1. Perceptron

According to Wikipedia, a perceptron is a supervised learning algorithm designed for binary classification tasks. In this document, the term “perceptron” refers to a neural network that has only input and output layers.
A typical example of perceptron is implementing logic gates like AND or OR. To create an AND-gate perceptron, we repeatedly feed it pairs of inputs and their corresponding the ground-truth labels (correct outputs):
# Inputs
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
# The ground-truth labels
Y = np.array([[0], [0], [0], [1]])This process of providing inputs and labels is known as training. During training, the perceptron iteratively adjusts its internal parameters (weights and bias) to eventually learn to generate the correct output for a given input.
0 AND 0 => 0
0 AND 1 => 0
1 AND 0 => 0
1 AND 1 => 1The following sections will provide a brief explanation of perceptron mechanics. Although the perceptron is historically important, it is also used in education today.
1.1. Formulation of Perceptron
The simplest form of a perceptron, equipped with two inputs and a single output, is defined as follows:
$$ \begin{cases} \hat{y} = W^{T} x + b = (W_{0} \quad W_{1}) \begin{pmatrix} x_{0} \\ x_{1} \end{pmatrix} + b \\ y = f(\hat{y}) \end{cases} $$where:
- $ x \in \mathbb{R}^{2}$ is the input vector.
- $ W \in \mathbb{R}^{2} $ is the weight vector.
- $ b \in \mathbb{R} $ is the bias term.
- $ y \in \lbrace 0, 1 \rbrace $ is the output of the perceptron.
- $ f(\cdot) $ is an activation function shown below:
Fig.1-1 illustrates this perceptron’s structure:
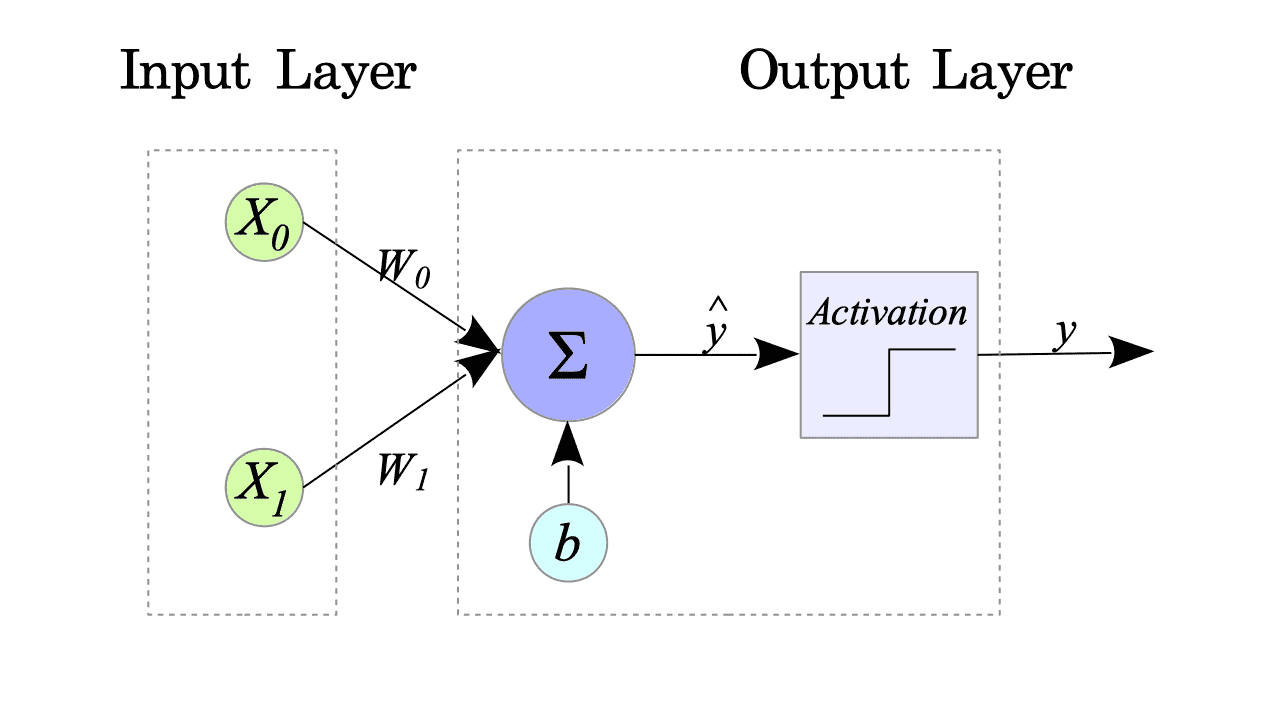
Fig.1-1: Simple Perceptron
This perceptron has three parameters: $ W_{0}, W_{1} $ and $b$, so, our goal is to determine these parameters by training.
The next section will demonstrate how to train a perceptron using a specific implementation.
1.2. Implementing AND-gate
Complete Python code is available at: AND-gate.py
[1] Import modules.
import numpy as np
import matplotlib.pyplot as plt[2] Define activation function.
def activate_func(x):
return 1 if x > 0 else 0[3] Prepare the inputs and the the ground-truth labels.
- $X$ is the set of inputs consisting of all possible combinations of 0’s and 1’s in two dimensions.
- $Y$ is the set of the ground-truth labels associated with the inputs.
# Input: the training data
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
# The ground-truth labels for the training data.
Y = np.array([[0], [0], [0], [1]])
OPERATION = "AND"[4] Initialize weights and bias.
Initialize the weight vector $ W $ and the bias term $b$ by random numbers.
W = np.random.uniform(size=(2))
b = np.random.uniform(size=(1))[5] Training.
In the training phase, this perceptron adjusts the weights and the bias until the output matches the label data.
n_epochs = 150 # Epoch
lr = 0.01 # Learning rate
#
# Training loop
#
for epoch in range(1, n_epochs + 1):
for i in range(0, len(Y)):
# Forward Propagation
x0 = X[i][0]
x1 = X[i][1]
y_h = W[0] * x0 + W[1] * x1 + b[0]
y = activate_func(y_h)
# Updating Weights and Biases
W[0] -= lr * (y - Y[i]) * x0
W[1] -= lr * (y - Y[i]) * x1
b[0] -= lr * (y - Y[i])$\text{n_epochs}$ and $\text{lr}$ (learning rate) are hyper-parameters, so we should determine them before training. For this example, we chose 150 and 0.01, respectively.
[6] Test
Run the following command to test the perceptron:
$ python AND-gate.py
epoch: 1 / 150 Loss = 1.500000
epoch: 10 / 150 Loss = 1.500000
epoch: 20 / 150 Loss = 1.500000
epoch: 30 / 150 Loss = 1.000000
epoch: 40 / 150 Loss = 0.000000
epoch: 50 / 150 Loss = 0.000000
epoch: 60 / 150 Loss = 0.000000
epoch: 70 / 150 Loss = 0.000000
epoch: 80 / 150 Loss = 0.000000
epoch: 90 / 150 Loss = 0.000000
epoch: 100 / 150 Loss = 0.000000
epoch: 110 / 150 Loss = 0.000000
epoch: 120 / 150 Loss = 0.000000
epoch: 130 / 150 Loss = 0.000000
epoch: 140 / 150 Loss = 0.000000
epoch: 150 / 150 Loss = 0.000000
------------------------
x0 AND x1 => result
========================
0 AND 0 => 0
0 AND 1 => 0
1 AND 0 => 0
1 AND 1 => 1
========================Our perceptron gives us the correct answers.
1.3. Limitation of Perceptrons
Perceptrons can learn OR, NAND, and AND gates, but they cannot learn the XOR gate. This limitation arises from their inherent linear decision boundary, which restricts them to classifying data that can be separated by a straight line.
As explained in the following documentation:
There are two main approaches to overcome this limitation:
- Adding the hidden layers, i.e., using neural networks. This approach is explored in subsequent chapters.
- Using Machine Learning methods.
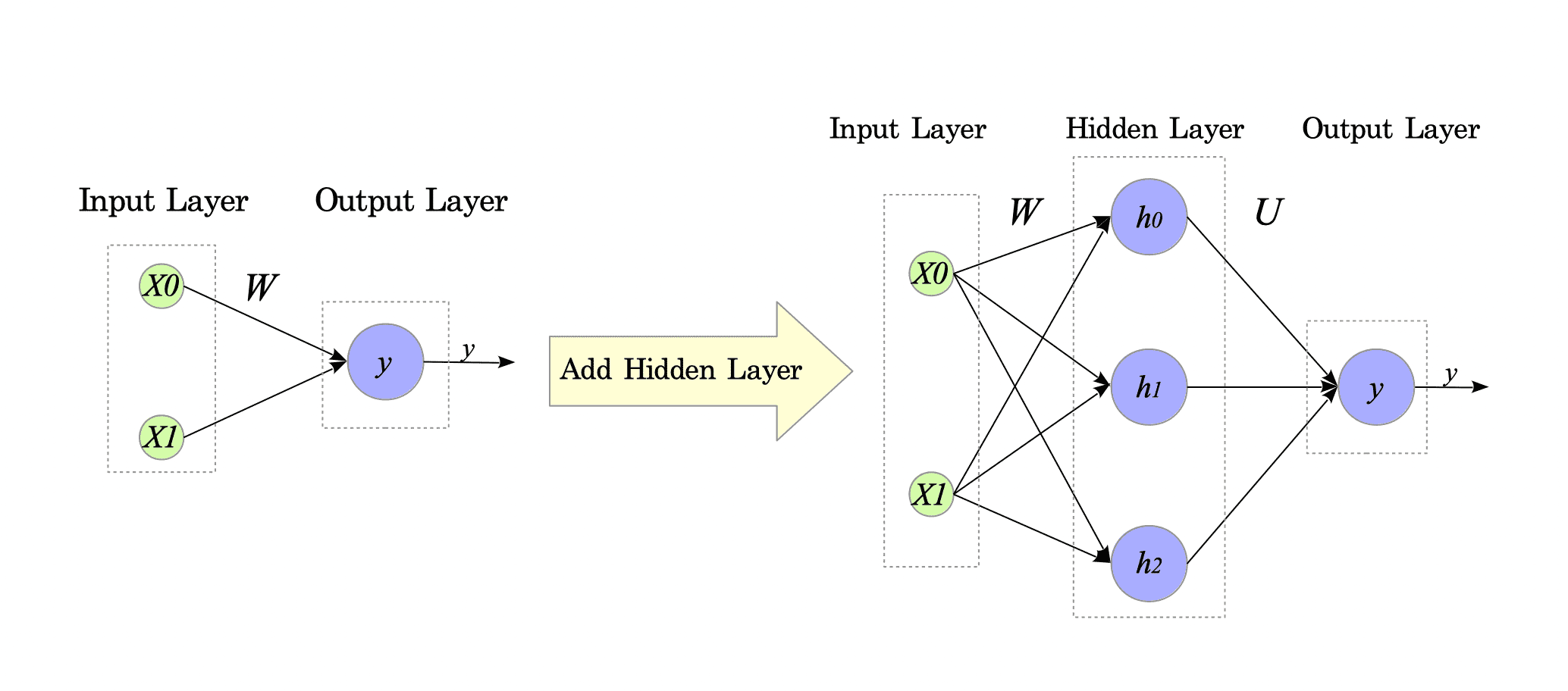
Fig.1-2: Perceptron vs. Neural Network
1.3.1. Machine Learning (ML)
Typical nonlinear classification methods in ML are SVM (Support Vector Machine) and K-Neighbors Classifier.
-
SVM (Support Vector Machine)
-
K-Neighbors Classifier
1.3.1.1. Support Vector Machine: SVM
Complete Python code is available at: SVM.py
from sklearn import svm
from sklearn.metrics import accuracy_score
# Create datasets
X = [[0, 0], [1, 0], [0, 1], [1, 1]]
Y = [0, 1, 1, 0]
# Create model
model = svm.SVC()
# Training
model.fit(X, Y)
# Test
result = model.predict(X)
print("------------------------")
print("x0 XOR x1 => result")
print("========================")
for i in range(len(X)):
_x = X[i]
print(" {} XOR {} => {}".format(_x[0], _x[1], int(result[i])))
print("========================")1.3.1.2. K-Neighbors Classifier
Complete Python code is available at: KNeighborsClassifier.py
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Create datasets
X = [[0, 0], [1, 0], [0, 1], [1, 1]]
Y = [0, 1, 1, 0]
# Create model
model = KNeighborsClassifier(n_neighbors=1)
# Training
model.fit(X, Y)
# Test
result = model.predict(X)
print("------------------------")
print("x0 XOR x1 => result")
print("========================")
for i in range(len(X)):
_x = X[i]
print(" {} XOR {} => {}".format(_x[0], _x[1], int(result[i])))
print("========================")