16.3. Translation
During translation, the Transformer predicts the target sentence one token at a time, similar to RNN-based encoder-decoder models.
def evaluate(sentence, transformer, source_lang_tokenizer, target_lang_tokenizer):
sentence = lth.preprocess_sentence(sentence)
sentence = source_lang_tokenizer.tokenize(sentence)
encoder_input = tf.expand_dims(sentence, 0)
decoder_input = [target_lang_tokenizer.word2idx["<SOS>"]]
output = tf.expand_dims(decoder_input, 0)
for i in range(target_lang_tokenizer.max_length):
#
# Greedy Search
#
enc_padding_mask, combined_mask, dec_padding_mask = create_masks(encoder_input, output)
predictions, encoder_attention_weights, decoder_attention_weights = transformer(encoder_input, output, False, enc_padding_mask, combined_mask, dec_padding_mask)
predictions = predictions[:, -1:, :]
predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32)
if target_lang_tokenizer.idx2word[predicted_id.numpy()[0, 0]] == "<EOS>":
return (tf.squeeze(output, axis=0), encoder_attention_weights, decoder_attention_weights)
output = tf.concat([output, predicted_id], axis=-1)
return (tf.squeeze(output, axis=0), encoder_attention_weights, decoder_attention_weights)
def translate(
sentence,
transformer,
source_lang_tokenizer,
target_lang_tokenizer,
encoder_self_attention_plot=None,
decoder_self_attention_plot=None,
decoder_attention_plot=None,
):
result, encoder_attention_weights, decoder_attention_weights = evaluate(
sentence, transformer, source_lang_tokenizer, target_lang_tokenizer
)
result = result.numpy()
predicted_sentence = target_lang_tokenizer.detokenize(result)
if encoder_self_attention_plot is not None:
for i in encoder_self_attention_plot:
plot_attention_weights(
encoder_attention_weights,
lth.preprocess_sentence(sentence, no_tags=True),
source_lang_tokenizer.tokenize(
lth.preprocess_sentence(sentence.lstrip(), no_tags=True)
),
source_lang_tokenizer,
source_lang_tokenizer,
"encoder_layer{}".format(i),
)
if decoder_self_attention_plot is not None:
for i in decoder_self_attention_plot:
plot_attention_weights(
decoder_attention_weights,
lth.preprocess_sentence(
target_lang_tokenizer.detokenize(result).lstrip()
),
result,
target_lang_tokenizer,
target_lang_tokenizer,
"decoder_layer{}_block1".format(i),
)
if decoder_attention_plot is not None:
for i in decoder_attention_plot:
plot_attention_weights(
decoder_attention_weights,
lth.preprocess_sentence(sentence, no_tags=True),
result,
source_lang_tokenizer,
target_lang_tokenizer,
"decoder_layer{}_block2".format(i),
)
return predicted_sentenceThis implementation enables the visualization of attention weights for multi-head attention layers within the model.
For example, setting $\text{the encoder_self_attention_plot}$ parameter to a list of layer indices, like $[1, 2, 4]$, will display the attention weight maps for the first, second, and fourth layers of the encoder.
Similarly, the $\text{decoder_self_attention_plot}$ parameter will display the self-attention weight maps of the decoder.
The $\text{decoder_attention_plot}$, on the other hand, enables the visualization of the (source-target) attention weights between the encoder and the decoder’s output.
keys = np.arange(len(source_tensor_val))
keys = np.random.permutation(keys)[:10]
for i in range(len(keys)):
print("===== [{}] ======".format(i + 1))
sentence = source_lang_tokenizer.detokenize(source_tensor_val[i], with_pad=False)
result = translate(
sentence,
transformer,
source_lang_tokenizer,
target_lang_tokenizer,
encoder_self_attention_plot=[1, 2],
decoder_self_attention_plot=[1],
decoder_attention_plot=[1],
)
print("Input : {}".format(sentence))
print("Predicted: {}".format(result))
print("Correct : {}".format(target_lang_tokenizer.detokenize(target_tensor_val[i], with_pad=False)))16.3.1. Demonstration
Following 14 epochs of training (which included 4 additional epochs after an initial 10 epochs), here are some examples of our model’s translation outputs:
$ python Transformer-tf.py
===== [1] ======
Input : ¿ de quien es esa carta ?
Predicted: whose letter is that ?
Correct : whose letter is this ?
===== [2] ======
Input : no habia nada en juego.
Predicted: there was nothing in the future.
Correct : there was nothing at stake.
===== [3] ======
Input : tom podria haber ganado si hubiera querido.
Predicted: tom should've heard that he could get more and more.
Correct : tom could've won if he'd wanted to.
===== [4] ======
Input : ¿ le gustaria ensenarme a jugar al ajedrez ?
Predicted: would you like me to teach you how to play chess ?
Correct : would you like me to teach you how to play chess ?
===== [5] ======
Input : se mas flexible.
Predicted: be more confident.
Correct : be more flexible.
===== [6] ======
Input : no pueden pararme.
Predicted: you can't stop me.
Correct : you can't stop me.
===== [7] ======
Input : ¿ de quien es este libro ?
Predicted: whose book is this ?
Correct : whose book is this ?
===== [8] ======
Input : tom tiene otros tres perros.
Predicted: tom has three dogs.
Correct : tom has three other dogs.
===== [9] ======
Input : ¿ que tan largo es ese puente ?
Predicted: how long is that bridge ?
Correct : how long is that bridge ?
===== [10] ======
Input : me gustaria oir que tienes que decir sobre esto.
Predicted: i'd like to hear what you have to say about this.
Correct : i'd like to hear what you have to say on this.This code contains the checkpoint function that preserves the training progress. Hence, once trained, the task can be executed without retraining by setting the parameter $\text{n_epochs}$ to $0$, or simply passing $0$ when executing the Python code, as shown below:
$ python Transformer-tf.py 0At first glance, the translation results are highly accurate.
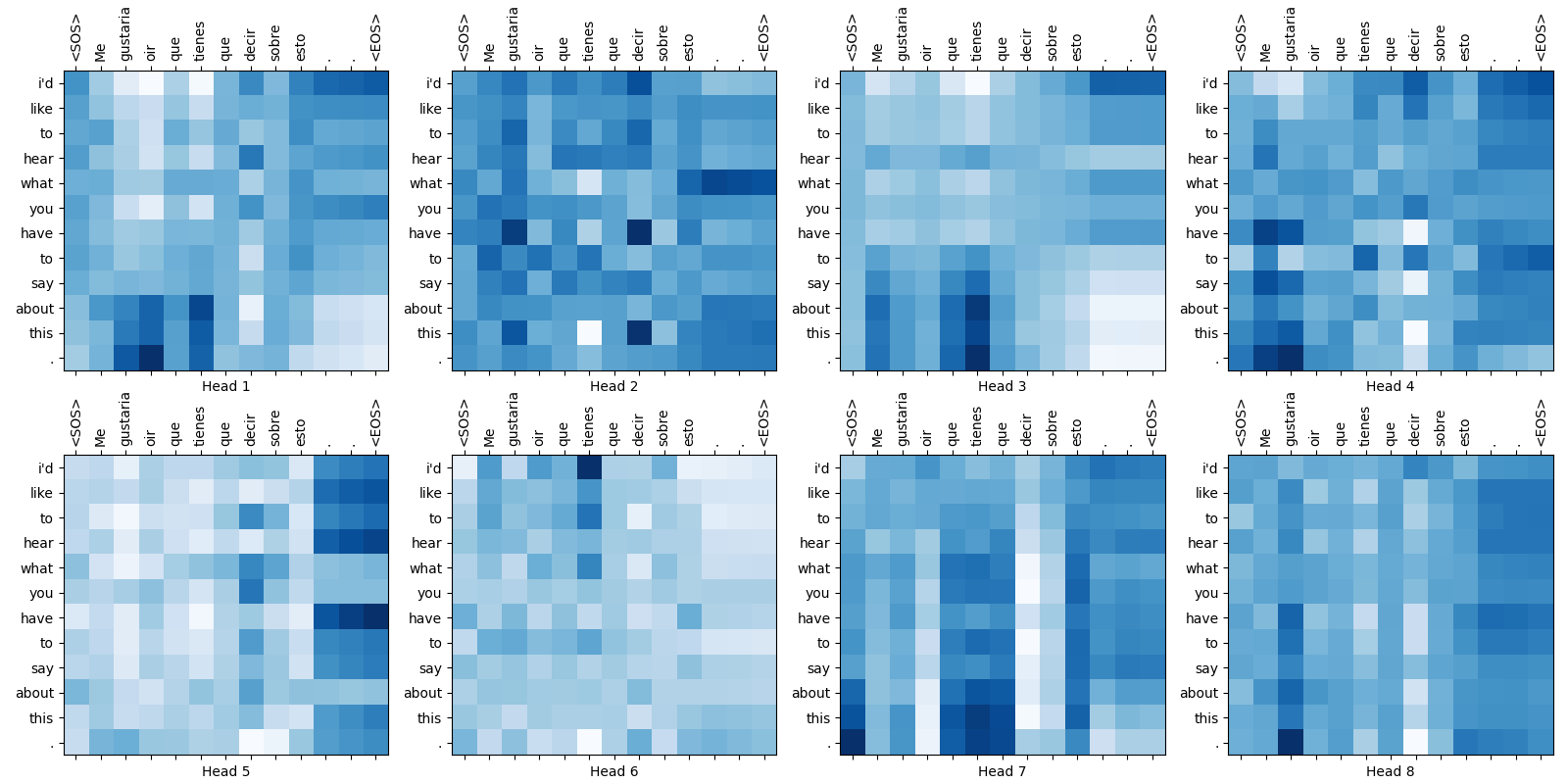
Some attention weight maps are shown below:
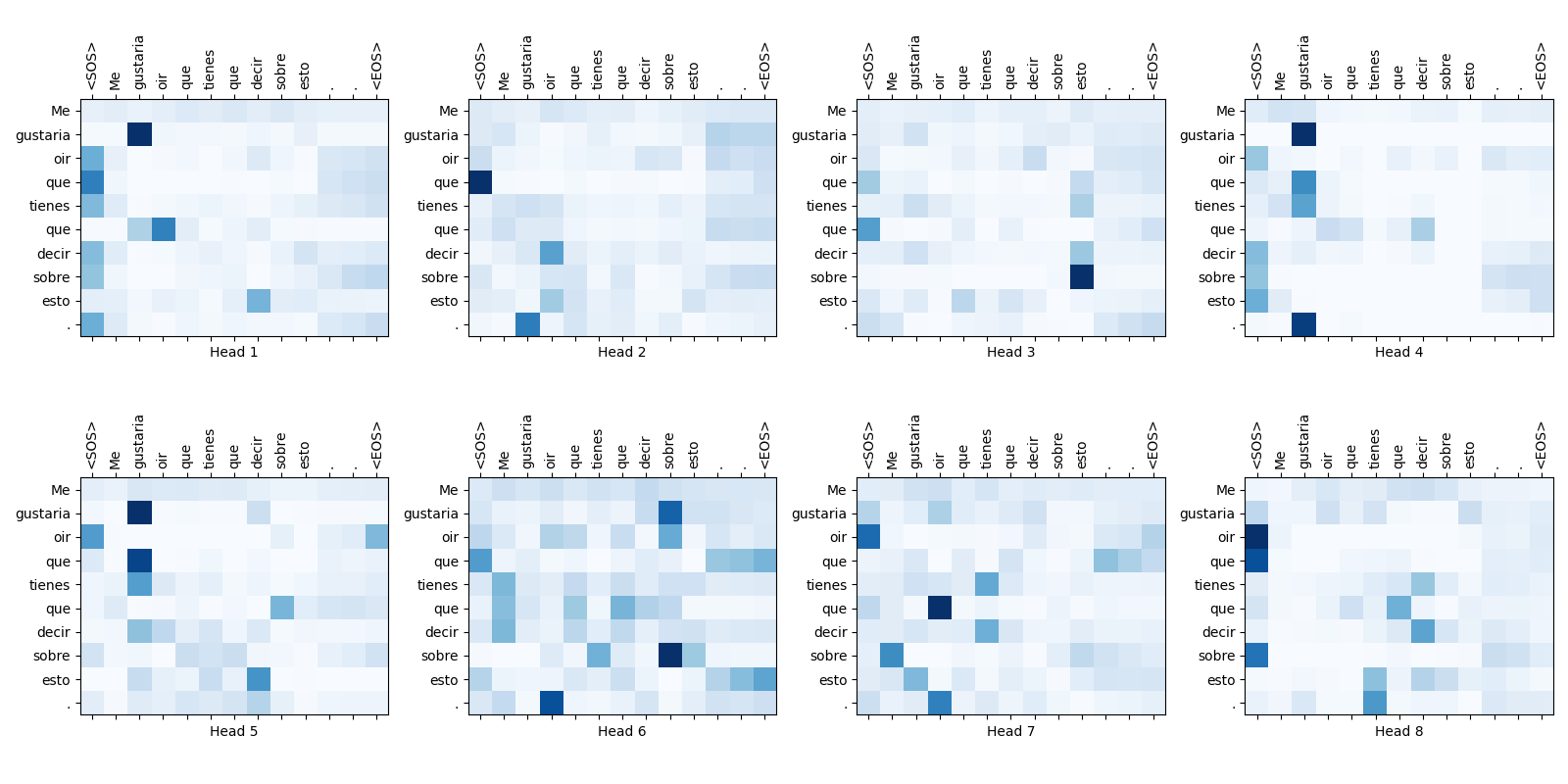
Fig.16-4: Self-Attention Weight Maps for the 1st Layer of Encoder
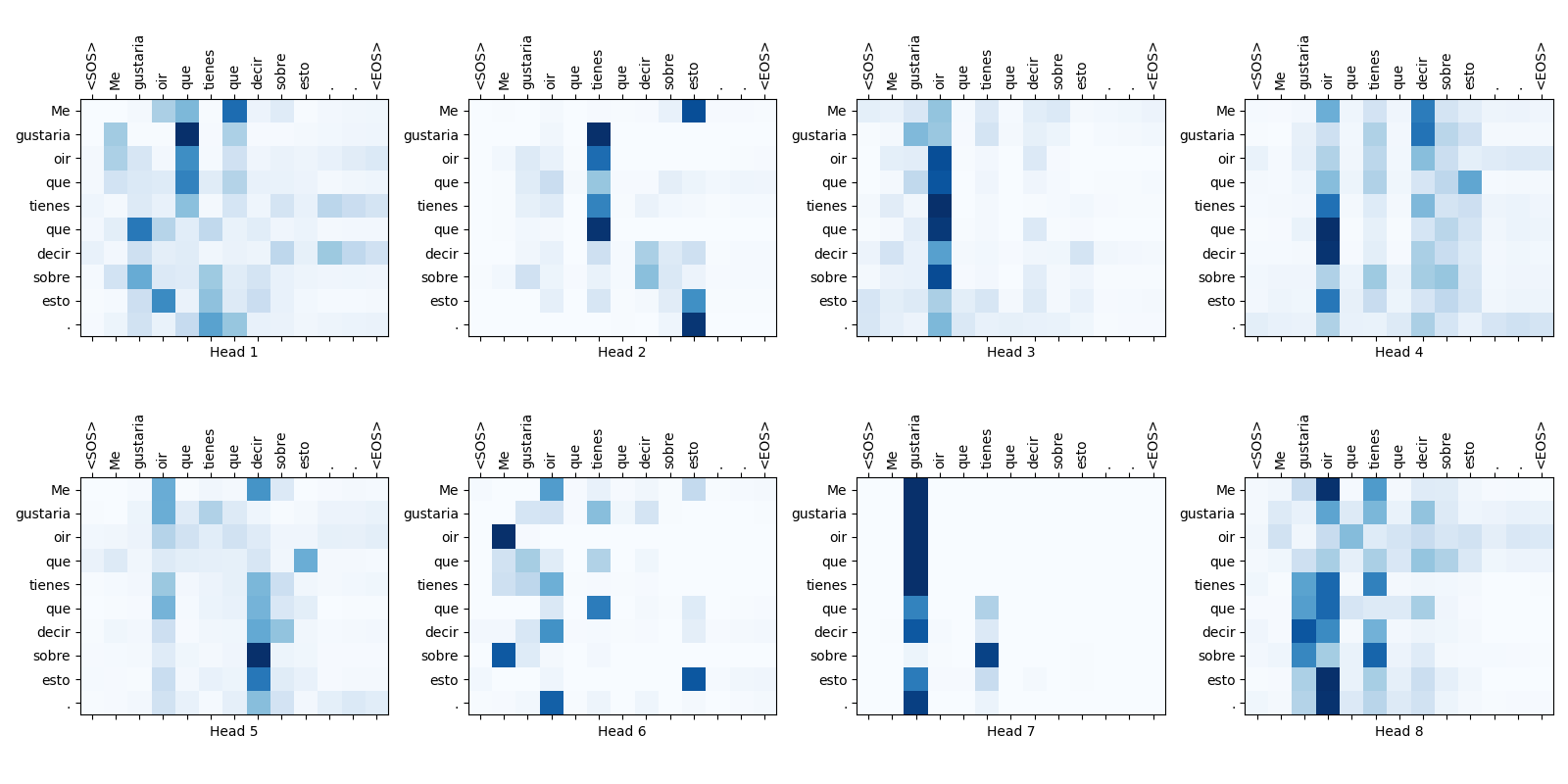
Fig.16-5: Self-Attention Weight Maps for the 2nd Layer of Encoder
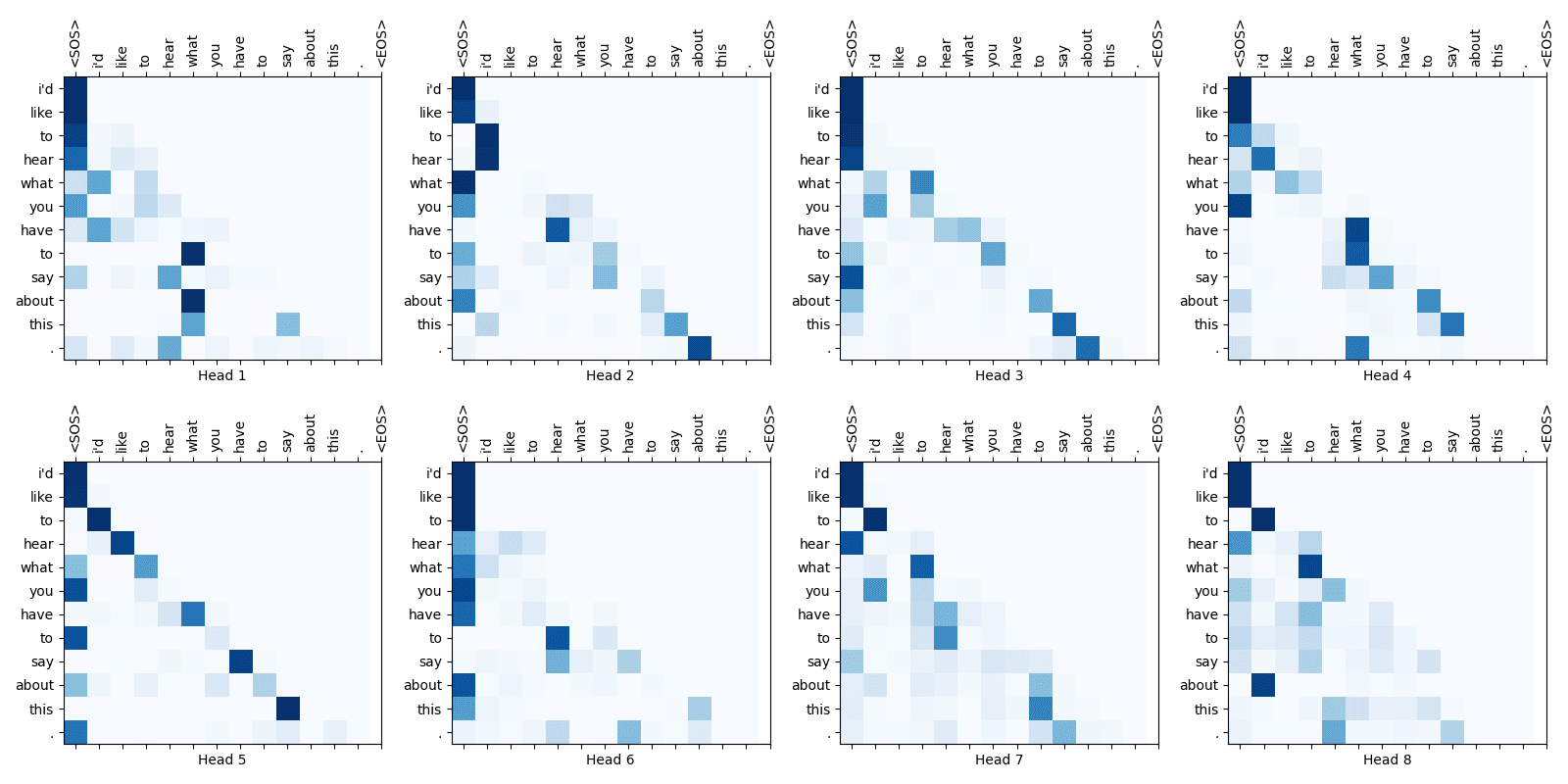
Fig.16-6: Self-Attention Weight Maps for the 1st Layer of Decoder
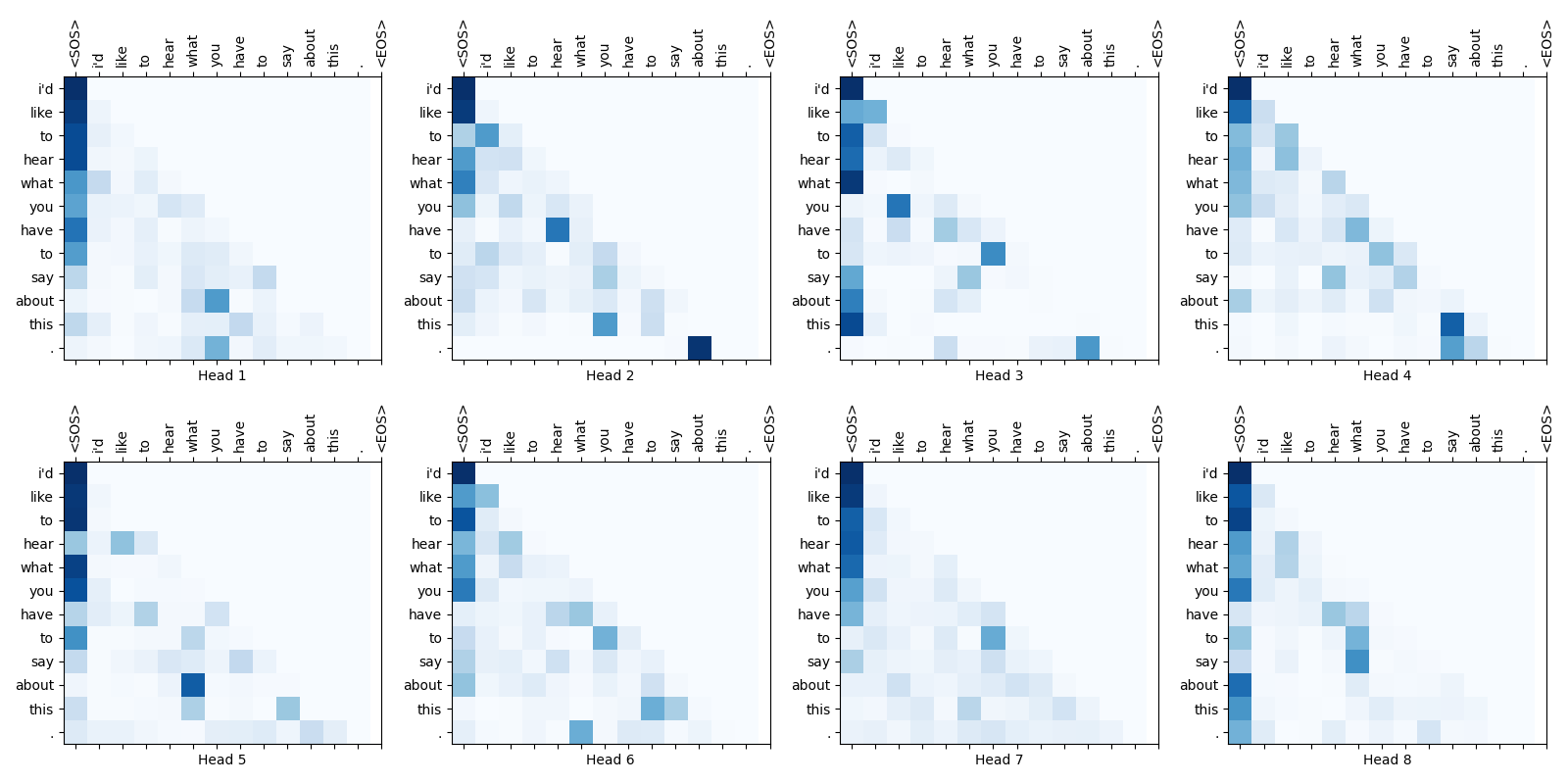
Fig.16-7: Self-Attention Weight Maps for the 2nd Layer of Decoder
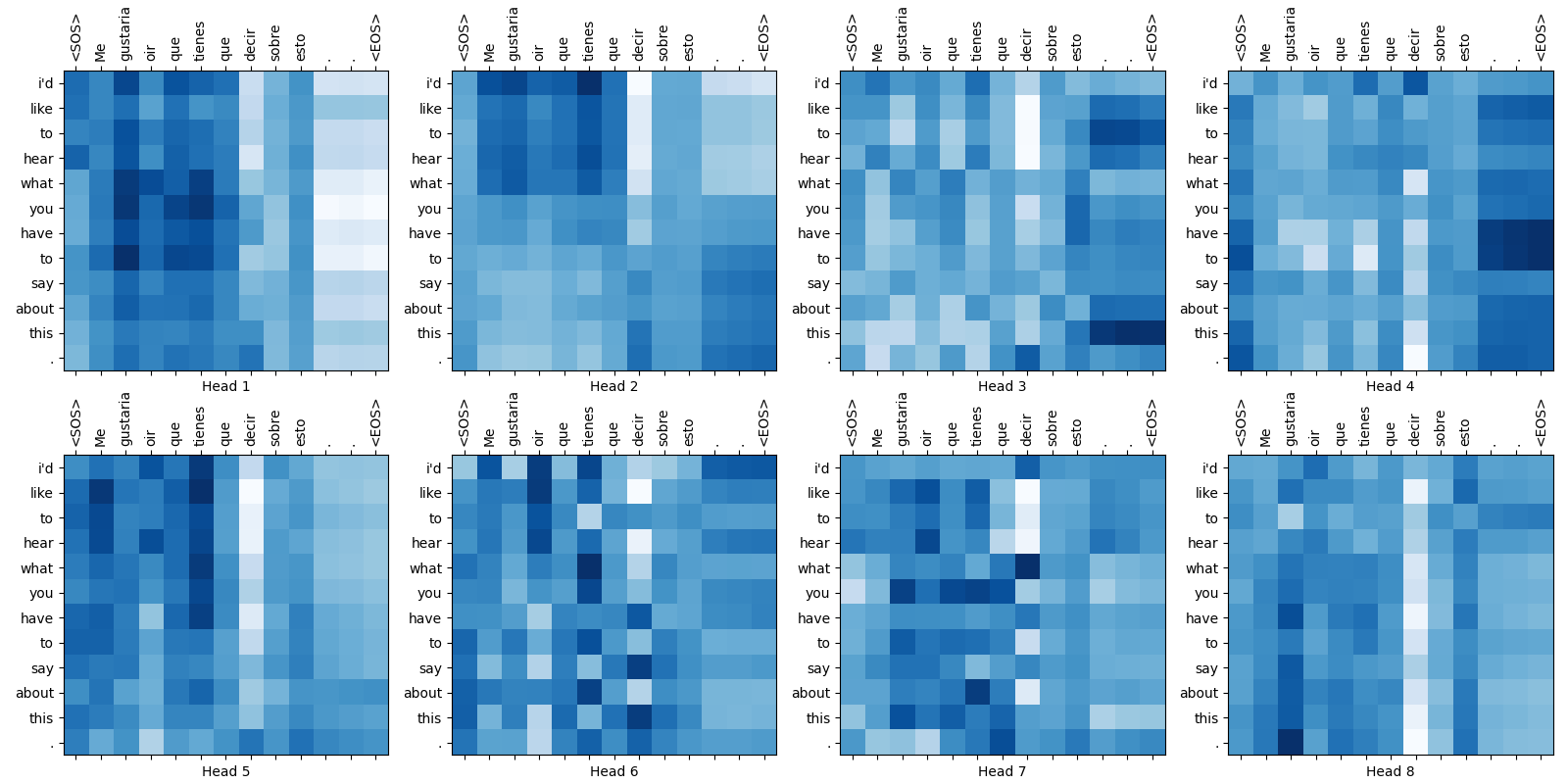
Fig.16-8: Attention Weight Maps for the 1st Layer of Encoder-Decoder