17.2. Positional Encoding
Since its introduction in the original Transformer paper, various positional encoding techniques have been proposed. The following survey paper comprehensively analyzes research on positional encoding published before mid-2022:
- Position Information in Transformers: An Overview (1.Sep.2022)
This section leverages the single-head attention weight to compare different positional encoding variations.
The original Transformer’s attention weight, explicitly incorporating positional encoding but omitting the scaling factor, is shown below:
$$ \begin{cases} q_{i} = (x_{i} + p_{i})W^{Q} \\ k_{j} = (x_{j} + p_{j})W^{K} \\ v_{j} = (x_{j} + p_{j})W^{V} \end{cases} $$ $$ \text{softmax}(q_{i} k^{T}_{j}) = \text{softmax}( ((x_{i} + p_{i})W^{Q}) ((x_{j} + p_{j})W^{K})^{T} ) \tag{17.1} $$where:
- $d_{model}$ is the word embedding dimension.
- $ x_{i} \in \mathbb{R}^{1 \times d_{model}} $ is the $i$-th row of the input matrix. (representing the $i$-th token’s embedding.)
- $ p_{i} \in \mathbb{R}^{1 \times d_{model}} $ is the $i$-th position of the sinusoidal positional encoding, defined by the expression $(15.1)$ in Section 15.1.
- $ W^{Q}, W^{K}, W^{V} \in \mathbb{R}^{d_{model} \times d_{model}} $ are the query,key and value weight matrices, respectively.
Despite being one of the earliest approaches, the original Transformer’s sinusoidal positional encoding remains surprisingly competitive against many later variations.
The following subsections will outline major variations of positional encoding.
- Fourier Position Embedding: Enhancing Attention’s Periodic Extension for Length Generalization (v1: 23.Dec.2024, v2: 2.Jan.2025)
17.2.1. Relative Positional Encoding
In 2018, Shaw and two co-authors of the Transformer paper introduced a relative positional encoding as follows:
$$ \begin{cases} q_{i} = x_{i} W^{Q} \\ k_{j} = x_{j} W^{K} + a^{K}_{j-i} \\ v_{j} = x_{j} W^{V} + a^{V}_{j-i} \end{cases} $$ $$ \text{softmax}( (x_{i} W^{Q}) (x_{j} W^{K} + a^{K}_{j-i})^{T} ) \tag{17.2} $$where $a_{j-i}^{K}, a_{j-i}^{V} \in \mathbb{R}^{1 \times d_{model} }$ are learnable parameters that can be viewed as the embedding of the relative position $j - i$ in key and value layers, respectively.
For a more detailed explanation of relative positional encoding, you can refer to the video: “Stanford XCS224U: NLU I Contextual Word Representations, Part 3: Positional Encoding I Spring 2023”
The authors reported a slight increase in BLEU score1 when using their relative positional encoding.

T5, introduced by Raffel et al. in 2019, offers a simplified version of relative positional encoding:
$$ \begin{cases} q_{i} = x_{i} W^{Q} \\ k_{j} = x_{j} W^{K} \\ v_{j} = x_{j} W^{V} \end{cases} $$ $$ \text{softmax} ( (x_{i} W^{Q}) (x_{j} W^{K})^{T} + b_{j-i} ) \tag{17.3} $$For each $ j - i$, $b_{j-i}$ is a learnable bias.
While relative positional encoding shows promise in specific areas like music (as demonstrated by Music Transformer), it does not consistently outperform absolute encoding across all domains. As a result, research continues to explore and improve both approaches.
- Self-Attention with Relative Position Representations (v1: 6.Mar.2018, v2: 12.Apr.2018)
- T5 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (v1: 23.Oct.2019, v4: 19.Sep.2023)
17.2.2. RoPE (Rotary Position Embedding)
RoPE, introduced by Su et al. in 2021, offers a unique approach to positional encoding by combining absolute position encoding with a rotation matrix. This effectively captures both the absolute and relative positional relationships between tokens.
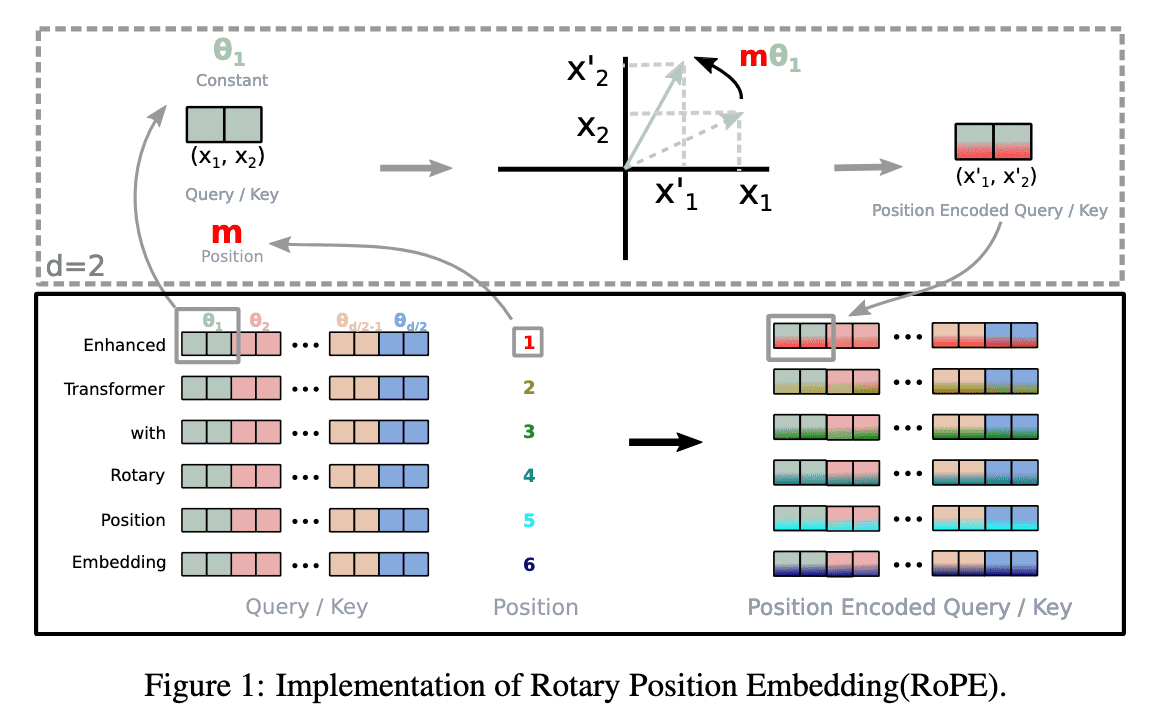
Here is the attention weight of RoPE:
$$ \begin{cases} q_{i} = (R^{d}_{\Theta, i} W^{Q} x_{i}) \\ k_{j} = (R^{d}_{\Theta, i} W^{K} x_{j}) \\ v_{j} = (R^{d}_{\Theta, i} W^{V} x_{j}) \end{cases} $$ $$ \text{softmax} ( (R^{d}_{\Theta, i} W^{Q} x_{i})^{T} (R^{d}_{\Theta, j} W^{K} x_{j}) ) \tag{17.3} $$where
$$ R^{d}_{\Theta,m} = \begin{pmatrix} \cos( m \theta_{1}) & - \sin(m \theta_{1}) & 0 & 0 & \ldots & 0 & 0 \\ \sin( m \theta_{1}) & \cos( m \theta_{1}) & 0 & 0 & \ldots & 0 & 0 \\ 0 & 0 & \cos( m \theta_{2}) & - \sin( m \theta_{2}) & \ldots & 0 & 0 \\ 0 & 0 & \sin( m \theta_{2}) & \cos( m \theta_{2}) & \ldots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \ldots & \cos( m \theta_{d/2}) & - \sin( m \theta_{d/2}) \\ 0 & 0 & 0 & 0 & \ldots & \sin( m \theta_{d/2}) & \cos( m \theta_{d/2}) \\ \end{pmatrix} $$The authors reported that RoPE achieves similar performance to learned absolute position embeddings, particularly showing advantages for long sequences.
RoPE is adopted by GPT-NeoX-20B and PaLM.
- RoPE RoFormer: Enhanced Transformer with Rotary Position Embedding (v1: 20.Apr.2021, v5: 8.Nov.2023)
This video: “Rotary Positional Embeddings: Combining Absolute and Relative” concisely summarizes the pros and cons of both absolute and relative positional encoding, and provides a clear explanation of rotary position embedding:

17.2.3. ALiBi (Attention with Linear Biases)
Introduced in 2021 by Press et al., ALiBi (Attention with Linear Biases) is the simplest positional encoding method proposed so far, even compared to the original Transformer’s approach.
The ALiBi paper’s abstract concisely explains its key idea:
ALiBi does not add positional embeddings to word embeddings; instead, it biases query-key attention scores with a penalty that is proportional to their distance.
The attention weight calculation in ALiBi is shown below, quoted from the paper:
$$ \text{softmax}(q_{i} K^{T} + m \cdot [-(i-1), \ldots, -2, -1, 0]) \tag{17.4} $$For an input subsequence of length $L$, the attention sublayer computes the attention scores for the ith query $q_{i} \in \mathbb{R}^{1 \times d}, (1 \le i \le L)$ in each head, given the first $i$ keys $ K \in \mathbb{R}^{i \times d} $, where $d$ is the head dimension:
where $m$ is a head-specific slope fixed before training.
The figure below, cited from the paper, illustrates this concept.

The authors claim that ALiBi offers several advantages over other methods, including faster training and inference with lower memory consumption, as well as the ability to handle long sequences effectively, evidenced by low perplexity2. See the following figures in the cited paper for further details on these advantages.
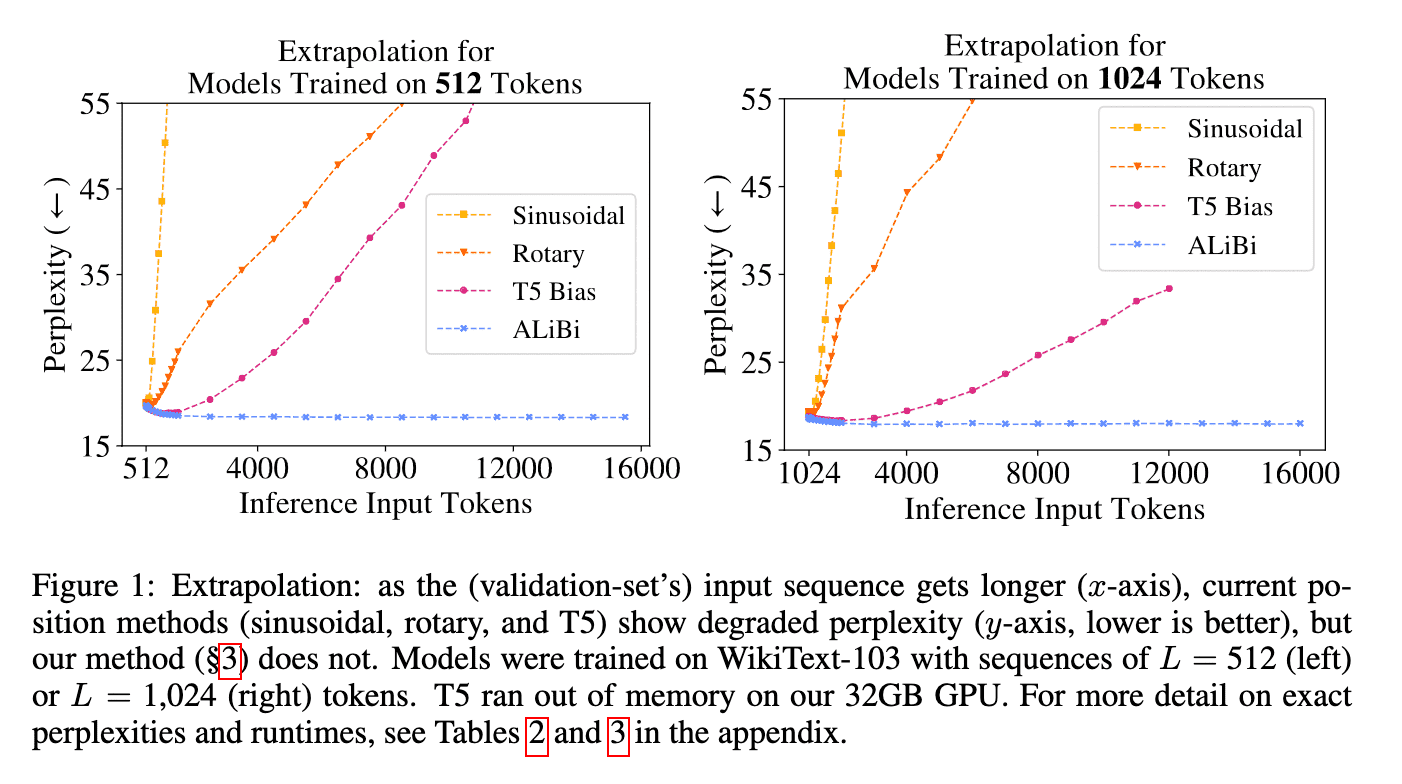

ALiBi is adopted by MPT, Falcon and JINA.
- ALiBi Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation (v1: 27.Aug.2021, v2: 22.Apr.2022)