7.6. Exploding and Vanishing Gradients Problems
Simple RNNs are susceptible to two major issues: exploding and vanishing gradients. The potential for these problems can be intuitively understood by comparing the backward computation graphs of a multi-layered neural network and a simple RNN. See Fig.7-11.
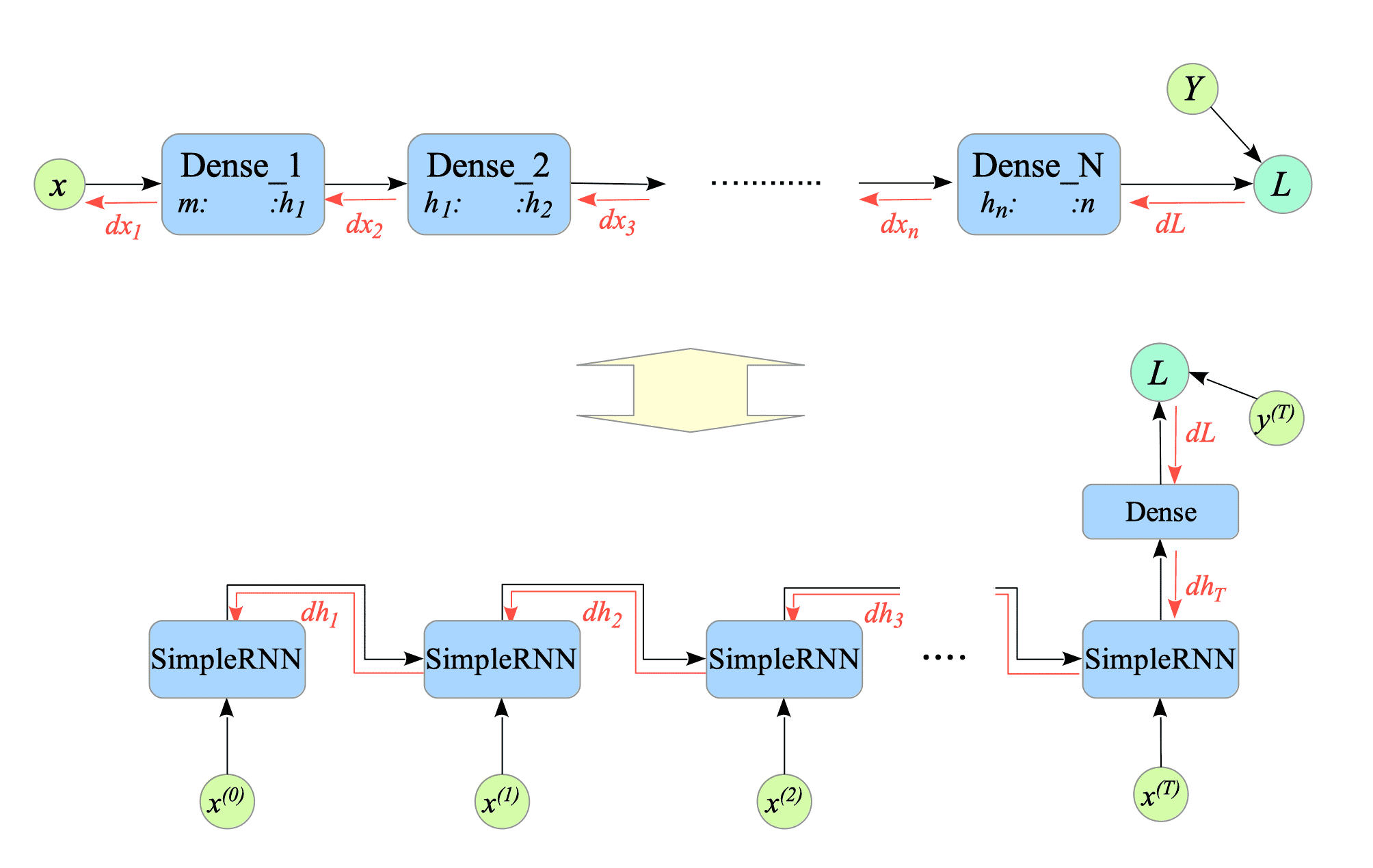
Fig.7-11: (Top) Pseudo-Computational Graph of NN with Multiple Dense Layers. (Bottom) Pseudo-Computational Graph of Simple RNN.
In a simple RNN, during backpropagation, the gradient either explodes exponentially, making learning impossible, or vanishes completely. This vanishing effect causes the initial gradient in a long sequence to have minimal impact on the final output, hindering the model’s ability to learn and predict long-term dependencies.
To address these issues, several advanced RNN architectures have been developed. Two prominent examples are Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU). We will explore them in the following chapters.