12.1. Overview
Alpha Version: Work in progress.
This section introduces key concepts that are necessary to understand the descriptions in the subsequent sections.
12.1.1. Related Processes
In logical replication, four types of processes work cooperatively:
- A walsender on the Publisher mainly sends WAL data to the Subscriber, and does some various jobs.
- A logical replication launcher on the Subscriber launches apply workers.
- An apply worker on the Subscriber establishes a connection with the publisher’s walsender, receives the stream of logical changes, parses these messages, and updates the target tables accordingly.
- A table sync worker on the Subscriber performs the initial data synchronization for a specific table, catching up to the main replication stream before handing over further updates to the apply worker. Refer to Section 12.2.2 for details.
12.1.2. Outline of Logical Replication
PostgreSQL’s logical replication is inherently row-based. It captures changes to individual rows and streams them in a decoded format, ensuring consistency even when using non-deterministic functions, while remaining independent of the physical storage layout.
To provide a clearer overview, the following example compares logical replication with streaming replication, as illustrated in Figure 12.2.
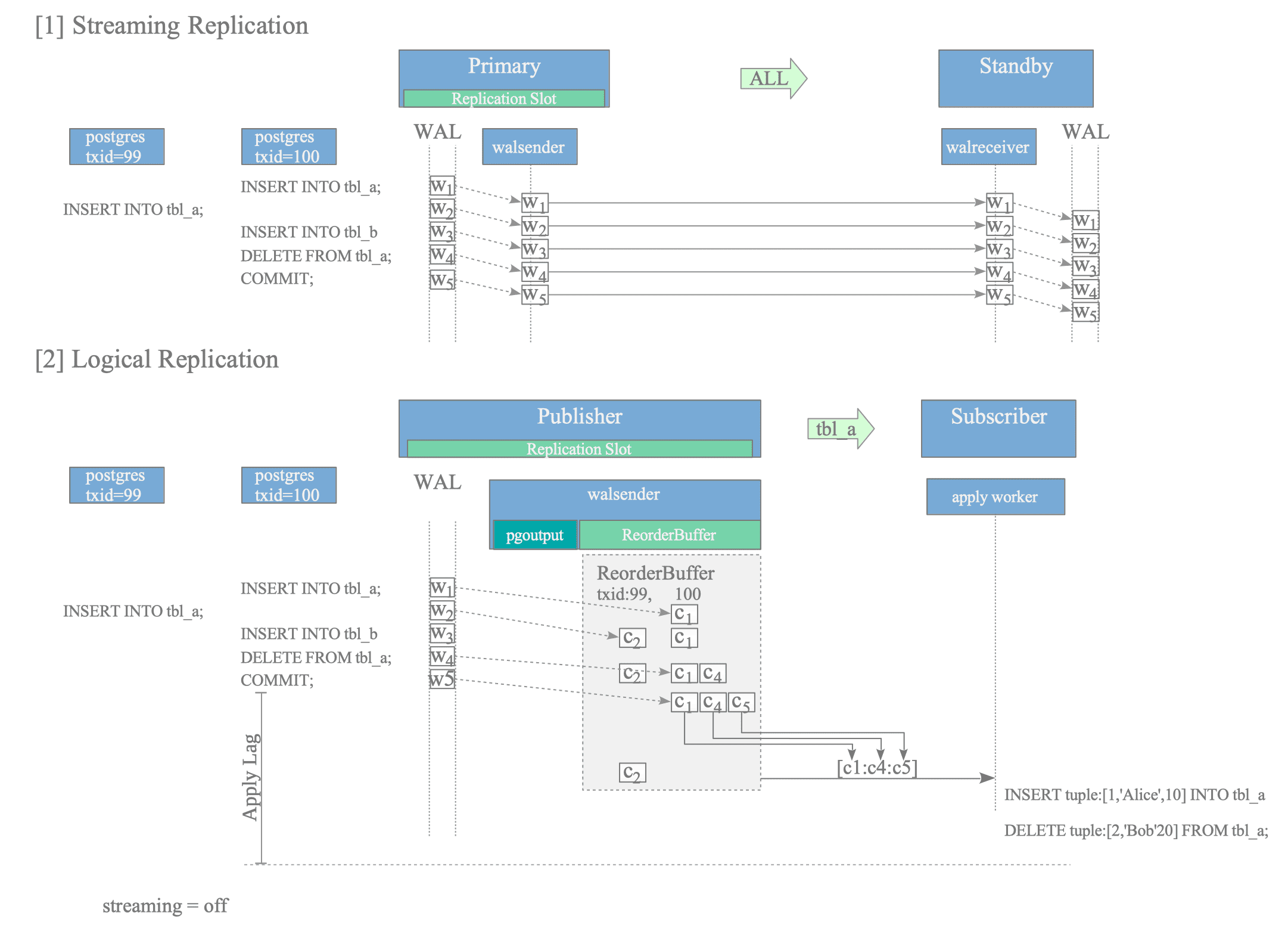
Figure 12.2. Conceptual comparison of data sending: Streaming vs. Logical Replication.
Consider a scenario where two concurrent transactions (txid=99 and 100) execute SQL statements affecting tbl_a and tbl_b.
In streaming replication, WAL data ($w_{1}$ to $w_{5}$) are written to the WAL file sequentially as each SQL statement is executed. The walsender reads these records and sends them immediately to the walreceiver on the standby server, regardless of the transaction’s commit status. The walreceiver then writes the received WAL data into its own WAL file in the exact order it was received, maintaining a physical mirror of the primary server.
In contrast, logical replication processes data based on transaction boundaries and publication scopes. While the walsender reads the WAL data as it is generated, it does not send it immediately. Instead, it accumulates the changes in a memory area called the ReorderBuffer, where changes are reassembled per transaction.
The operation of the ReorderBuffer within the walsender involves the following three processes:
- Filtering: The walsender filters the decoded changes based on the publication’s scope. Even after txid=100 commits, only the changes related to subscribed tables are prepared for sending. For instance, if the subscriber only tracks tbl_a, the change $c_{3}$ (decoded from $w_{3}$ for tbl_b) is discarded. Refer Section 12.4.1 for details.
- Decoding & Buffering: As the walsender reads the WAL, it decodes each WAL record $w_{n}$ into a corresponding logical change $c_{n}$ and stores it in the ReorderBuffer. Refer Section 12.4.3 for details.
- Sending: Upon encountering the commit record $w_{5}$ for txid=100, the walsender gathers the relevant buffered changes — specifically $c_{1}$ and $c_{4}$ — and sends them to the subscriber as a single series of messages, finalized by the commit message $c_{5}$. (Changes from uncommitted transactions, such as $c_{2}$ derived from $w_{2}$ of txid=99, remain buffered and are not yet eligible for sending.) Refer Section 12.6 for details.
The structure of ReorderBuffer will be discribed in Section 12.3.
Because these logical messages contain the already-evaluated results of the operations, logical replication inherently avoids inconsistencies caused by non-deterministic functions like random() or now().
While the output process is extensible via plugins to support various formats, PostgreSQL provides the pgoutput plugin by default for standard logical replication. Refer Section 12.5 for details.
The subscriber’s apply worker achieves replication by reconstructing and executing transactions based on the received messages. Further details are provided in Section 12.7.
12.1.2.1. Asynchronous vs. Synchronous
PostgreSQL’s logical replication supports both asynchronous and synchronous modes, with asynchronous being the default.
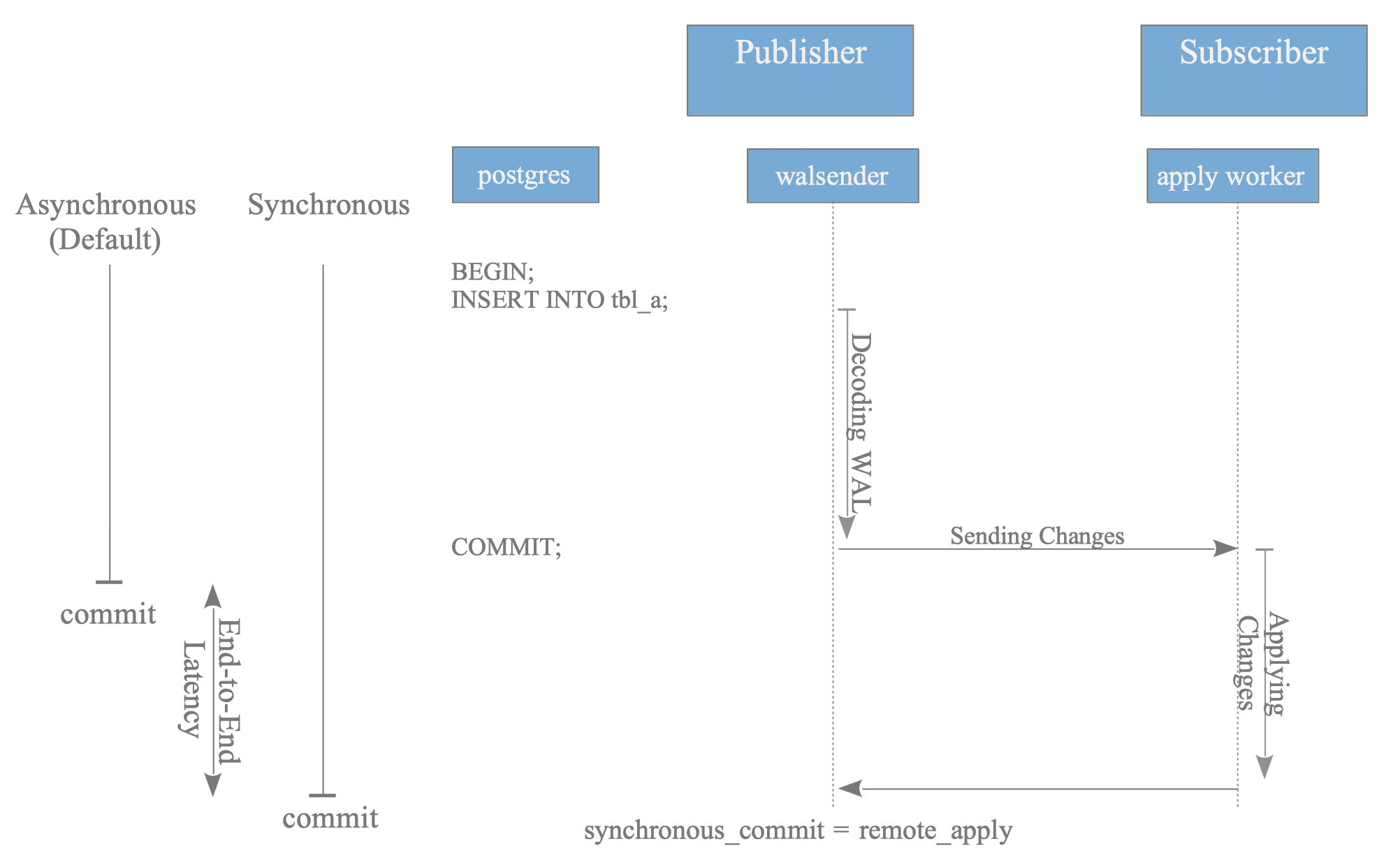
Figure 12.3. Comparison of transaction flow in asynchronous and synchronous logical replication modes.
In asynchronous mode, a COMMIT statement on the publisher completes immediately after the local WAL is flushed, without waiting for a response from the subscriber.
In synchronous mode (specifically when synchronous_commit is set to remote_apply), the publisher’s commit process remains in a wait state until it receives an acknowledgment (ACK) from the subscriber. As illustrated in Figure 12.3, the apply worker sends this ACK only after it has successfully finished applying the changes to the subscriber’s database.
The additional time required for the synchronous commit to finalize, compared to the asynchronous mode, is defined as the End-to-End Latency.
As illustrated in Figure 12.3, transactions involving a larger volume of changes naturally require more time for decoding, network transmission, and application. Consequently:
- In asynchronous mode, an increased transaction volume results in a larger replication lag, thereby extending the window of data inconsistency between the publisher and the subscriber.
- In synchronous mode, the same volume translates into higher commit latency on the publisher side, as the backend process must wait for the entire end-to-end replication pipeline to finalize.
12.1.2.2. Management and Optimization of Large Transactions
This section examines the behavior of “Large Transactions” — those involving a significant volume of changes—and describes the evolution of optimization techniques across PostgreSQL versions.
[1] Standard Transaction Processing (streaming = off)
When the volume of changes exceeds the publisher’s ReorderBuffer capacity, specifically the logical_decoding_work_mem threshold, data is temporarily persisted to spill files on disk. This mechanism is illustrated in Figure 12.4 [1].
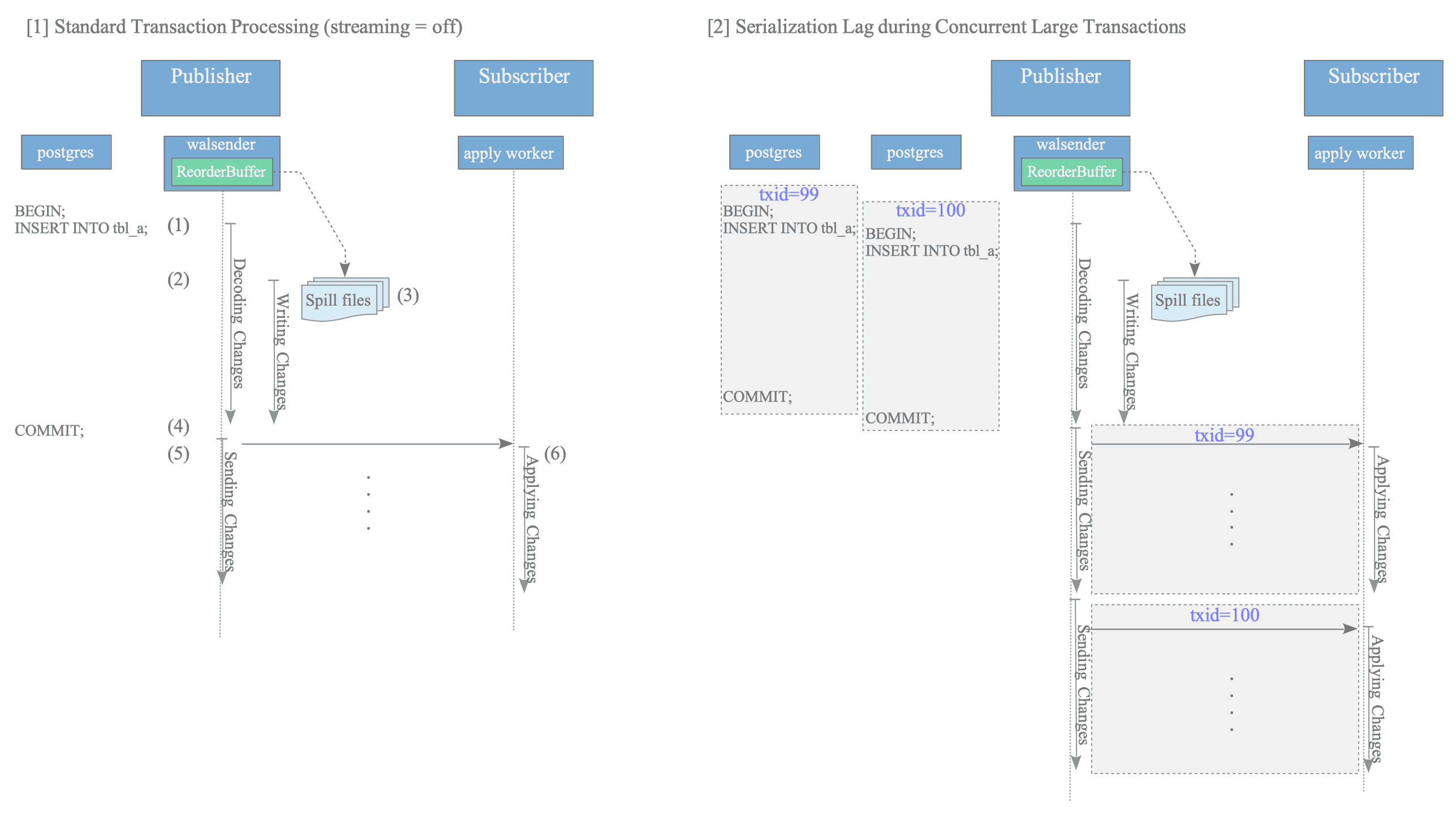
Figure 12.4: Behavior of large transactions when streaming is disabled
The processing flow is as follows:
- A substantial number of INSERT operations are executed on table tbl_a, and the changes decoded from the WAL accumulate in the ReorderBuffer.
- Upon exceeding the memory limit, the ReorderBuffer scans the currently held change records.
- Spill files are generated, and memory-overflow data is moved to disk to free up buffer space.
- The transaction is COMMITTED on the publisher side.
- Only after the commit is detected does the walsender begin sending the changes—aggregated from both spill files and memory—to the subscriber.
- The apply worker sequentially applies the change messages received over the network to the target table.
Detailed mechanics regarding the creation and management of spill files are provided in Section 12.4.4.
Under this configuration, if multiple large transactions occur concurrently, the walsender is restricted to sending changes for only one transaction at a time per replication connection. Consequently, the application of changes on the subscriber side is serialized, which often results in significant replication lag, as shown in Figure 12.4 [2].
[2] In-Progress Streaming of Large Transactions (Version 14 and Later)
Introduced in version 14, this feature facilitates the pre-emptive sending of change data to subscribers before a transaction commit, thereby mitigating transfer overhead and reducing overall replication lag. This mechanism is illustrated in Figure 12.5 [1].
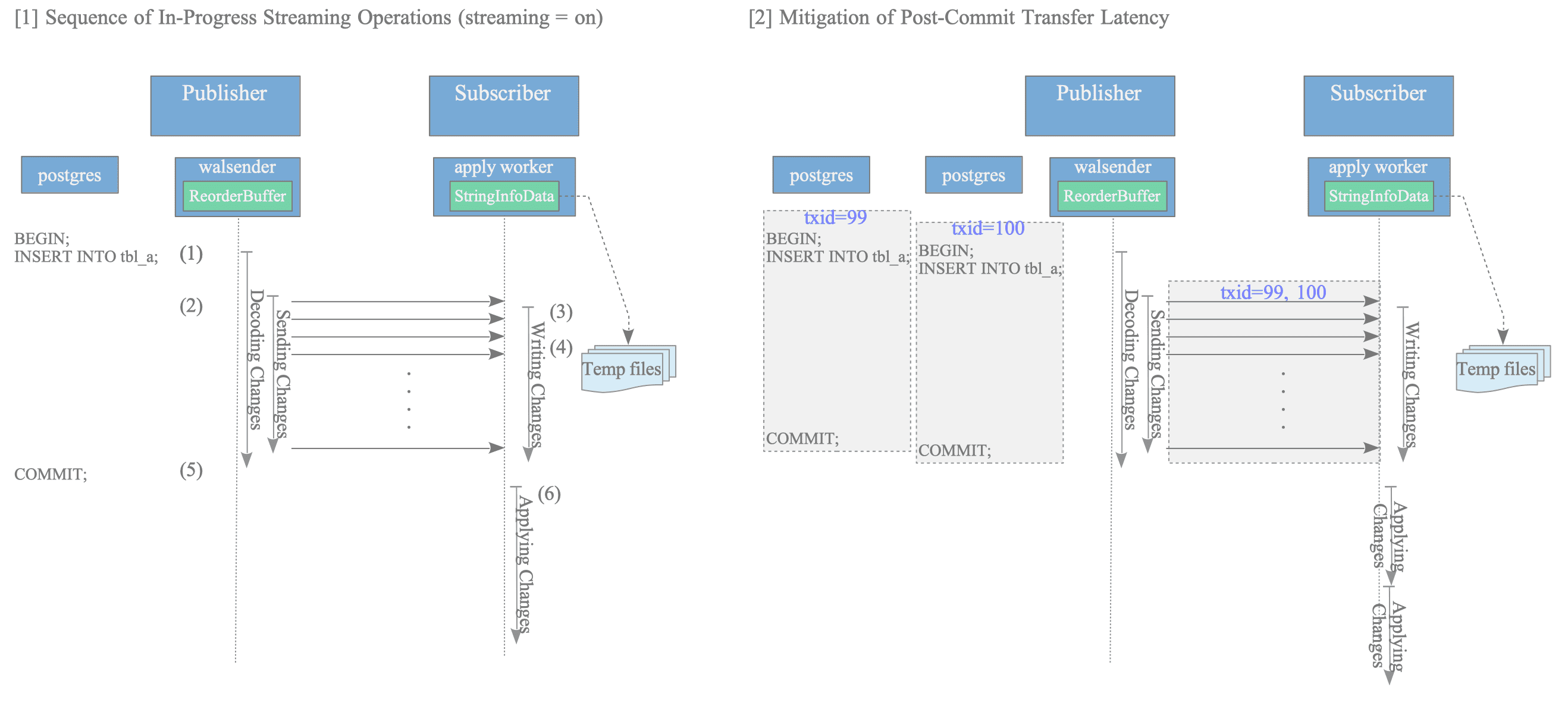
Figure 12.5: Mechanism of in-progress streaming for large transactions
The operational flow for streaming large transactions is as follows:
- A substantial volume of INSERT operations is executed, leading to data accumulation in the ReorderBuffer.
- Upon exceeding the memory threshold defined by logical_decoding_work_mem, the walsender initiates the sending of change data immediately, without waiting for the transaction to commit.
- The apply worker on the subscriber buffers the incoming data in memory using a
StringInfoDatastructure named original_msg. - If the subscriber-side memory limit is reached, the data is persisted to Temp files.
- The transaction is COMMITTED on the publisher.
- The apply worker retrieves the data previously sent from the local Temp files (or memory) and applies the changes to the target tables.
Note that, unlike the walsender which manages changes within a structured ReorderBuffer, the apply worker buffers the incoming changes as a raw binary stream within a generic StringInfoData structure (original_msg).
Streaming is enabled by setting the streaming = on parameter within the CREATE SUBSCRIPTION command. It should be noted that the maximum capacity of the message buffer in the apply worker is also governed by the logical_decoding_work_mem setting. Detailed mechanics regarding the management of temp files are provided in Section 12.7.2.1.
This method effectively eliminates the significant transfer latency that traditionally occurs after a transaction commit. As illustrated in Figure 12.5 [2], even in the presence of multiple concurrent large transactions, pre-emptive data transfer ensures that the application process on the subscriber side begins promptly following the commit, significantly improving replication efficiency.
[3] Parallel Application of Streamed Changes (Version 16 and Later)
From version 16 onwards, the capability to parallelize the application process itself during streaming—prior to the transaction commit—has been introduced. This represents a significant advancement over previous versions where only data transfer was overlapped. This mechanism is illustrated in Figure 12.6 [1].
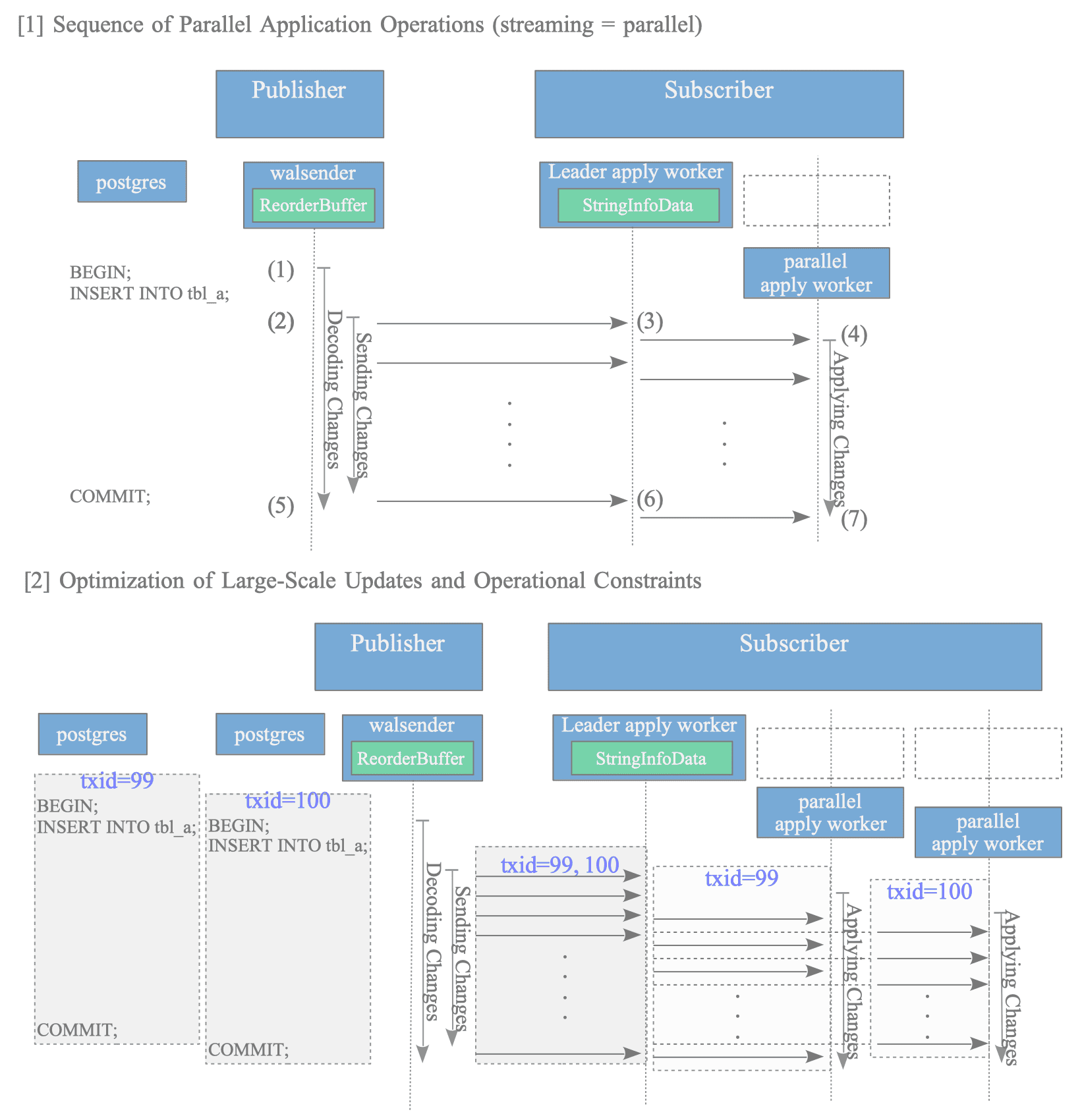
Figure 12.6: Mechanism and efficiency of parallel apply workers during streaming
The processing flow for parallel streaming is as follows:
- Substantial INSERT operations lead to data accumulation within the ReorderBuffer.
- Upon exceeding the memory threshold, the walsender initiates the sending of change data.
- The leader apply worker receives the stream data and dispatches the data to a parallel apply worker.
- The parallel apply worker immediately begins applying the changes to the target tables.
- The COMMIT statement is executed on the publisher.
- The leader apply worker receives the commit message from the walsender and sends it to the parallel apply worker.
- The parallel apply worker completes the local transaction and finalizes the application of changes.
Parallel application is enabled by specifying streaming = parallel in the CREATE SUBSCRIPTION command.
This architecture enables an almost total overlap between transaction processing on the publisher and the application of changes on the subscriber. Consequently, replication lag during large-scale updates is drastically reduced, as demonstrated in Figure 12.6 [2].
However, parallel execution is not guaranteed in every scenario. For instance, if the number of active workers reaches the max_parallel_apply_workers_per_subscription limit, the subscriber reverts to serial application upon commit—matching the behavior of streaming=on. Further details regarding these constraints are discussed in Section 12.7.3.
12.1.3. Replica Identity
Since PostgreSQL logical replication is row-based, it operates on logical data rows rather than physical storage layouts (such as blocks or offsets). Consequently, when executing UPDATE or DELETE operations on the subscriber, the system requires a “search key” to identify exactly which row to modify. This configuration is known as the Replica Identity.
If a proper Replica Identity is not defined, the subscriber cannot uniquely identify the target rows. This may cause the replication process to stop with an error or lead to unintended data modifications. To prevent such issues, if a table lacks a Replica Identity, the publisher will reject any UPDATE or DELETE attempts on that table by returning an error:
testdb=# UPDATE tbl SET data = 'updated_value' WHERE id = 1;
ERROR: cannot update table "tbl" because it does not have a replica identity and publishes updates
HINT: To enable updating the table, set REPLICA IDENTITY using ALTER TABLE.12.1.3.1. Types of Replica Identity
PostgreSQL provides four modes for Replica Identity, which can be configured on a per-table basis:
| Mode | Description | Usage and Characteristics |
|---|---|---|
| DEFAULT | Uses the Primary Key columns as the identifier. | This is the default mode; it is automatically applied when a Primary Key is defined. |
| USING INDEX | Uses a specific unique, non-null index as the identifier. | Useful for tables without a Primary Key where a specific unique index can serve as the key. |
| FULL | Records the old values of all columns in the row. | Required for tables with no unique constraints. Note that this increases the message size compared to other identities; see Section 12.4.3 for details. |
| NOTHING | Records no identity information. | This is the default for tables without a PK. INSERT operations are allowed, but UPDATE and DELETE cannot be replicated. |
12.1.3.2. Configuration and Verification
The Replica Identity is configured using the ALTER TABLE … REPLICA IDENTITY command. When a Primary Key is created, the mode is automatically set to DEFAULT.
Example: Specifying a unique index
testdb=# CREATE TABLE tbl_ri (id int NOT NULL, name text, data int NOT NULL);
testdb=# CREATE UNIQUE INDEX tbl_ri_idx ON tbl_ri (id, data);
testdb=# ALTER TABLE tbl_ri REPLICA IDENTITY USING INDEX tbl_ri_idx;Example: Configuration to FULL
testdb=# CREATE TABLE tbl_ri_full (id int, name text, data int);
testdb=# ALTER TABLE tbl_ri_full REPLICA IDENTITY FULL;Each table’s Replica Identity configuration is stored in the relreplident column of the pg_class system catalog. This configuration can be verified the following SQL query:
testdb=# -- Values: 'd' (default), 'n' (nothing), 'f' (full), 'i' (index)
testdb=# SELECT relname, relreplident FROM pg_class WHERE relname = 'tbl_ri';
relname | relreplident
---------+--------------
tbl_ri | i
(1 row)
testdb=# SELECT relname, relreplident FROM pg_class WHERE relname = 'tbl_ri_full';
relname | relreplident
-------------+--------------
tbl_ri_full | f
(1 row)While pg_class.relreplident indicates the type of Replica Identity being used, it does not store the specific index OID. Instead, when “REPLICA IDENTITY USING INDEX” is configured, the designated index is recorded in the pg_index system catalog. Specifically, the indisreplident column (a boolean type) is set to true for the chosen index.
The following SQL query can be used to identify which specific index is serving as the Replica Identity for a given table:
testdb=# SELECT rel.relname AS table_name, idx_rel.relname AS index_name
FROM pg_class rel
JOIN pg_index idx ON rel.oid = idx.indrelid
JOIN pg_class idx_rel
ON idx.indexrelid = idx_rel.oid
WHERE rel.relname = 'tbl_ri' AND idx.indisreplident = true;
table_name | index_name
------------+------------
tbl_ri | tbl_ri_idx
(1 row)12.1.4. Replication Origin
Replication Origin is a concept to identify the source of a data change. It serves two primary purposes:
- Tracking Replication Progress (Recovery Control): When applying data received from an external node, the subscriber records the publisher’s COMMIT LSN (Log Sequence Number) within its own applied commit WAL data. By maintaining this mapping between the publisher’s LSN and the subscriber’s local WAL LSN, the system ensures that logical replication can accurately resume from the correct “origin” after an interruption, such as a system failure.
- Prevention of Infinite Replication Loops (Circular Replication): In complex topologies like bidirectional replication, a change sent from Node A to Node B might inadvertently be sent back to Node A. By “stamping” each change with an origin, the system distinguishes between local changes and those received via replication, thereby preventing redundant re-transmissions.
While Replication Origin is a complex concept deeply integrated into the logical replication framework, its most fundamental element is the origin_id. This is a local identifier used by a subscriber to internally distinguish between different publishers (origins).
The mechanisms for tracking replication progress are fundamentally embedded within the logical replication architecture and are detailed in Section 12.8. The remainder of this section focuses on the prevention of infinite loops, a feature introduced in version 16.
It is crucial to understand that an origin_id is not a cluster-wide or globally unique identifier. Instead, it is a strictly local value assigned internally by a subscriber to distinguish between the multiple publishers it connects to.
Because of this, the specific numeric value of an origin_id carries no significance to other nodes in the replication topology beyond a simple binary distinction: is it zero or non-zero?
- An origin_id of 0 signifies changes from transactions originally executed on that publisher.
- An origin_id of 1 or greater signifies that the publisher was replaying (applying) changes received from an upstream source.
12.1.4.1. Preventing Infinite Replication Loops via Replication Origin
PostgreSQL logical replication allows subscriber-side tables to remain writable. By leveraging this characteristic and configuring two nodes to function simultaneously as both publishers and subscribers, active-active replication (multi-primary configuration) can be achieved (see Figure 12.7 [1]).
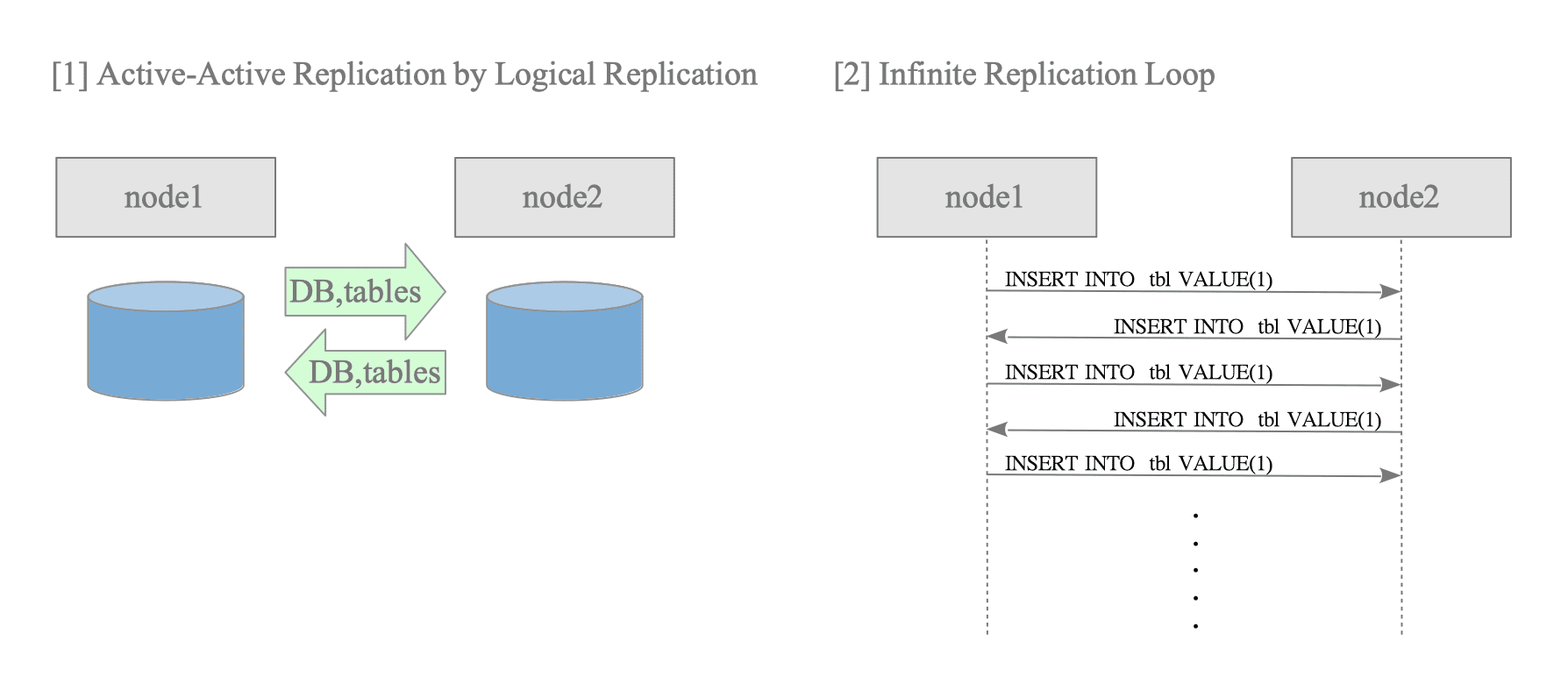
Figure 12.7. Active-Active replication and the infinite replication loop.
Prior to version 16, the standard logical replication feature unconditionally forwarded all decoded changes to downstream subscribers. Consequently, when bidirectional replication was configured between two nodes, a change originating on node 1 would propagate to node 2; node 2 would then treat this as a “new local change” and send it back to node 1. This unstoppable chain of events is known as an infinite replication loop (or circular replication).
To address this issue, the following mechanism was introduced in version 16. Although the underlying architecture is versatile and capable of complex routing, the current implementation is governed by the following behaviors:
- origin = any (Default): The walsender sends changes to downstream subscribers regardless of whether the WAL was generated locally or by applying messages received from a publisher.
- origin = none: WAL records generated by applying messages from an external node are excluded from sending by the walsender.
The origin setting is a configuration option available in the CREATE SUBSCRIPTION command.
Internal Mechanism and Filtering Sequence
The identification and filtering of origins are managed through coordination between the subscriber and the publisher:
- Origin Stamping: When the subscriber’s apply worker commits (or aborts) a transaction, it attaches an origin_id to the COMMIT (or ABORT) WAL record1. In current implementations, a non-zero integer is assigned to changes originating from external nodes.
- Evaluation by walsender: While decoding a transaction in the ReorderBuffer, the walsender of the publisher examines the origin information within the COMMIT WAL record.
- Execution of Filtering: If origin = none is configured and an origin_id is present in the COMMIT WAL record, the walsender terminates the transmission of that entire transaction and discards the data.
The following examples illustrate this behavior using a cascaded setup (node 1 $\rightarrow$ node 2 $\rightarrow$ node 3).
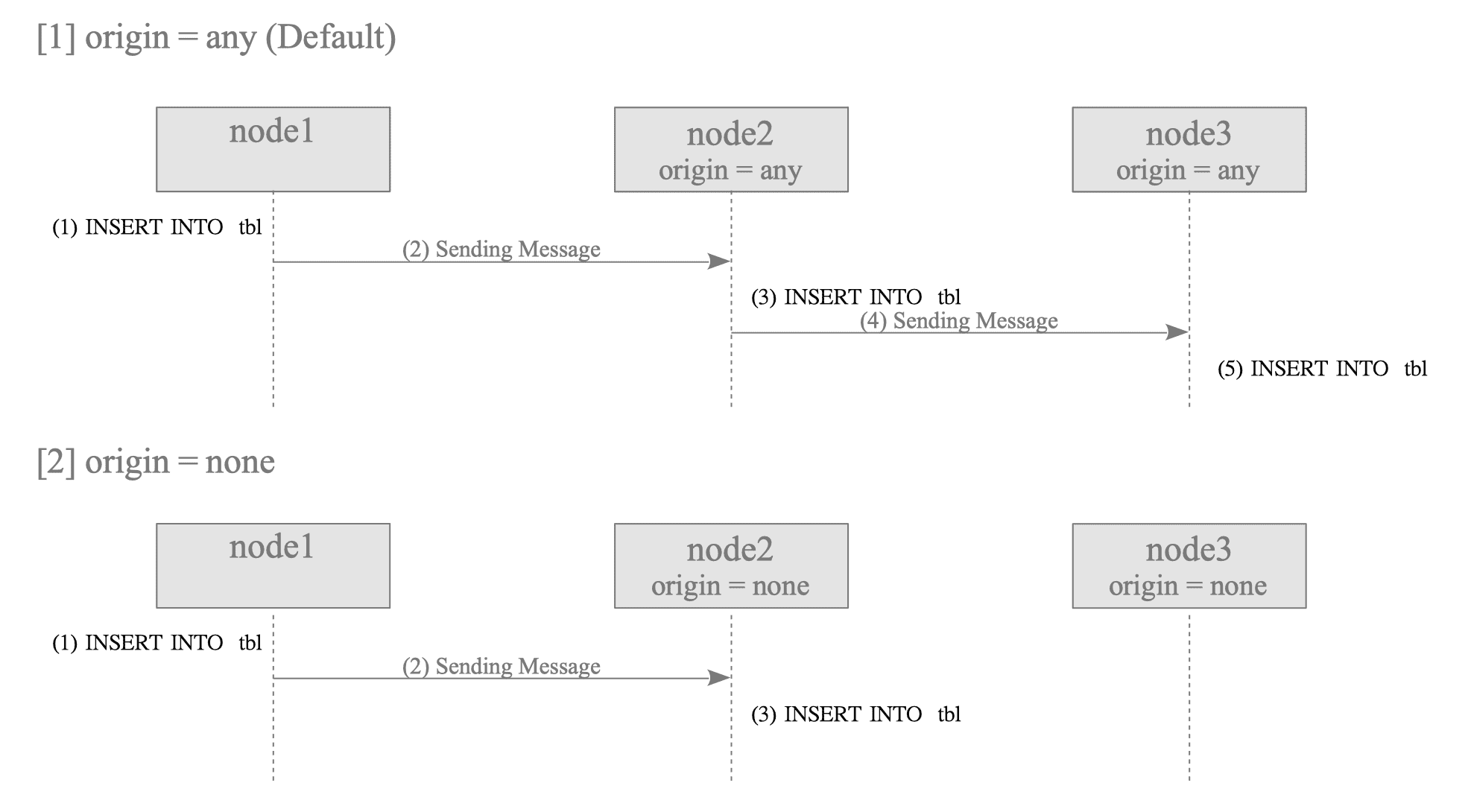
Figure 12.8. Data propagation behavior based on the origin setting.
[1] Case: origin = any (Propagation across all nodes)
- node 1: Executes an INSERT. Since no origin information exists in the COMMIT, the walsender sends the data to node 2.
- node 2: The apply worker applies the received data and records origin_id = 1 in the COMMIT WAL record. Because origin = any, the walsender sends this origin-stamped data to node 3.
- node 3: The apply worker receives data from node 2. Despite the presence of an origin_id, the worker applies the change because origin = any, subsequently recording origin_id = 1 in its own WAL.
[2] Case: origin = none (Termination at the intermediate node)
- Nnode 1: Executes an INSERT. The data is sent to node 2 as no origin is present.
- node 2: The apply worker applies the change and records origin_id = 1 in the WAL. When the walsender identifies the origin_id in the COMMIT WAL record via the ReorderBuffer, it terminates to send the message to node 3.
- node 3: No data is received because the walsender on node 2 filters out the transaction.
As shown above, an active-active configuration can be achieved while preventing infinite replication loops by setting origin = none in the subscription settings on all participating nodes.
12.1.5. Replication Slot
Compared to streaming replication, logical replication slots include five additional attributes. The following three are essential for the discussions in later sections:
- plugin: The name of the output plugin used for logical decoding (e.g., pgoutput).
- database: The name of the database to which the replication slot is attached. While physical replication slots are instance-wide, logical replication slots are scoped strictly to a single database.
- confirmed_flush_lsn: The Log Sequence Number (LSN) up to which the apply worker of the subscriber has confirmed the receipt of data. Transactions committed prior to this LSN are no longer retained for the subscriber and become eligible for removal by the publisher. See Section 12.8 for details.
Note that while logical slots also include attributes such as catalog_xmin and two_phase, their descriptions are omitted in this document. Refer to the official documentation for details.
12.1.6. Conflicts
Unlike physical streaming replication, logical replication does not replicate DDL operations and is not affected by VACUUM processes on the publisher. Consequently, the types of conflicts of streaming replication do not occur.
However, conflicts can arise primarily due to concurrent data modifications at the application level on the subscriber side. For example, if a row is deleted directly on the subscriber and the publisher subsequently attempts to update that same row, a “update_missing” conflict occurs.
A comprehensive list of conflicts detected by PostgreSQL is available in the official documentation: Logical Replication: Conflicts.
-
In the COMMIT (or ABORT) WAL record, the origin_id is included in the header portion, while the origin_commit_lsn (or origin_abort_lsn) and origin_commit_timestamp (or origin_abort_timestamp) are added to the extended section. ↩︎