9.1. Overview
This section provides an overview of the Write-Ahead Logging (WAL) mechanism.
The first subsection illustrates the risks of system crashes in a database without WAL. The second subsection introduces key concepts, such as WAL data writing and the recovery process. The final subsection describes full-page writes, a critical concept for data integrity.
In this section, the examples use a table named TABLE_A, which contains a single page.
9.1.1. Insertion Operations without WAL
Every DBMS implements a shared buffer pool to provide efficient access to relation pages.
Figure 9.1 illustrates a scenario where data tuples are inserted into TABLE_A on a PostgreSQL server that does not implement WAL.
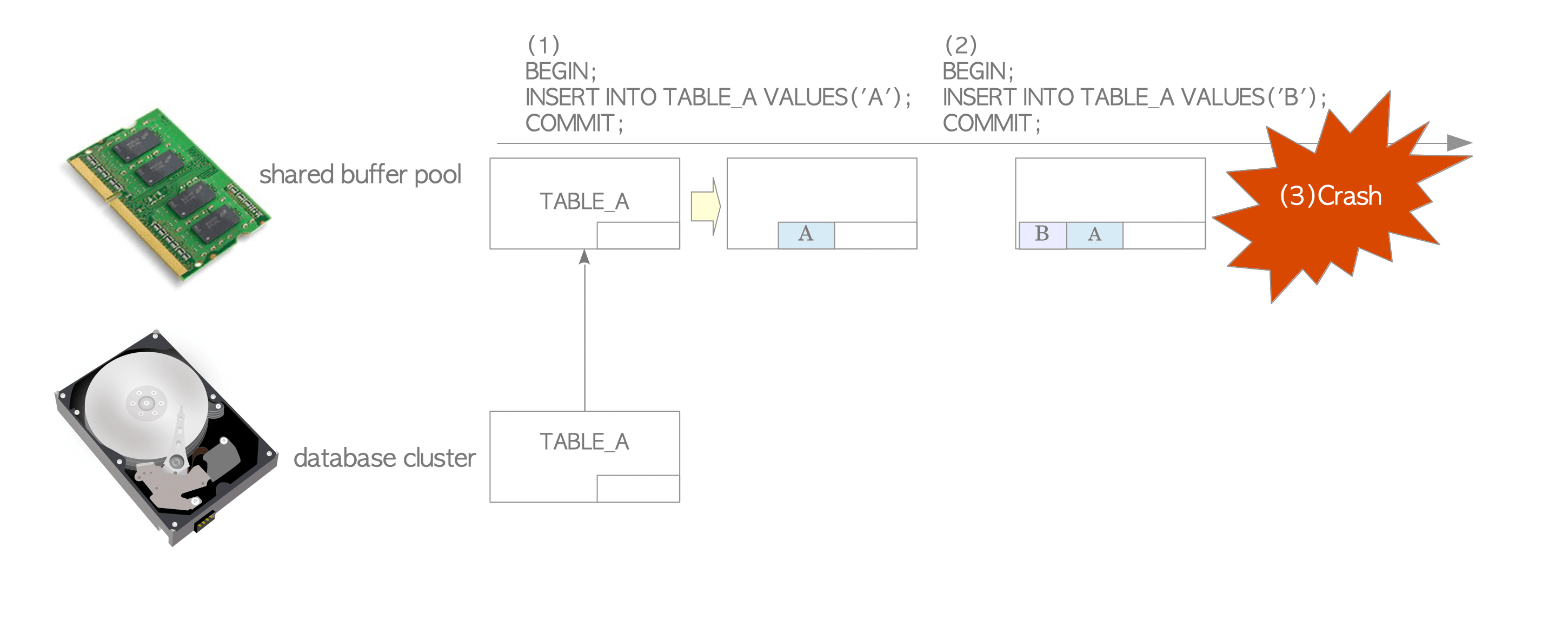
Figure 9.1. Insertion operations without WAL.
-
When the first INSERT statement is issued, PostgreSQL loads the TABLE_A page from the database cluster into the shared buffer pool and inserts a tuple. This modified page is called a dirty page. The page is not written to storage immediately.
-
When the second INSERT statement is issued, PostgreSQL inserts a new tuple into the page in the buffer pool. The page still remains only in memory.
-
If the operating system or PostgreSQL server fails (e.g., due to a power failure), all inserted data in the memory is lost.
A database without WAL is therefore vulnerable to system failures.
Before version 7.1, PostgreSQL performed synchronous disk writes by issuing a sync system call whenever a page changed in memory.
While this ensured durability, it resulted in poor performance for modification commands like INSERT, UPDATE and DELETE.
9.1.2. Insertion Operations and Database Recovery
PostgreSQL supports WAL to prevent data loss without compromising performance. This subsection describes key concepts, WAL data writing, and database recovery.
PostgreSQL records all modifications as history data in persistent storage. This history data is known as XLOG records or WAL data.
Change operations, such as insertion, deletion, or commit actions, write XLOG records into the in-memory WAL buffer. These records are flushed to a WAL segment file on storage when a transaction commits or aborts. (Other triggers for writing XLOG records are described in Section 9.5.) The LSN (Log Sequence Number) represents the unique ID and the specific location of an XLOG record within the transaction log.
When considering database recovery, an immediate question comes to mind: where exactly does PostgreSQL start recovering from? The answer is the REDO point. The REDO point is the location of the XLOG record written at the moment the latest checkpoint started. (Checkpoints are described in Section 9.7.) The recovery process and the checkpoint process are inseparable.
The WAL and checkpoint process were implemented at the same time in version 7.1.
Figure 9.2 and the following steps describe tuple insertion with WAL.
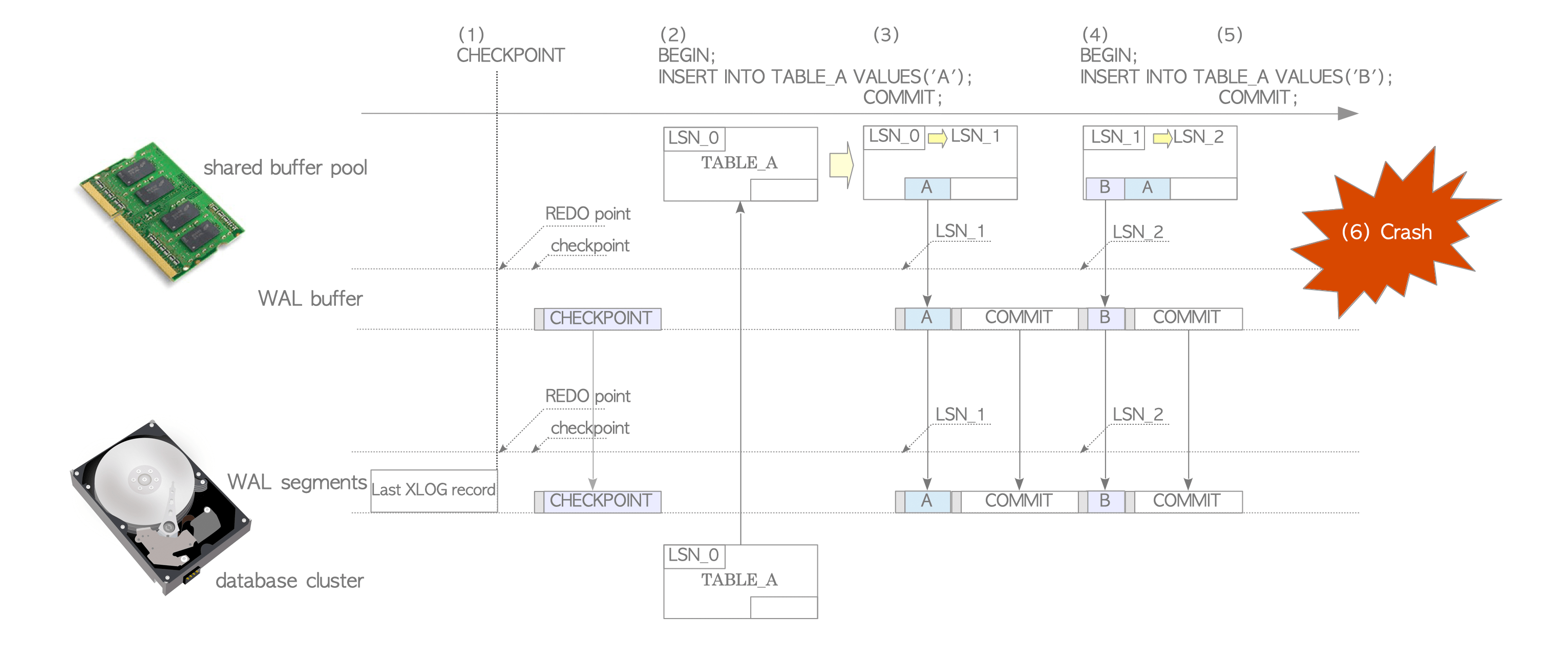
Figure 9.2. Insertion operations with WAL.
“TABLE_A’s LSN” shows the value of ‘pd_lsn’ within the page-header of TABLE_A. “Page’s LSN” is the same manner.
-
The checkpointer (a background process) periodically performs checkpointing. At the start of a checkpoint, it writes a checkpoint record containing the latest REDO point to the WAL segment.
-
When the first INSERT statement is issued, PostgreSQL loads the TABLE_A page into the shared buffer pool and inserts a tuple. It then writes an XLOG record of this statement into the WAL buffer at LSN_1 and updates the page header (pd_lsn) of TABLE_A from LSN_0 to to LSN_1.
-
When the transaction commits, PostgreSQL writes a commit XLOG record to the WAL buffer and flushes all records from LSN_1 to the WAL segment file.
-
When the second INSERT statement is issued, PostgreSQL inserts a new tuple, writes an XLOG record at LSN_2, and updates the TABLE_A’s LSN to LSN_2.
-
When this transaction commits, PostgreSQL flushes the XLOG records as in step (3).
-
If a system failure occurs, the data in the shared buffer pool is lost. However, all modifications have been persisted in the WAL segment files.
Upon restarting, PostgreSQL automatically enters recovery mode. It reads and replays XLOG records sequentially from the REDO point (Figure 9.3).
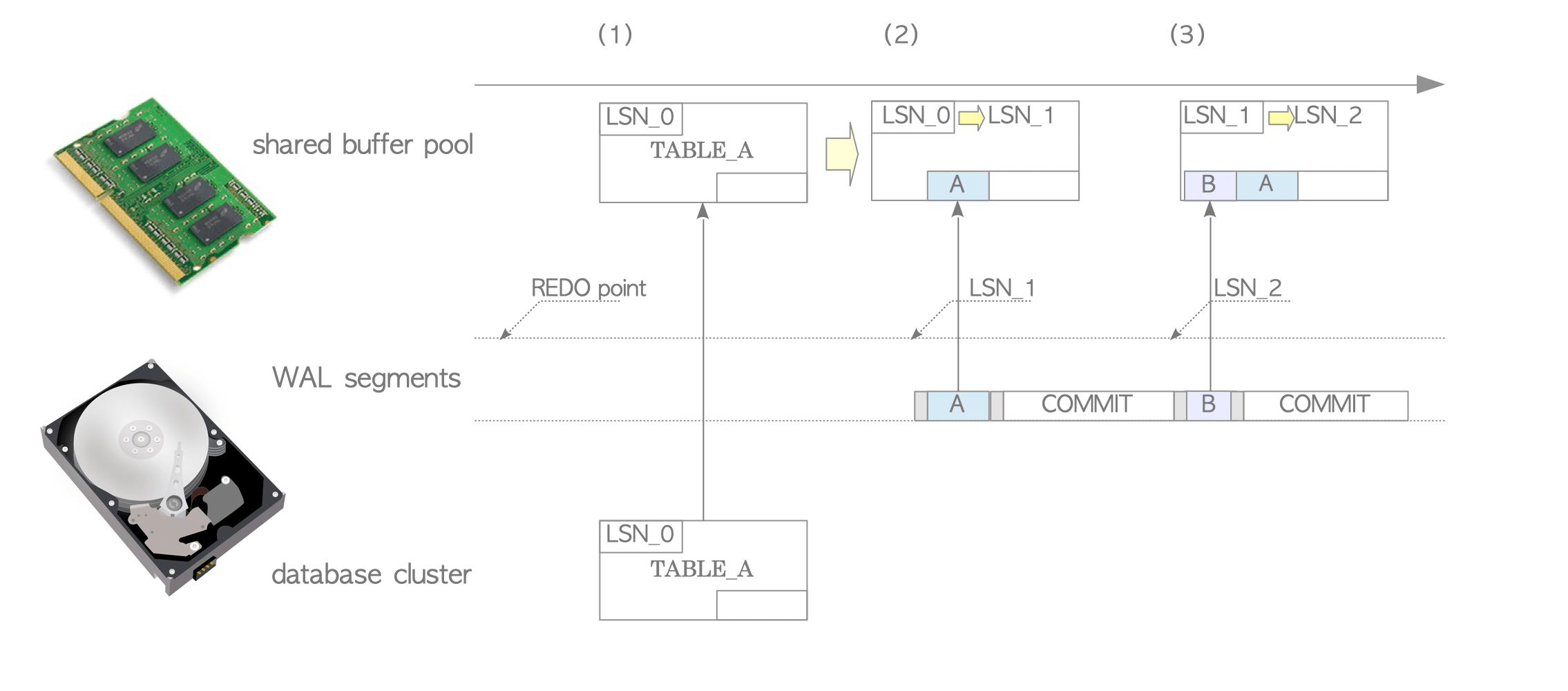
Figure 9.3. Database recovery using WAL.
-
PostgreSQL reads the first INSERT XLOG record and loads the TABLE_A page from storage into the shared buffer pool.
-
Before replaying, PostgreSQL compares the LSN of the XLOG record with the LSN of the page. Replay rules are as follows:
- If the XLOG record’s LSN is newer (larger) than the page’s LSN, the data portion of the record is inserted into the page, and the page’s LSN is updated.
- If the XLOG record’s LSN is older (smaller), the record is skipped.
-
PostgreSQL replays all remaining records in chronological order.
Although writing XLOG records certainly carries a minor cost, it pales in comparison to the overhead of writing entire modified pages. There is no doubt that the gained system failure tolerance is well worth the investment.
9.1.3. Full-Page Writes
If the operating system fails while a dirty page is being written, the page data on storage may become corrupted. XLOG records cannot be replayed on a corrupted page.
To handle this, PostgreSQL uses full-page writes. When enabled, PostgreSQL writes the entire page as an XLOG record during the first modification of that page after a checkpoint. This record is called a backup block (or full-page image).
Figure 9.4 illustrates insertion with full-page writes enabled.
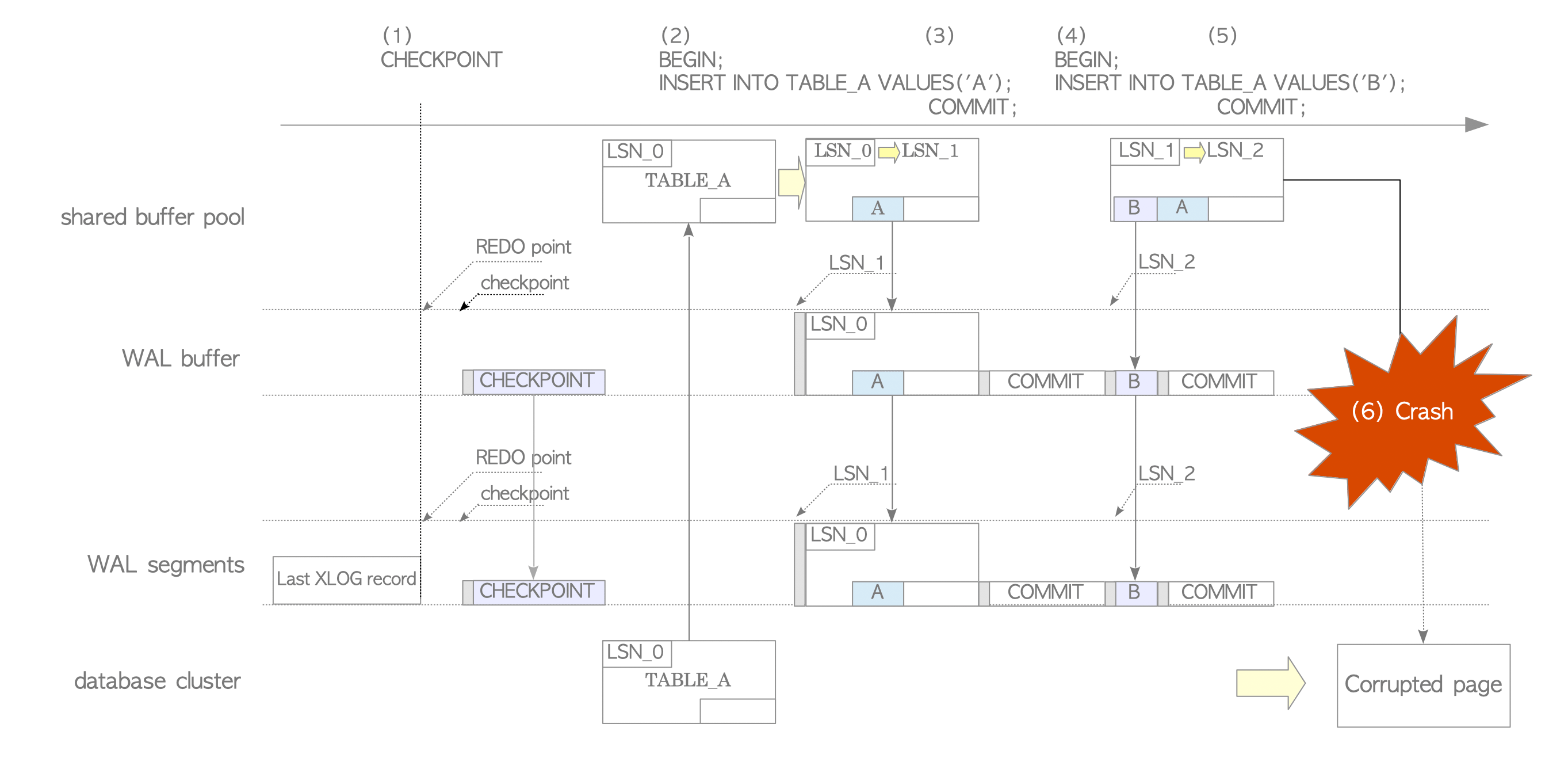
Figure 9.4. Full page writes.
- The checkpointer starts a checkpoint.
- The first INSERT statement triggers the creation of a backup block because it is the first modification of the page since the checkpoint.
- The transaction commits and flushes the buffer as usual.
- The second INSERT statement creates a standard XLOG record (not a backup block) because the page was already modified once since the checkpoint.
- The transaction commits.
- An operating system failure occurs while the checkpointer is writing the modified TABLE_A page to storage, resulting in a corrupted page on the storage disk.
Figure 9.5 illustrates the recovery process.
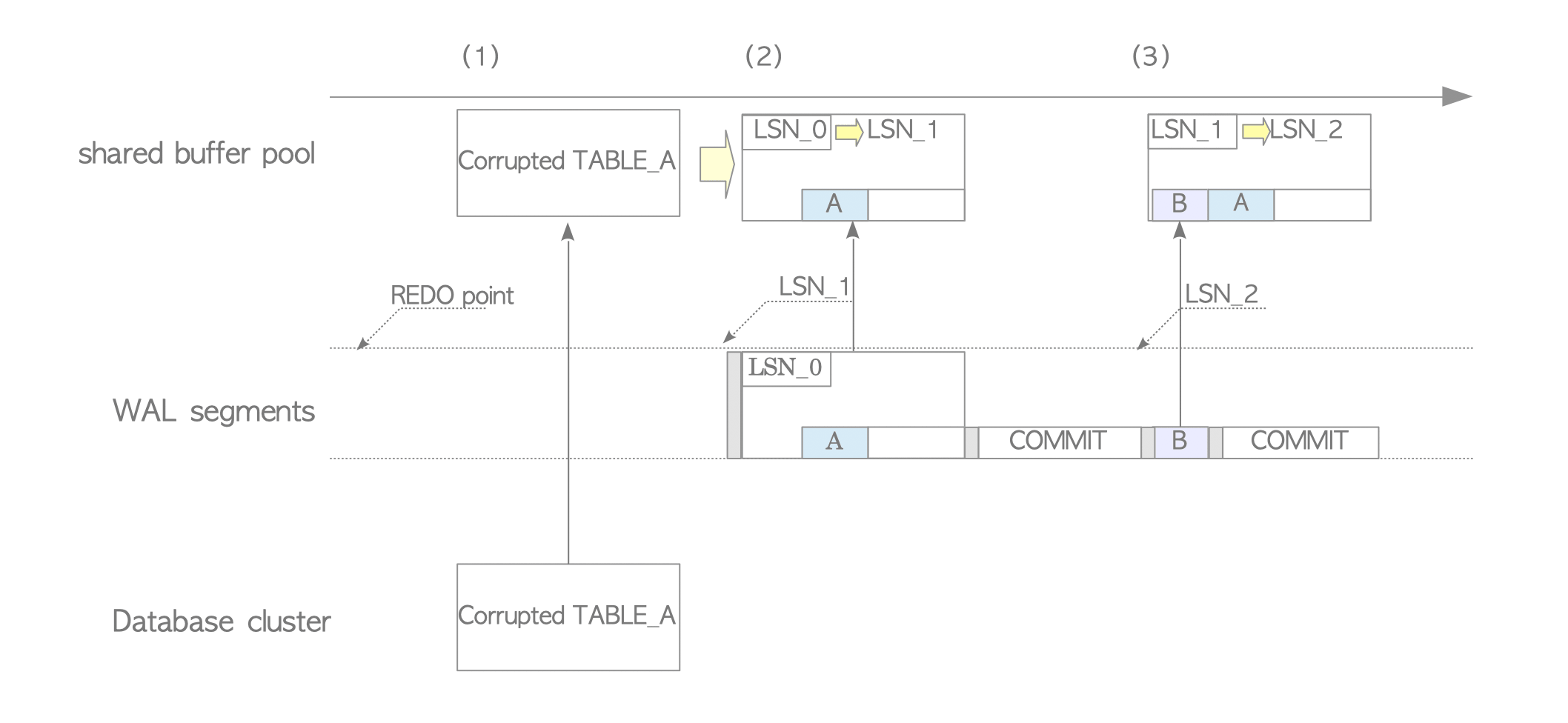
Figure 9.5. Database recovery with backup block.
- PostgreSQL reads the first XLOG record and loads the corrupted page into the buffer pool.
- Since the record is a backup block, the entire page content is overwritten onto the corrupted page regardless of the LSN values. The page LSN is updated to LSN_1. This restores the corrupted page.
- Subsequent non-backup blocks are replayed using the standard LSN comparison rule.
This mechanism ensures database recovery even if data write errors occur due to a crash.
As mentioned above, WAL prevents data loss due to process or operating system crashes. However, data is lost if a file system or media failure occurs. To address such failures, PostgreSQL provides online backup and replication features.
-
Regular online backups allow the database to be restored from the most recent backup even after a media failure. However, changes made after the last backup cannot be restored using only that backup.
For instance, even with a daily backup taken at 0:00, if a file system failure occurs at 8:00, all changes from 0:00 to the point of failure are lost.
-
The synchronous replication feature stores all changes to another storage or host in real time. If a media failure occurs on the primary server, the data can be restored from the secondary server.
For more information, see Chapters 10, 11 and 12, respectively.
No. Synchronous replication does not eliminate the need for backups.
DBMS operation requires addressing not only hardware or software failures but also data loss caused by human error or software bugs.
For instance, if critical data is accidentally deleted, the deletion is reflected immediately on the standby server. Similarly, if erroneous data is written due to a mistake, the error propagates instantly across all replication servers.
In such cases, replication cannot restore the lost or corrupted data. The only way to recover from these failures is by using backup data (+ archive logs).