3. Activation Functions
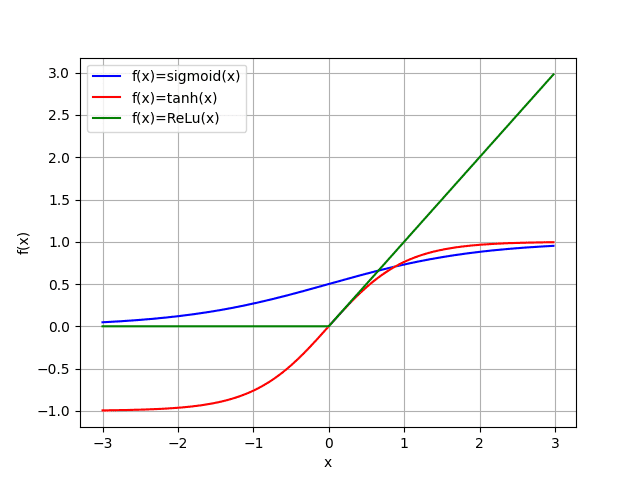
Previously, we used activation functions without explanation. This chapter now dives into common activation functions used in neural networks.
All functions explained here are implemented in the file: ActivationFunctions.py
3.1. Activation Functions for Hidden Layer
3.1.1. Sigmoid
The sigmoid function outputs a value between $0$ and $1$.
$$ \text{sigmoid}(x) = \sigma(x) = \frac{1}{1 + \exp(-x)} $$ $$ \sigma'(x) = \frac{d \sigma(x)}{dx} = \sigma(x)(1 - \sigma(x)) = \frac{1}{1 + \exp(-x)} \left( 1 - \frac{1}{1 + \exp(-x)} \right) $$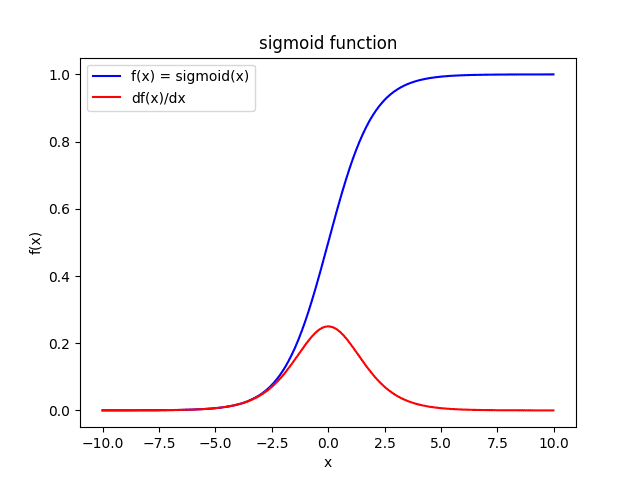
Pros:
- The sigmoid function introduces non-linearity into the neural network, which can help it learn complex patterns.
- It can be used in classification tasks and logistic regression tasks.
Cons:
- While the sigmoid function can be used for general regression tasks, other activation functions like ReLU or linear activations are more common choices.
- It can lead to the vanishing gradient problem, which makes it difficult for the neural network to learn.
3.1.2. Tanh
The tanh function is similar to the sigmoid activation function, but it outputs a value between $-1$ and $1$.
$$ \tanh(x) = \frac{\exp(x) - \exp(-x)}{\exp(x) + \exp(-x)} $$ $$ \tanh'(x) = \frac{d \tanh(x)}{dx} = (1 - \tanh(x)^{2}) $$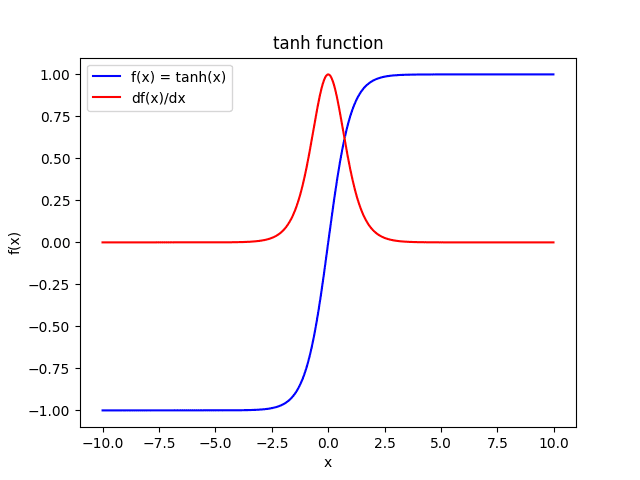
Pros:
- The tanh activation function introduces non-linearity into the neural network, which can help it to learn complex patterns.
- It can be used in classification tasks and logistic regression tasks.
- It is less prone to the vanishing gradient problem than the sigmoid function.
Cons:
- Although less common than with sigmoid, the vanishing gradient problem can still occur with the tanh function.
- While the tanh function can be used for general regression tasks, other activation functions like ReLU or linear activations are more common choices.
3.1.3. Linear function
The linear activation function is simply the identity function, which means that the output of the function is the same as the input.
$$ \text{linear}(x) = x $$ $$ \text{linear}'(x) = \frac{d \ \text{linear}(x)}{dx} = 1 $$Pros:
- The linear activation function can be used in regression tasks, where the goal is to predict a continuous value.
Cons:
- The linear activation function can not be used in classification tasks.
3.1.4. ReLU (Rectified Linear Unit)
The ReLU activation function outputs the input value if it is positive, and $0$ otherwise. It is a popular activation function for neural networks because it is computationally efficient and avoids the exploding and vanishing gradient problems, which will be explained in the next chapter.
ReLU has many variations such as Leaky RelU, PReLU(Parametric ReLU) and RReLU(Randomized ReLU).
$$ \text{ReLU}(x) = \begin{cases} x & x > 0 \\ 0 & x \leqq 0 \end{cases} $$ $$ \text{ReLU}'(x) = \frac{d \ \text{ReLU}(x)}{dx}= \begin{cases} 1 & x > 0 \\ 0 & x \leqq 0 \end{cases} $$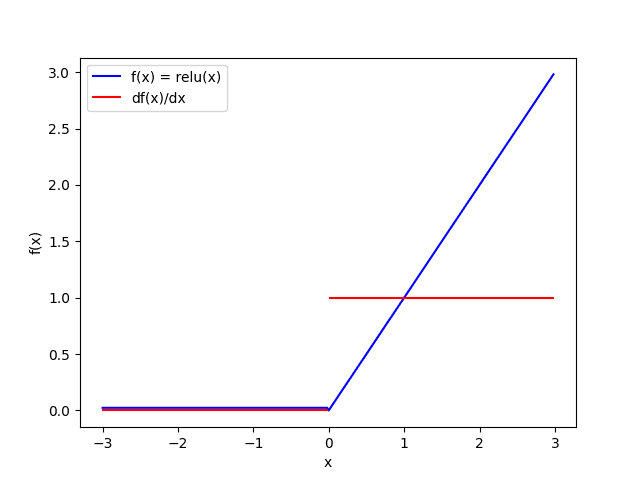
Pros:
- The ReLU activation function avoids the exploding and vanishing gradient problems.
- It can be used in both regression and classification tasks.
Cons:
- The ReLU activation function can introduce the dying ReLU problem.
This is an explanation of the dying ReLU problem by claude.ai:
The dying ReLU problem refers to a situation where a significant number of neurons in a neural network become inactive (output zero) when using the ReLU activation function during the training process.
This happens when the neurons receive a negative input, causing their output to become zero, and consequently, the neurons stop learning or contributing to the model’s output.
The dying ReLU problem can lead to ineffective training and poor performance of the neural network.
3.2. Activation Functions for Output Layer
3.2.1. Sigmoid, Tanh and Linear
These activation functions can be used in the output layer.
3.2.2. Softmax
The softmax activation function is often used in the output layer of a neural network for classification tasks. It outputs a vector of probabilities, where each probability represents the likelihood of the input belonging to a particular class.
Obviously, the softmax activation function cannot be used in regression tasks.
Definition:
The softmax function is defined as:
$$ y_{i} = \frac{ \exp(x_{i}) }{ \sum^{K-1}_{k=0} \exp(x_{k}) } $$where:
- $K \in \mathbb{N}$ is the number of category.
- $y_{i}$ is the $i$-th element of the output vector $y \in \mathbb{R}^{K}$.
- $x_{i}$ is the $i$-th element of the input vector $x \in \mathbb{R}^{K}$.
The following relations are satisfied:
$$ \begin{cases} \begin{align} \forall \ y_{i}, \ 0 \le y_{i} \le 1 \\ \sum_{i=0}^{K-1} y_{i} = 1 \end{align} \end{cases} $$Example:
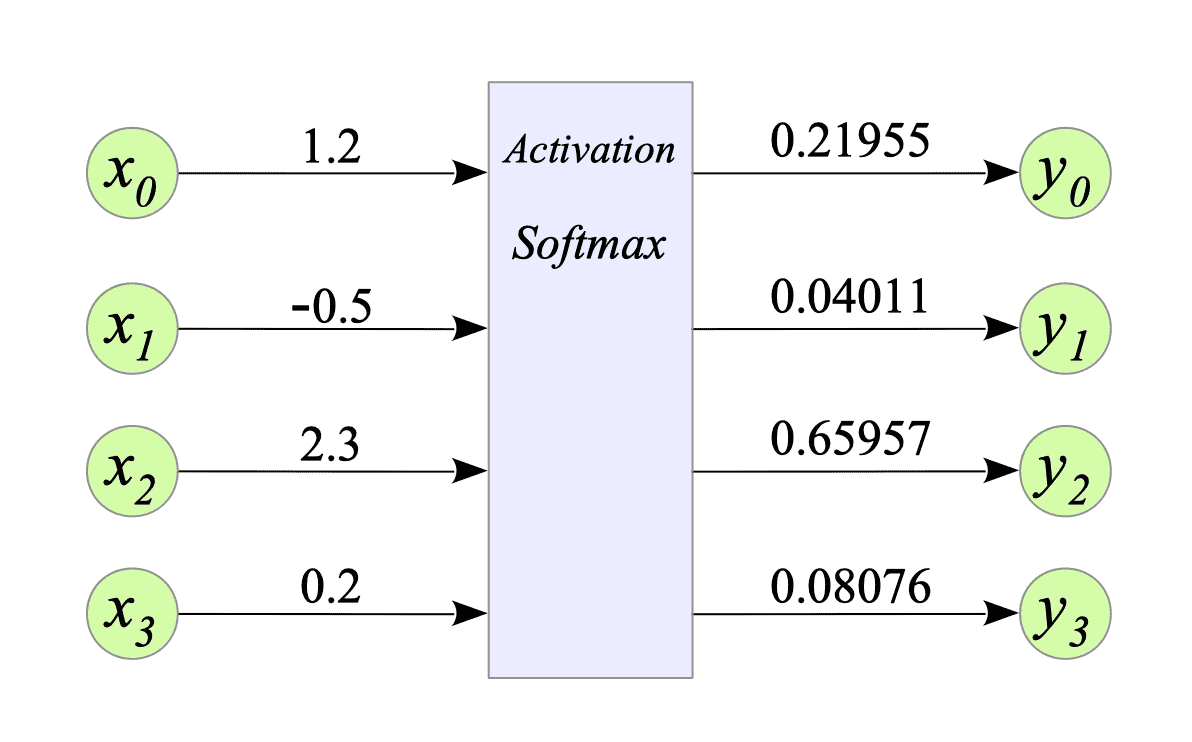
Given the number of category $K = 4$, the input vector $x = [1.2, -0.5, 2.3, 0.2]$. Then, the output of the softmax function is $y = [0.21955, 0.04011, 0.65957, 0.08076]$.
Use cases:
The softmax activation function can be used in classification tasks, such as image classification and natural language processing.