15.3. Position-Wise Feed-Forward Network
The Transformer model employs a position-wise feed-forward network (FFN), a two-layer fully connected neural network that processes each element of the input sequence independently.
The mathematical definition of the FFN is:
$$ \text{FFN}(x) = \text{LeRU} (x W_{1} + b_{1}) W_{2} + b_{2} $$where:
- $x \in \mathbb{R}^{N \times d_{model}}$ is an input sequence matrix.
- $W_{1} \in \mathbb{R}^{d_{model} \times d_{\text{ffn}}} $ and $W_{2} \in \mathbb{R}^{d_{\text{ffn}} \times d_{\text{model}} } $ are weights.
- $b_{1} \in \mathbb{R}^{d_{\text{ffn}}} $ and $b_{2} \in \mathbb{R}^{d_{\text{model}}} $ are biases.
This layer is called “position-wise” because, the Transformer processes input sequences {$x_{0}, x_{1},\ldots, x_{N-1}$} in parallel, but the FFN operates on each individual input vector $x_{i}$ independently.
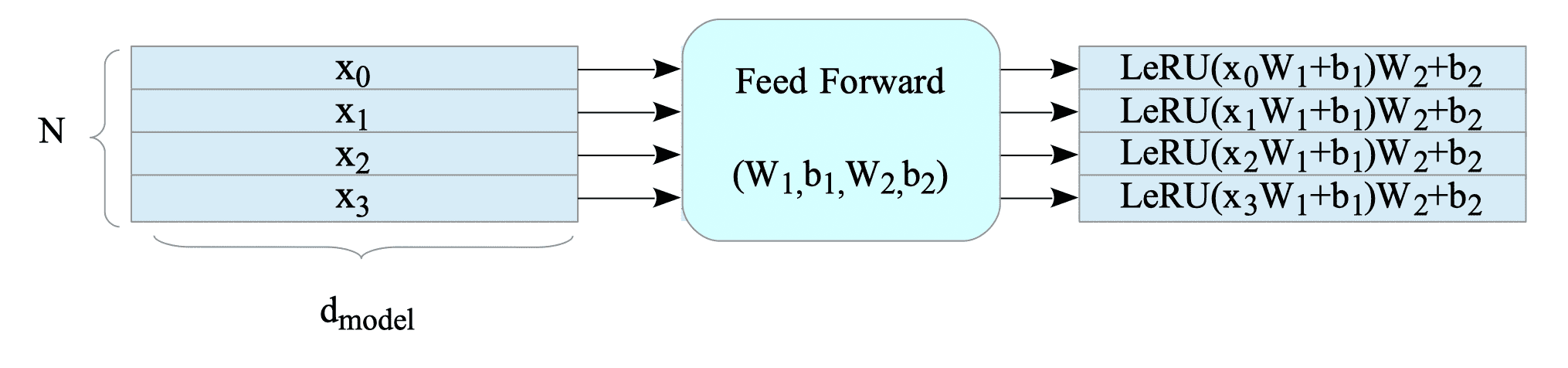
Fig.15-10: Position-Wise Feed-Forward Network
Here is a Python implementation using TensorFlow:
#
# point-wise feed forward network
#
def point_wise_feed_forward_network(d_model, d_ffn):
return tf.keras.Sequential(
[
tf.keras.layers.Dense(d_ffn, activation="relu"),
tf.keras.layers.Dense(d_model),
]
)