12.7. Apply Worker and Transaction Replay
Alpha Version: Work in progress.
The apply worker is the core component responsible for replaying logical changes received from the publisher onto the subscriber’s local tables.
This section first reviews the fundamental operation of the apply worker, followed by an analysis of advanced modes involving the incremental processing of large transactions and the coordinated use of parallel apply workers.
12.7.1. Process Overview (streaming = off)
The apply worker on the subscriber node performs the following primary tasks:
- Origin Filtering:
Inspects the origin metadata of the incoming message to determine whether the transaction should be replayed or skipped to prevent loops. - LSN Skip Check (Idempotency):
Compares the incoming transaction’s LSN with the remote_lsn persisted in the pg_replication_origin_status view. If the transaction has already been applied, it is skipped to ensure data consistency. - Dispatch:
Routes messages to their respective handlers based on the message type, such as INSERT, UPDATE, or DELETE. - Conflict Detection:
Identifies operational conflicts, such as attempting to update a missing tuple. By default, the worker reports these conflicts and halts replication to prevent divergence.
12.7.1.1. Origin Filtering and LSN Tracking
As discussed in Section 12.1.4, the decision to apply a transaction depends on the origin parameter and the presence of an origin_id.
In current implementations, if origin = none is configured and the origin_id is greater than zero, the apply worker aborts the replay; otherwise, it proceeds.
12.7.1.2. Message Dispatching and Replay Flow
Upon receiving a stream of logical decoding messages, the apply worker processes them sequentially based on their type. Consider a scenario where a single tuple is inserted into tbl_a on the publisher:
Message Stream Sample:
[B] lsn=0/1CA96C0 ts=2026-03-29T16:55:05 txid=845
[R] oid=16456 "public"."tbl_a" 'd' 3cols [id:int4(key)][name:text][data:int4]
[I] oid=16456 N [t"3"][t"Candy"][t"3"]
[C] flags=0 commit=0/1CA9E00 end=0/1CA9F00 ts=2026-03-29T16:55:15The processing flow for this INSERT transaction is as follows:
- [B] Begin Message: The apply worker initiates a local transaction and captures the publisher’s commit LSN and timestamp. It sets the session_replication_role to replica, ensuring that local triggers and constraints are handled according to their defined replication roles.
- [R] Relation Message: The apply worker receives the table definition. It updates the RelationSyncCache, mapping the publisher-side OID (e.g., 16456) to the local table’s OID based on the schema and table name.
- [I] Insert Message: The binary tuple data is converted into the local table format. The apply worker executes an internal insert (via ExecSimpleRelationInsert), which also updates any associated indexes. This operation generates its own WAL records on the subscriber.
- [C] Commit Message: The local transaction is committed.
The apply worker appends the
origin_idcorresponding to the publisher to the commit WAL record. It then updates pg_replication_origin to store the latest applied LSN and sends an acknowledgment (ACK) to the walsender, confirming that the data has been flushed to disk.
While INSERT is used as the primary example here, other DML operations such as UPDATE and DELETE follow a similar dispatch logic.
The commit WAL record contains appended metadata from the source publisher: specifically, the origin_id, the final_lsn as the origin_lsn, and the commit_timestamp as the origin_timestamp.
As mentioned in Section 12.4.3, UPDATE and DELETE operations involve an additional step: the apply worker must execute direct tuple lookups—utilizing index or sequential scans via functions such as RelationFindReplTupleByIndex — to uniquely identify and modify the specific target data before applying the change.
12.7.1.3. Optimization for REPLICA IDENTITY FULL
Version 15 or earlier, tables configured with REPLICA IDENTITY FULL necessitated a sequential scan to identify the target tuple for UPDATE or DELETE operations, leading to significant performance overhead on large tables.
From version 16 onwards, the apply worker can leverage existing indexes to locate tuples even under REPLICA IDENTITY FULL. The function FindLogicalRepLocalIndex() identifies suitable non-partial B-tree indexes that can uniquely identify the row, substantially reducing the reliance on costly sequential scans.
12.7.2. Streaming Mode (streaming = on)
When the streaming parameter is set to ‘on’, the apply worker can receive in-progress transactions from the publisher in multiple segments before the final commit.
Consider a scenario involving two concurrent transactions: txid 842, a large transaction sent across two streamed segments, and txid 843, a smaller transaction sent as a standard block-based message.
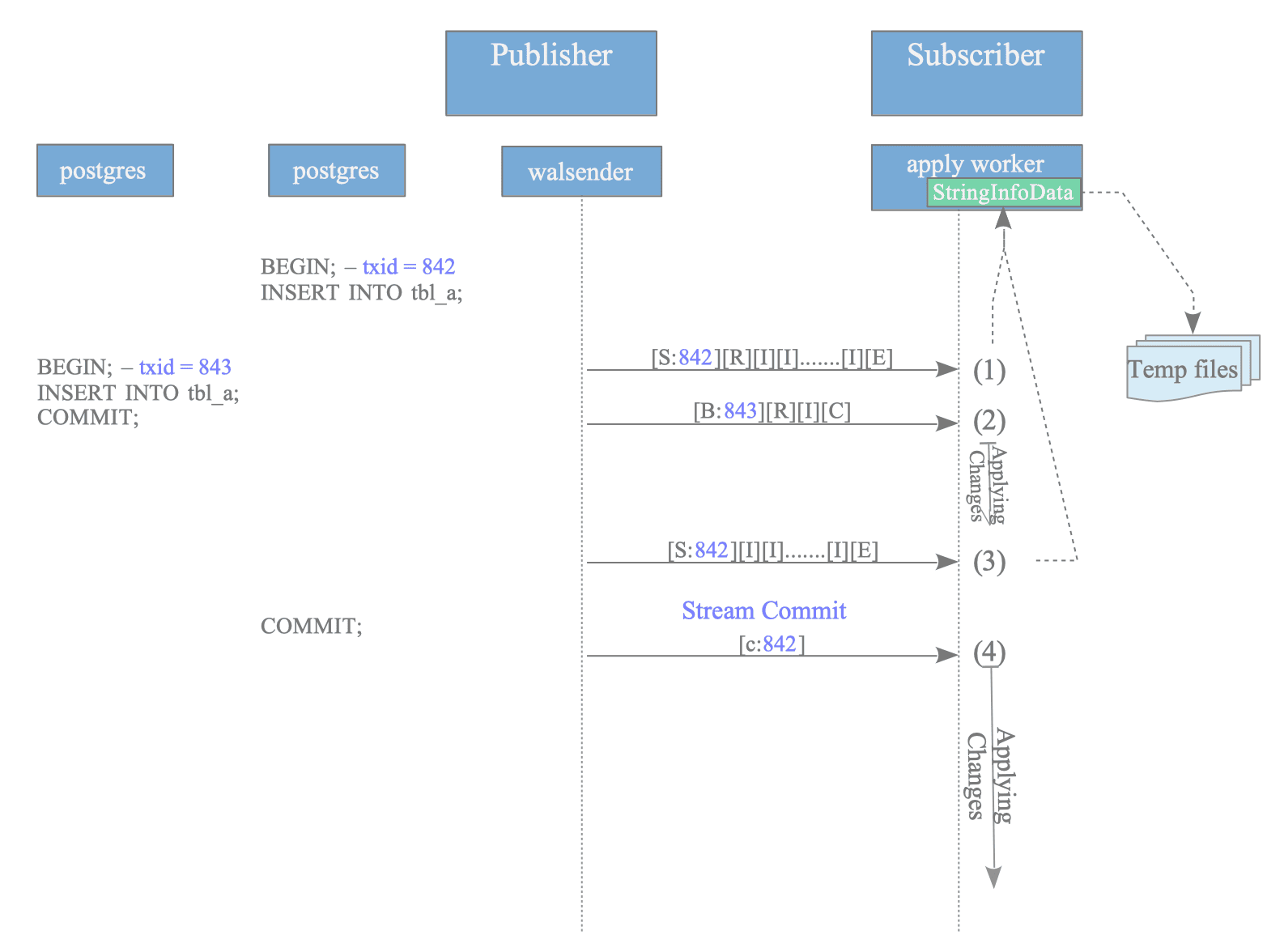
Figure 12.28. Replay process of logical changes when streaming is 'on'.
The processing sequence illustrated in Figure 12.28 is as follows:
- First Segment of txid 842: The apply worker receives the initial stream segment and accumulates the changes in memory using a StringInfoData structure (internally, the original_msg buffer).
- Message for txid 843: A standard non-streamed block for txid 843 arrives. The apply worker immediately decodes and applies these changes to the local table.
- Second Segment of txid 842: The subsequent stream segment for txid 842 arrives and is appended to the existing buffer in memory.
- Commit of txid 842: Upon receiving the Stream Commit message, the apply worker decodes all accumulated changes for txid 842 and replays them sequentially.
In summary, the apply worker processes standard messages immediately while storing streamed segments in a buffer until the commit message triggers the replay of the entire transaction.
12.7.2.1. Memory Pressure and Spilling to Disk
The memory allocated for buffering streamed changes is governed by the logical_decoding_work_mem parameter. If the volume of accumulated changes exceeds this limit, the apply worker spills the data to temporary files.
These temporary files are located in the $PGDATA/base/pgsql_tmp/ directory. The naming conventions are structured as follows:
- Directory Format:
base/pgsql_tmp/pgsql_tmp[PID].[FilesetSerial].fileset/ - File Format:
[SubID]-[txid].changes.[SegmentID]
If a subscription with OID 16403 processes a streamed transaction with txid 767 using an apply worker with PID 2212, the file path is as follows:
base/pgsql_tmp/pgsql_tmp2212.0.fileset/16403-767.changes.0Once the transaction is committed or aborted, these temporary files are automatically removed.
12.7.3. Parallel Apply Worker Mode (streaming = parallel)
Introduced in version 16, parallel apply enhances logical replication performance by allowing multiple transactions to be replayed concurrently on the subscriber. Unlike the standard streaming = ‘on’ mode, which buffers streamed changes until a commit arrives, parallel apply enables assigned workers to begin replaying changes immediately as they are received.
The architecture and constraints of this mode are summarized below:
- Leader Apply Worker: Maintains the connection with the walsender and handles the application of standard (non-streamed) transactions directly, while acting as a dispatcher for streamed transaction segments.
- Parallel Apply Workers: Launched by the leader apply worker to handle specific large (streamed) transactions.
- Worker Limit: The number of concurrent parallel apply workers is governed by the max_parallel_apply_workers_per_subscription parameter.
- Fallback Mechanism: If the number of active streamed transactions exceeds the configured limit, the leader apply worker handles additional large transactions by falling back to the streaming = ‘on’ behavior (buffering to memory or disk).
12.7.3.1. Replay Sequence in Parallel Mode
Consider two transactions: txid 845, a large transaction sent in two segments, and txid 846, a single-tuple transaction.
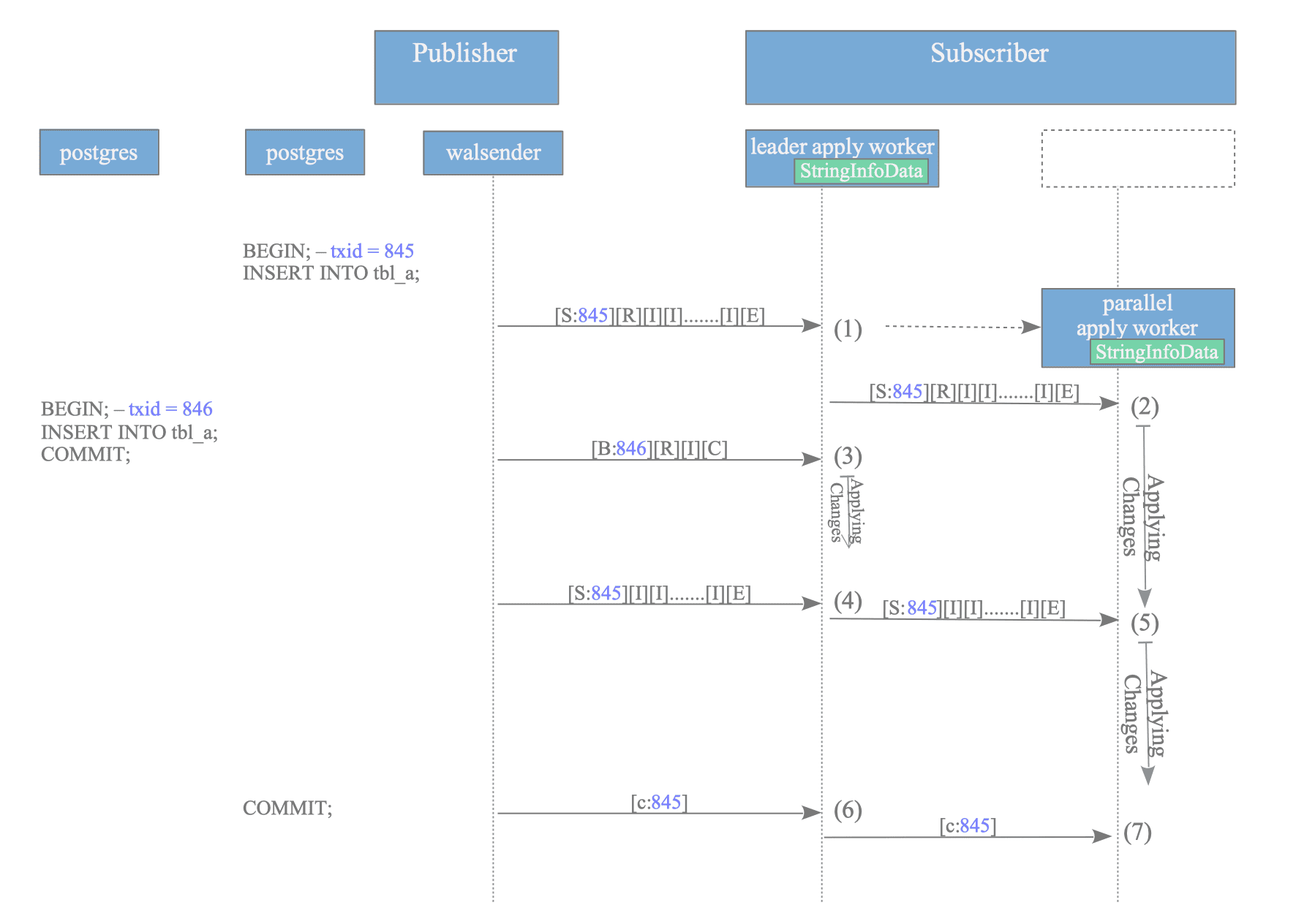
Figure 12.29. Transaction replay sequence in parallel apply mode.
As illustrated in Figure 12.29, the processing flow occurs as follows:
- Arrival of txid 845 (First Segment): The leader apply worker identifies this as a streamed transaction and launches (or assigns) a parallel apply worker.
- Immediate Replay: The leader apply worker dispatches the first segment to the parallel apply worker, which immediately starts replaying the changes to the local table.
- Arrival of txid 846 (Block Message): While txid 845 is being processed by the parallel apply worker, a standard block-based message for txid 846 arrives. The leader apply worker processes and applies this change directly.
- Arrival of txid 845 (Second Segment): The leader apply worker receives the subsequent segment and forwards it to the already assigned parallel apply worker.
- Continued Replay: The parallel apply worker applies the second segment without waiting for the final commit.
- Stream Commit: The leader apply worker receives the commit message for txid 845 and notifies the parallel apply worker.
- Finalization: The parallel apply worker commits the local transaction and returns to a ready state.
The leader apply worker dynamically manages the distribution of changes. While parallel apply workers handle assigned streamed transactions, the leader apply worker remains responsible for replaying non-streamed transactions and managing the walsender communication.
The task distribution logic within the leader apply worker follows a structured decision-making process based on the message type and available system resources:
- For block-based messages: The leader apply worker executes an immediate replay of the change.
- For stream segments:
- If a parallel apply worker is already assigned to the transaction, the leader apply worker forwards the segment to that worker for immediate replay.
- If no worker is currently assigned and the number of active parallel apply workers is below the configured max_parallel_apply_workers_per_subscription threshold, the leader apply worker launches a new worker and delegates the transaction to it.
- Fallback Mechanism: If the parallel apply worker limit has been reached, the leader apply worker reverts to the streaming = ‘on’ protocol. In this case, the leader apply worker accumulates the incoming segments in memory or on disk until the transaction is ready to be replayed upon the arrival of the commit message.