Part 2: Recurrent Neural Networks
Recurrent neural networks (RNNs) were invented to handle time series data. In the AI field, time series data includes both numerical sequences, such as stock prices and temperatures, and natural language sequences, such as sentences where each word is connected to the others.
Type of RNNs
There are four main types of RNNs, each with different input and output structures:
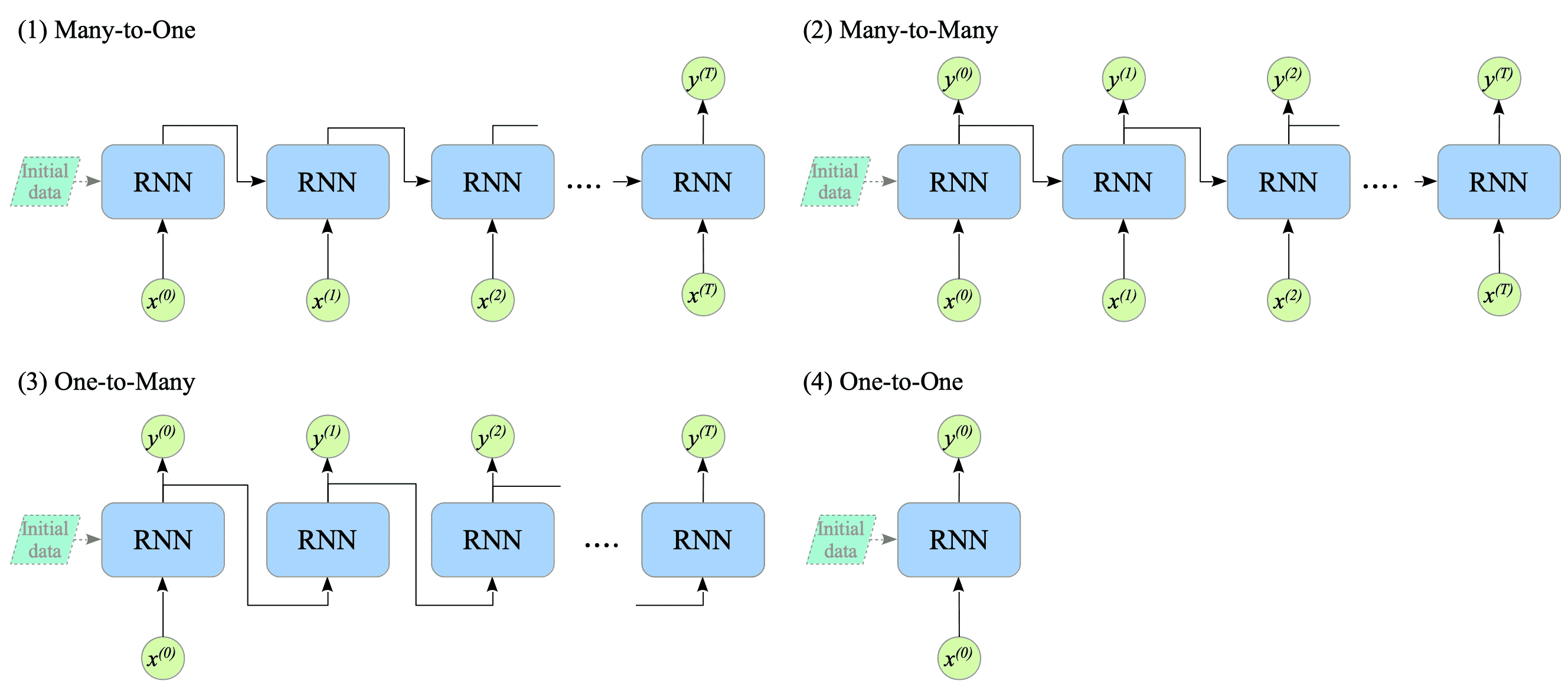
(1) Many-to-One
A many-to-one RNN takes multiple input sequences and outputs a single result.
Examples include sentiment analysis and the encoder in machine translation.
(2) Many-to-Many
A many-to-many RNN takes multiple input sequences and and generates multiple output sequences.
Examples include part-of-speech (POS) tagging and language models, which are explained in Section 11.3.
(3) One-to-Many
This type takes a single input and produces multiple output sequences.
Examples include tasks like image captioning, music generation, and code generation.
(4) One-to-One
This type closely resembles a feedforward neural network, processing a single input and producing a single output.
Variations of RNNs
There are three variations of RNN model: simple RNN, LSTM (Long Short-Term Memory), and GRU (Gated Recurrent Unit).
-
The simple RNN architecture
Proposed in the early 1980s by John Hopfield and David Rumelhart. This architecture suffers from the vanishing and exploding gradient problem, limiting its ability to learn long-term dependencies. -
LSTM (Long Short-Term Memory)
Proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber. LSTM networks was designed to overcome the limitations of the simple RNN by addressing the vanishing and exploding gradient problems. -
GRU (Gated Recurrent Unit)
Proposed in 2014 by Kyunghyun Cho, Bahdanau, Chorowski, and Bengio. GRU is a simplified version of LSTM that is often easier to train and has fewer parameters.