15. Overview

The Transformer is an encoder-decoder architecture model, designed initially for natural language translation tasks.
Fig.15-1 illustrates its architecture:
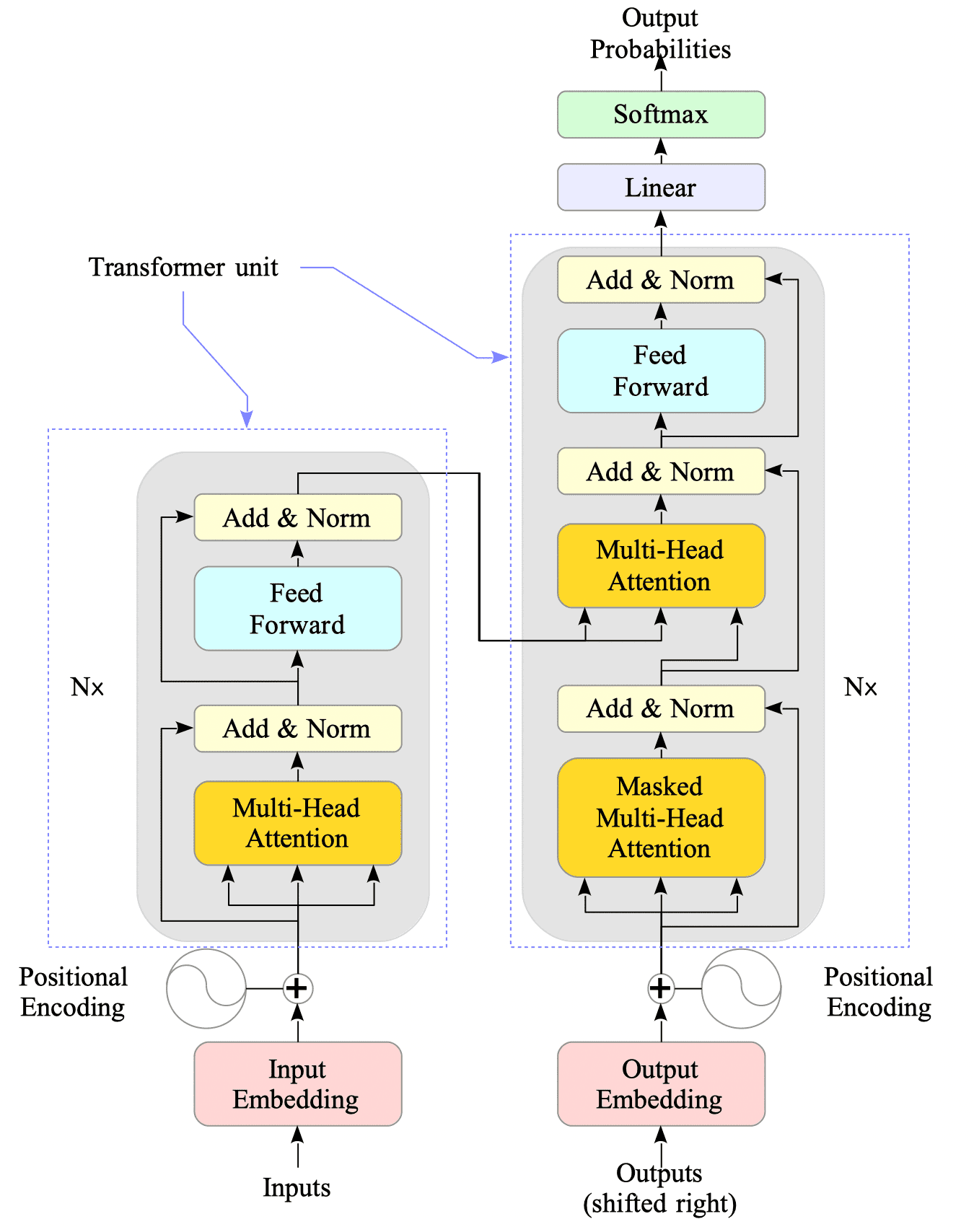
Fig.15-1: The Transformer - model architecture.
In Fig.15-1, the left and right sides represent the encoder and decoder components, respectively.
Both the encoder and decoder consist of multi-head attention layers, position-wise feed-forward networks (FFNs), and normalization layers. Additionally, the Transformer leverages a technique called positional encoding for word embedding.
A unit consisting of multi-head attention mechanisms and a feed-forward network is often referred to as a transformer unit or a transformer block.
The Transformer architecture consists of encoder and decoder modules, each built with multiple layers1.
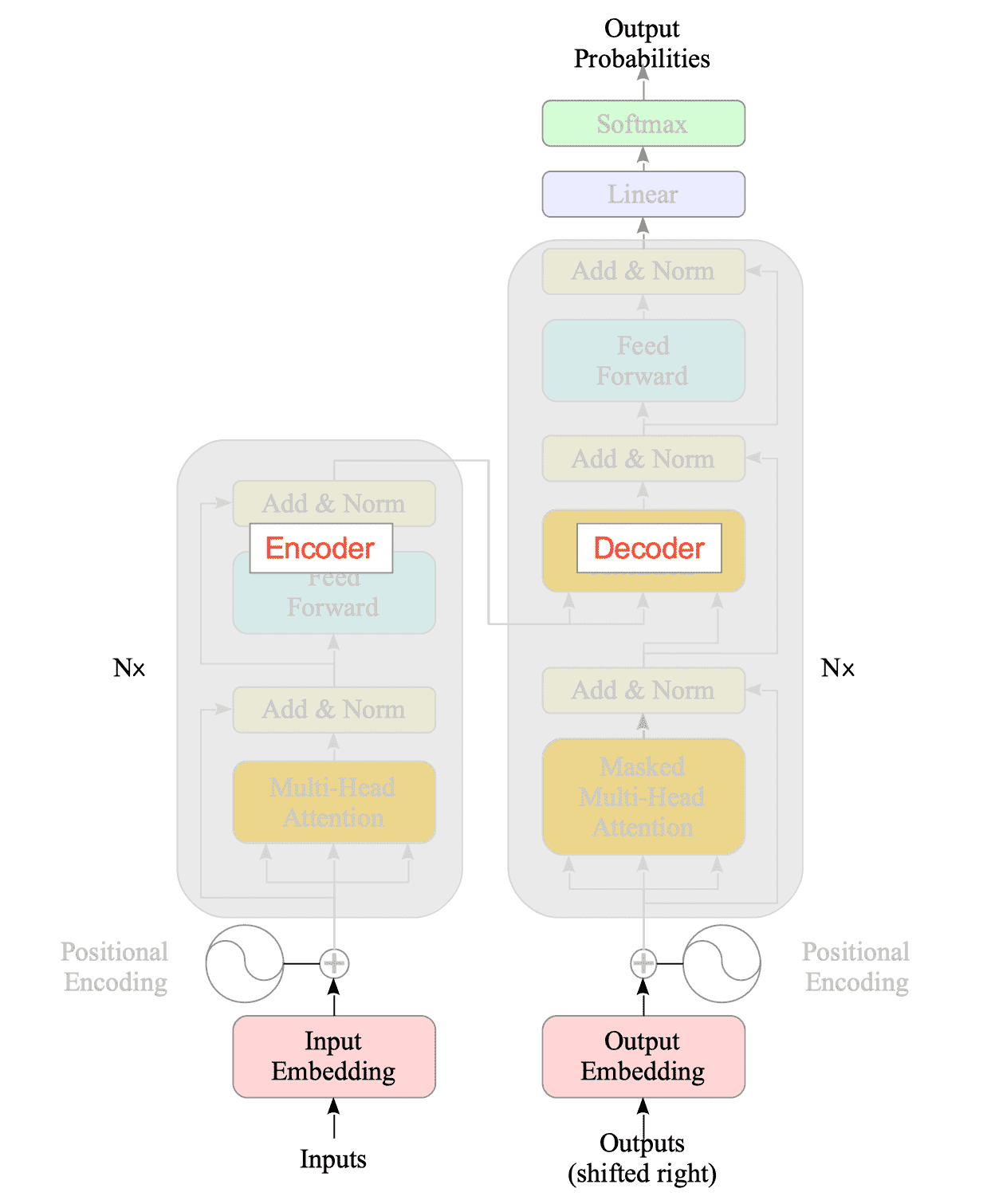
Fig.15-2: Transformer Model: Encoder and Decoder
Looking inside the encoder and decoder, you will find residual connections. These connections, explained in Section 4.4.2.4, help prevent the exploding and vanishing gradient problems that can arise when stacking multiple layers.
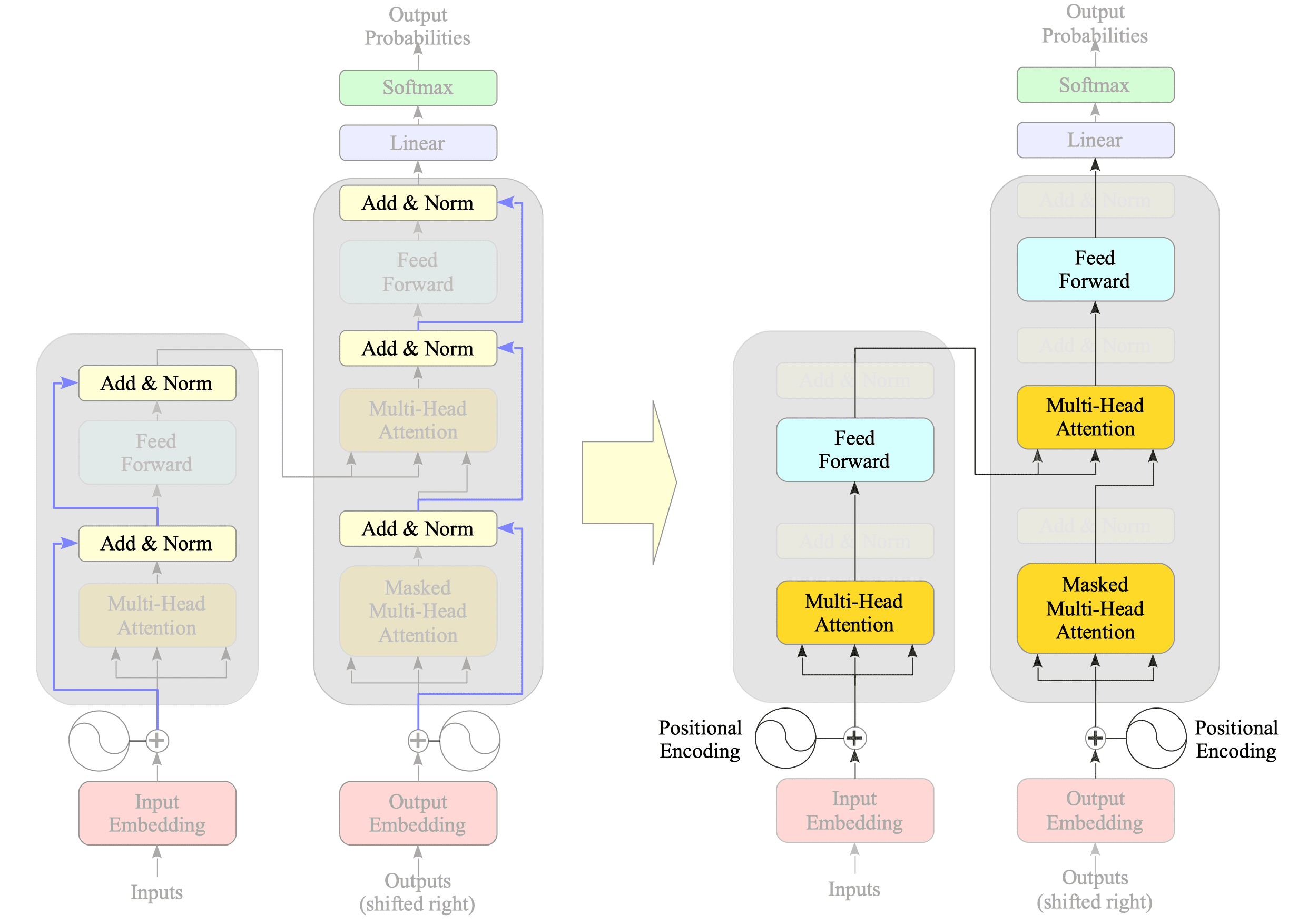
Fig.15-3: (Left) Diagram Highlighting Residual Connections. (Right) Diagram Without Residual Connections
By simplifying the diagram and removing residual connections, we can see the core structure of each layer: an encoder layer consists of a multi-head attention layer followed by a feed-forward layer, while a decoder layer has two multi-head attention layers and a feed-forward layer.
Once simplified like this, the Transformer model appears less complex than it initially feels.
The Add and Normalize layers of the residual connection, as well as the linear and Softmax layers of the decoder, are straightforward and require no further explanation here. The following sections will explore these components in detail:
15.1. Positional Encoding
15.2. Multi-Head Attention
15.3. Position-Wise Feed-Forward Network
-
The original Transformer paper utilized six encoder and six decoder layers in its model. ↩︎