10.3. Word Embedding
In natural language processing (NLP), word embedding is a technique for representing words as vectors. This process transforms positive integers (indexes) into dense vectors of a fixed size.
Among the many embedding methods available, we will use Keras’s Embedding method, which randomly initializes these vectors without relying on statistical information.
Note
Let’s see a concrete example using the Python code: embedding_sample.py.
import tensorflow as tf
from tensorflow.keras import layers
target_sentences = [14, 12, 2, 15, 0] # <SOS> Wait. <EOS> <pad>
embedding_dim = 3
embedding_layer = layers.Embedding(max(target_sentences) + 1, embedding_dim)
for i in range(len(target_sentences)):
result = embedding_layer(tf.constant(target_sentences[i])).numpy()
print("{:>10} => {}".format(target_sentences[i], result))As shown below, the target sentence is encoded into 3-dimensional vectors:
$ python embedding_sample.py
14 => [-0.04156573 0.00206254 0.00734914]
12 => [ 0.04501722 0.03781917 -0.0214412 ]
2 => [ 0.02111651 -0.04967414 0.00520502]
15 => [-0.04644718 -0.02823651 0.02287232]
0 => [ 0.01632792 0.04234136 0.02328513]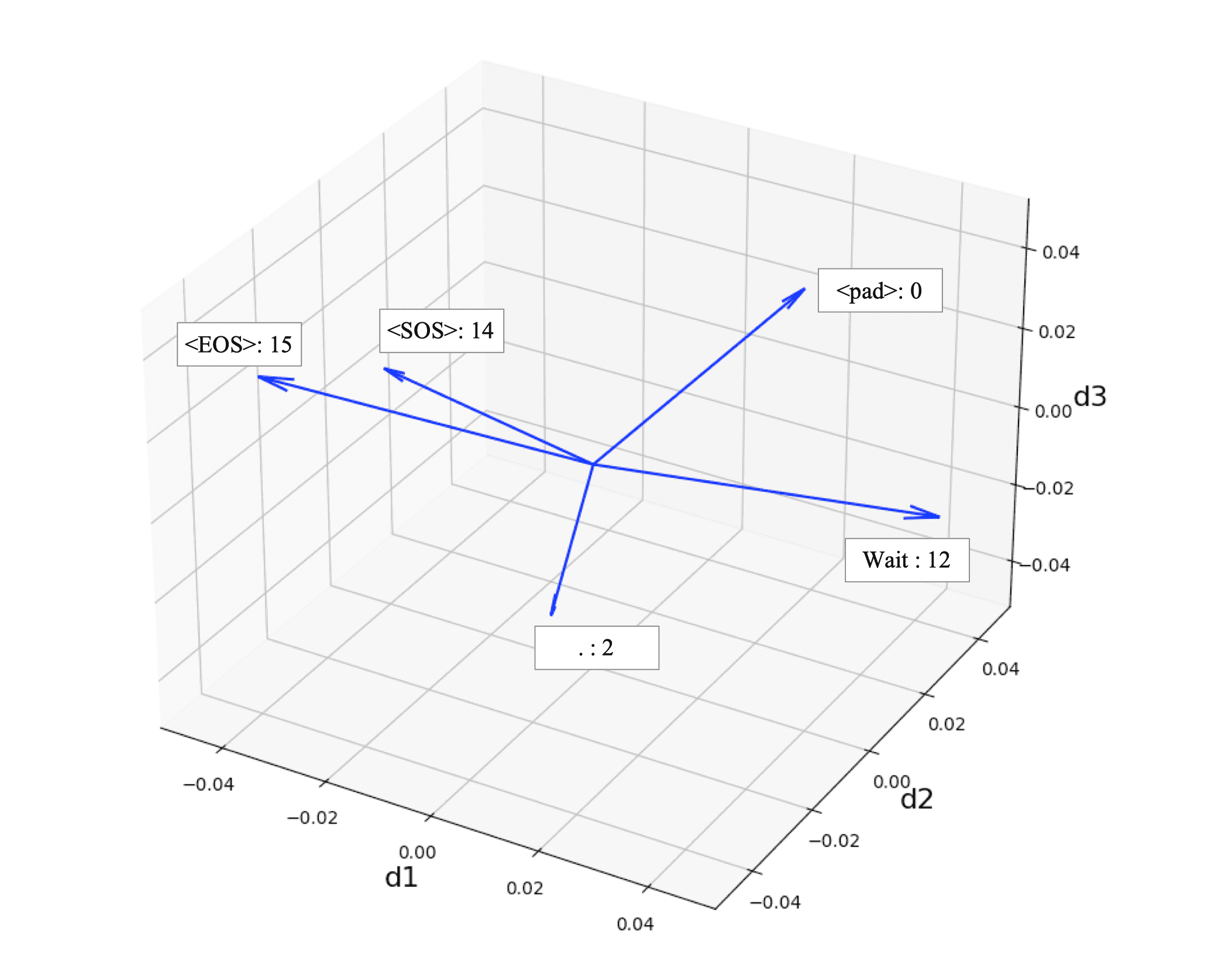
While NLP embeddings usually have higher dimensions like 256 or 512, they can effectively represent words in a much smaller space compared to one-hot encoding.