
-
B-tree index scan: This method reads an index file containing index tuples. Each index tuple consists of an index key and a TID pointing to the target heap tuple.
When an index tuple matching the search key is identified1, PostgreSQL retrieves the corresponding heap tuple using the obtained TID.
For example, in Figure 1.7(b), the TID of the retrieved index tuple is ‘(block = 7, offset = 2)’. This indicates the target heap tuple is the 2nd tuple in the 7th page of the table, allowing PostgreSQL to access the data directly without scanning unnecessary pages.

Figure 1.7. Sequential scan and index scan.
PostgreSQL also supports TID-Scan, Bitmap-Scan, and Index-Only-Scan.
TID-Scan is a method that accesses a tuple directly using its TID. For example, to retrieve the 1st tuple in the 0-th page of a table, the following query can be executed:
sampledb=# SELECT ctid, data FROM sampletbl WHERE ctid = '(0,1)';
ctid | data
-------+-----------
(0,1) | AAAAAAAAA
(1 row)Index-Only-Scan will be described in details in Section 7.2.
-
The procedure for finding index tuples within a B-tree index is omitted here, as it is a widely documented concept and space is limited. Please refer to relevant technical documentation for details. ↩︎