10. Dataset and Tokenizer
Computers cannot understand natural language directly, so we must convert text data into numerical representations for processing.
Fig.10-1 illustrates an example of how language data is represented in the n-gram language model.
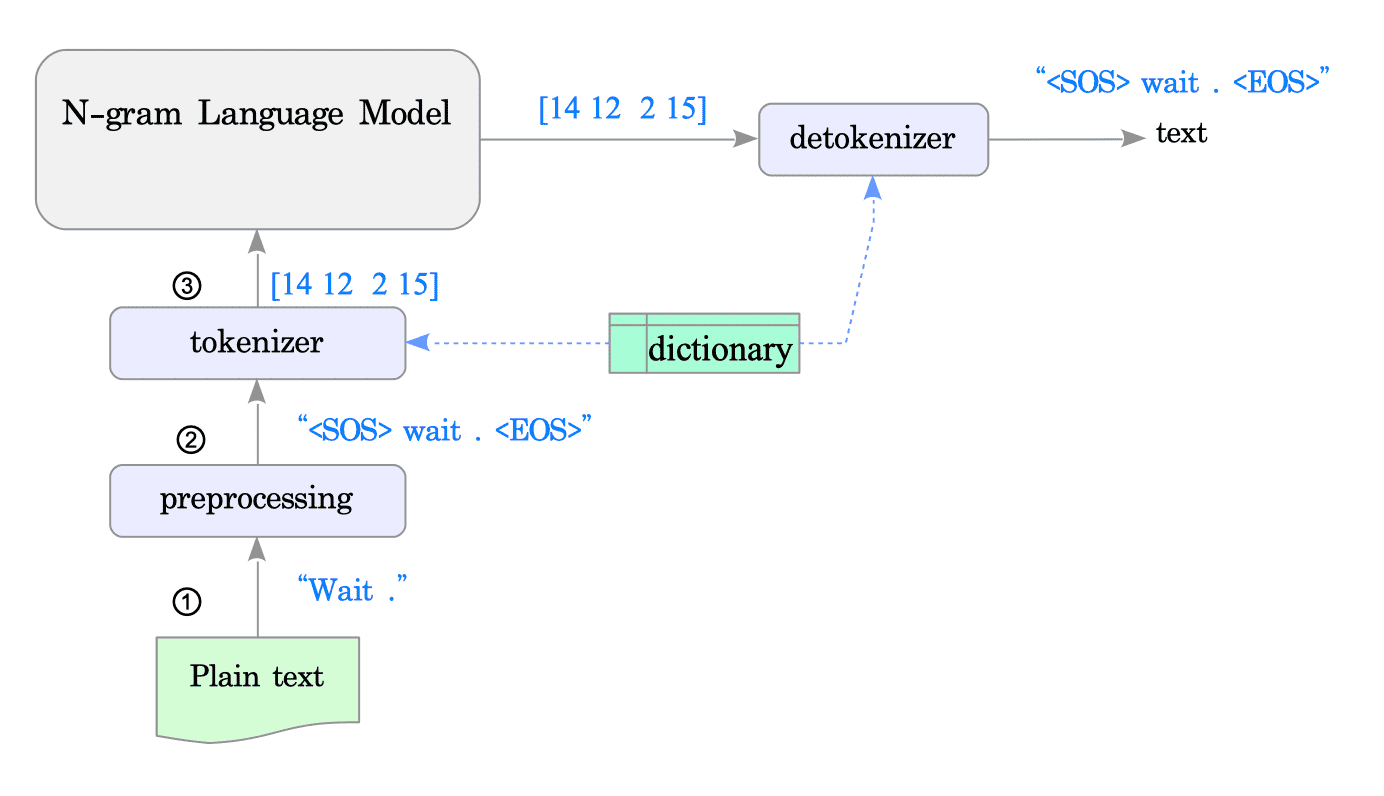
Fig.10-1: Typical Language Data Representations in n-gram Language Models
-
Plain text: The primary data used in language models is plain text, which consists of unformatted human-written language.
-
Preprocessed data: The plain text is preprocessed, such as converting all characters to lowercase and inserting special characters (<SOS> = start of sentence; <EOS> = end of sentence) before and after the text.
-
Tokenized data: The preprocessed data is converted into a list of tokens, which are individual elements like words, punctuation marks, or symbols. Each token is then assigned a unique number based on its position in a dictionary.
N-gram language models rely internally on these integer representations of tokens.
In contrast, RNN-based models leverage vectors for their internal processing. This embedding technique is commonly referred to as word embedding.
Fig.10-2 illustrates an example of how language data is represented in the RNN-based language model.
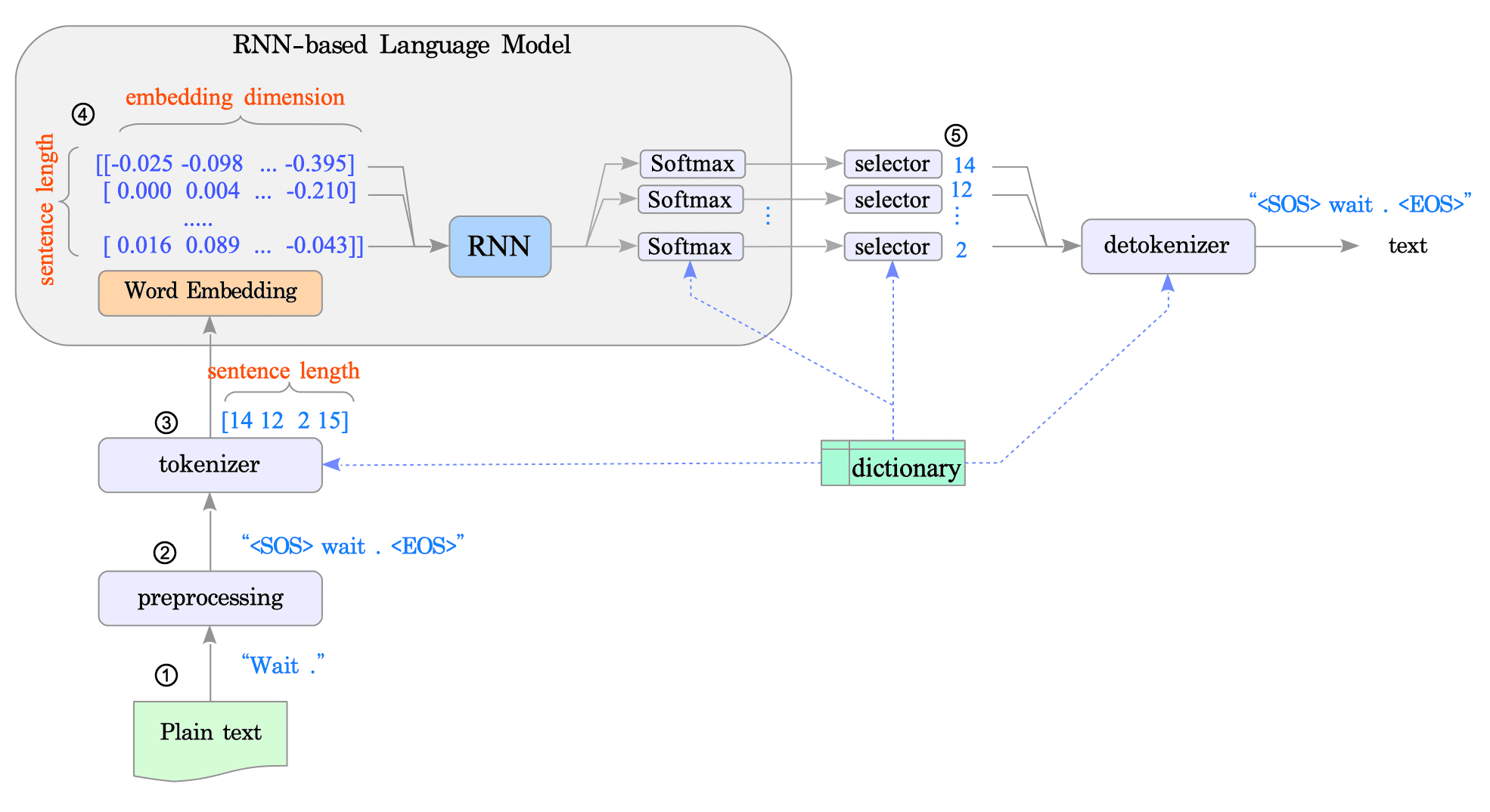
Fig.10-2: Typical Language Data Representations in RNN-Based Language Models
-
Word embedding data: Each token in a sequence is transformed into a vector. This process converts the entire sequence into a matrix, where each row represents a token and its vector, and the number of columns reflects the size of the vector (embedding dimension).
-
Word embedding data $\Rightarrow$ Tokenized data: The RNN model utilizes a softmax layer to generate an output vector1. This vector holds probabilities for each token in the vocabulary (essentially, the dictionary). We typically choose the token with the highest probability, indicated by the index with the largest value in the vector, as it aligns with the corresponding token in the dictionary.
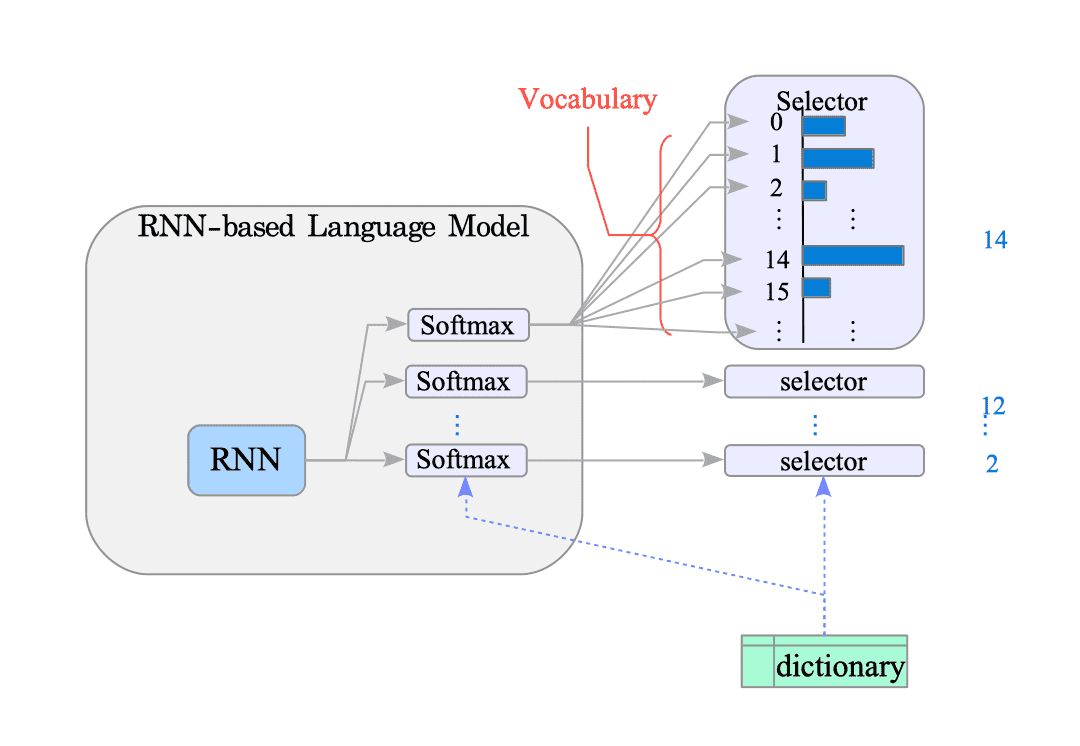
The subsequent sections elaborate on the following topics:
-
Remember, this isn’t the embedding vector. The output vector’s size matches the dictionary, not the word embedding dimension. ↩︎