11.2. RNN Based Language Model Architectures

While RNNs introduced in the 1980s, they were not widely used for NLP tasks until the early 2010s.
However, RNNs have rapidly replaced n-gram models as the dominant approach in NLP research since the publication of the paper “Neural Machine Translation by Jointly Learning to Align and Translate” in 20141.
Following the classification of “Speech and Language Processing”, this document presents four key RNN-based architectures for NLP:
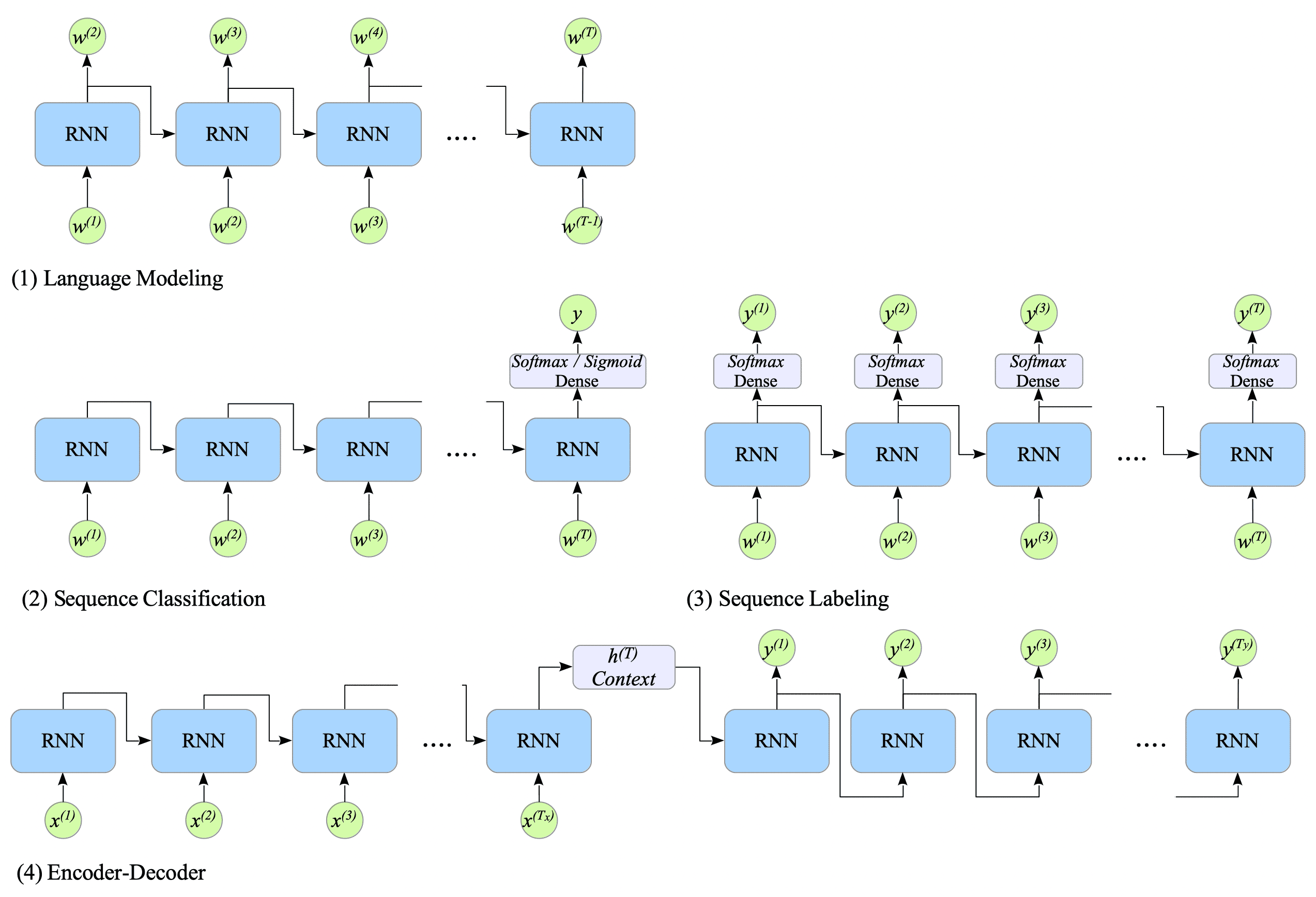
Fig.11-1: Four RNN-Based Architectures for NLP Tasks
(1) Language Modeling
This architecture predicts the next word $w_{t+1}$ in a sentence given the current word $w_{t}$. While similar to bigrams, RNNs process sentences recursively, overcoming the limitations of n-grams’ local dependencies. (See Section 13.3 for details.)
(2) Sequence Classification
A Many-to-One RNN can be used for tasks like sentiment analysis, where the goal is to classify an entire sequence. (See Chapter 12 for details.)
(3) Sequence Labeling
A Many-to-Many RNN can be used for tasks like Part-of-Speech (POS) tagging, where a label is assigned to each element in a sequence.
(4) Encoder-Decoder
This architecture is typically used for language translation. (See Chapter 13 for details.)
-
While RNN-based language models achieved significant success, their dominance in the field suddenly terminated in 2017 with the introduction of the Transformer model. ↩︎